 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSTaR-KV: Spatio-Temporal Adaptive Re-weighting for KV Cache Compression in GUI Vision-Language Models
Jun 01, 2026Vision-language-model-based graphical user interface (GUI) agents have shown broad automation capabilities, yet deployment is bottlenecked by a key-value (KV) cache that grows linearly with interaction steps. For instance, UI-TARS-1.5-7B consumes 76 GB of GPU memory on merely five screenshots, approaching the capacity of mainstream 80 GB accelerators. Existing KV compression methods share two structural assumptions: aggregating visual-token importance into a single shared saliency map, and applying a fixed top-B cutoff to the fused score distribution. Pilot measurements refute both: spatial specialization lives at the attention-subspace level and migrates across layers, while the score distribution drifts in shape along a trajectory. We propose STaR-KV (Spatio-Temporal Adaptive Re-weighting), a training-free KV cache compression framework that calibrates token importance along three axes: (i) subspace-aware scoring driven by online spatial mutual information; (ii) a temporal stability discount that suppresses redundant cache entries from persistently attended subspaces; and (iii) an entropy-derived temperature that adaptively reshapes the score distribution. Across four GUI benchmarks, STaR-KV achieves the strongest average accuracy among state-of-the-art KV compression methods (e.g., GUIKV, SnapKV) at matched budgets, with no compression-stage FLOPs overhead (-0.07%) and cutting peak GPU memory by nearly 40% at a 20% KV-cache budget. Code is available at https://github.com/kawhiiiileo/STaR-KV.
Stability Implies Redundancy: Delta Attention Selective Halting for Efficient Long-Context Prefilling
Apr 20, 2026Prefilling computational costs pose a significant bottleneck for Large Language Models (LLMs) and Large Multimodal Models (LMMs) in long-context settings. While token pruning reduces sequence length, prior methods rely on heuristics that break compatibility with hardware-efficient kernels like FlashAttention. In this work, we observe that tokens evolve toward \textit{semantic fixing points}, making further processing redundant. To this end, we introduce Delta Attention Selective Halting (DASH), a training-free policy that monitors the layer-wise update dynamics of the self-attention mechanism to selectively halt stabilized tokens. Extensive evaluation confirms that DASH generalizes across language and vision benchmarks, delivering significant prefill speedups while preserving model accuracy and hardware efficiency. Code will be released at https://github.com/verach3n/DASH.git.
PuriLight: A Lightweight Shuffle and Purification Framework for Monocular Depth Estimation
Feb 11, 2026We propose PuriLight, a lightweight and efficient framework for self-supervised monocular depth estimation, to address the dual challenges of computational efficiency and detail preservation. While recent advances in self-supervised depth estimation have reduced reliance on ground truth supervision, existing approaches remain constrained by either bulky architectures compromising practicality or lightweight models sacrificing structural precision. These dual limitations underscore the critical need to develop lightweight yet structurally precise architectures. Our framework addresses these limitations through a three-stage architecture incorporating three novel modules: the Shuffle-Dilation Convolution (SDC) module for local feature extraction, the Rotation-Adaptive Kernel Attention (RAKA) module for hierarchical feature enhancement, and the Deep Frequency Signal Purification (DFSP) module for global feature purification. Through effective collaboration, these modules enable PuriLight to achieve both lightweight and accurate feature extraction and processing. Extensive experiments demonstrate that PuriLight achieves state-of-the-art performance with minimal training parameters while maintaining exceptional computational efficiency. Codes will be available at https://github.com/ishrouder/PuriLight.
Kimi K2.5: Visual Agentic Intelligence
Feb 02, 2026We introduce Kimi K2.5, an open-source multimodal agentic model designed to advance general agentic intelligence. K2.5 emphasizes the joint optimization of text and vision so that two modalities enhance each other. This includes a series of techniques such as joint text-vision pre-training, zero-vision SFT, and joint text-vision reinforcement learning. Building on this multimodal foundation, K2.5 introduces Agent Swarm, a self-directed parallel agent orchestration framework that dynamically decomposes complex tasks into heterogeneous sub-problems and executes them concurrently. Extensive evaluations show that Kimi K2.5 achieves state-of-the-art results across various domains including coding, vision, reasoning, and agentic tasks. Agent Swarm also reduces latency by up to $4.5\times$ over single-agent baselines. We release the post-trained Kimi K2.5 model checkpoint to facilitate future research and real-world applications of agentic intelligence.
Unifying Speech Editing Detection and Content Localization via Prior-Enhanced Audio LLMs
Jan 29, 2026Speech editing achieves semantic inversion by performing fine-grained segment-level manipulation on original utterances, while preserving global perceptual naturalness. Existing detection studies mainly focus on manually edited speech with explicit splicing artifacts, and therefore struggle to cope with emerging end-to-end neural speech editing techniques that generate seamless acoustic transitions. To address this challenge, we first construct a large-scale bilingual dataset, AiEdit, which leverages large language models to drive precise semantic tampering logic and employs multiple advanced neural speech editing methods for data synthesis, thereby filling the gap of high-quality speech editing datasets. Building upon this foundation, we propose PELM (Prior-Enhanced Audio Large Language Model), the first large-model framework that unifies speech editing detection and content localization by formulating them as an audio question answering task. To mitigate the inherent forgery bias and semantic-priority bias observed in existing audio large models, PELM incorporates word-level probability priors to provide explicit acoustic cues, and further designs a centroid-aggregation-based acoustic consistency perception loss to explicitly enforce the modeling of subtle local distribution anomalies. Extensive experimental results demonstrate that PELM significantly outperforms state-of-the-art methods on both the HumanEdit and AiEdit datasets, achieving equal error rates (EER) of 0.57\% and 9.28\% (localization), respectively.
WorldVQA: Measuring Atomic World Knowledge in Multimodal Large Language Models
Jan 28, 2026We introduce WorldVQA, a benchmark designed to evaluate the atomic visual world knowledge of Multimodal Large Language Models (MLLMs). Unlike current evaluations, which often conflate visual knowledge retrieval with reasoning, WorldVQA decouples these capabilities to strictly measure "what the model memorizes." The benchmark assesses the atomic capability of grounding and naming visual entities across a stratified taxonomy, spanning from common head-class objects to long-tail rarities. We expect WorldVQA to serve as a rigorous test for visual factuality, thereby establishing a standard for assessing the encyclopedic breadth and hallucination rates of current and next-generation frontier models.
Mitigating Audiovisual Mismatch in Visual-Guide Audio Captioning
May 28, 2025Current vision-guided audio captioning systems frequently fail to address audiovisual misalignment in real-world scenarios, such as dubbed content or off-screen sounds. To bridge this critical gap, we present an entropy-aware gated fusion framework that dynamically modulates visual information flow through cross-modal uncertainty quantification. Our novel approach employs attention entropy analysis in cross-attention layers to automatically identify and suppress misleading visual cues during modal fusion. Complementing this architecture, we develop a batch-wise audiovisual shuffling technique that generates synthetic mismatched training pairs, greatly enhancing model resilience against alignment noise. Evaluations on the AudioCaps benchmark demonstrate our system's superior performance over existing baselines, especially in mismatched modality scenarios. Furthermore, our solution demonstrates an approximately 6x improvement in inference speed compared to the baseline.
Hearing from Silence: Reasoning Audio Descriptions from Silent Videos via Vision-Language Model
May 19, 2025Humans can intuitively infer sounds from silent videos, but whether multimodal large language models can perform modal-mismatch reasoning without accessing target modalities remains relatively unexplored. Current text-assisted-video-to-audio (VT2A) methods excel in video foley tasks but struggle to acquire audio descriptions during inference. We introduce the task of Reasoning Audio Descriptions from Silent Videos (SVAD) to address this challenge and investigate vision-language models' (VLMs) capabilities on this task. To further enhance the VLMs' reasoning capacity for the SVAD task, we construct a CoT-AudioCaps dataset and propose a Chain-of-Thought-based supervised fine-tuning strategy. Experiments on SVAD and subsequent VT2A tasks demonstrate our method's effectiveness in two key aspects: significantly improving VLMs' modal-mismatch reasoning for SVAD and effectively addressing the challenge of acquiring audio descriptions during VT2A inference.
$\mathcal{A}LLM4ADD$: Unlocking the Capabilities of Audio Large Language Models for Audio Deepfake Detection
May 16, 2025
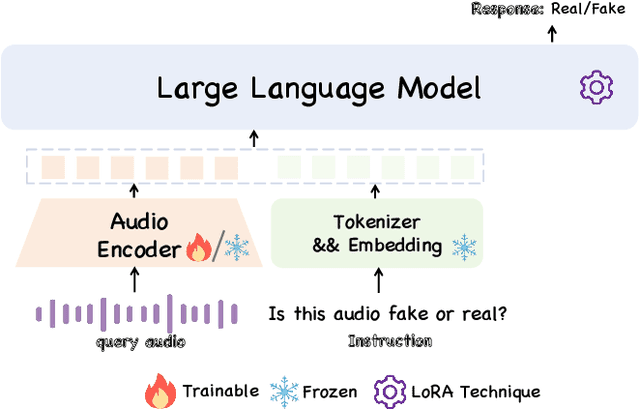

Audio deepfake detection (ADD) has grown increasingly important due to the rise of high-fidelity audio generative models and their potential for misuse. Given that audio large language models (ALLMs) have made significant progress in various audio processing tasks, a heuristic question arises: Can ALLMs be leveraged to solve ADD?. In this paper, we first conduct a comprehensive zero-shot evaluation of ALLMs on ADD, revealing their ineffectiveness in detecting fake audio. To enhance their performance, we propose $\mathcal{A}LLM4ADD$, an ALLM-driven framework for ADD. Specifically, we reformulate ADD task as an audio question answering problem, prompting the model with the question: "Is this audio fake or real?". We then perform supervised fine-tuning to enable the ALLM to assess the authenticity of query audio. Extensive experiments are conducted to demonstrate that our ALLM-based method can achieve superior performance in fake audio detection, particularly in data-scarce scenarios. As a pioneering study, we anticipate that this work will inspire the research community to leverage ALLMs to develop more effective ADD systems.
Q-MambaIR: Accurate Quantized Mamba for Efficient Image Restoration
Mar 27, 2025State-Space Models (SSMs) have attracted considerable attention in Image Restoration (IR) due to their ability to scale linearly sequence length while effectively capturing long-distance dependencies. However, deploying SSMs to edge devices is challenging due to the constraints in memory, computing capacity, and power consumption, underscoring the need for efficient compression strategies. While low-bit quantization is an efficient model compression strategy for reducing size and accelerating IR tasks, SSM suffers substantial performance drops at ultra-low bit-widths (2-4 bits), primarily due to outliers that exacerbate quantization error. To address this challenge, we propose Q-MambaIR, an accurate, efficient, and flexible Quantized Mamba for IR tasks. Specifically, we introduce a Statistical Dynamic-balancing Learnable Scalar (DLS) to dynamically adjust the quantization mapping range, thereby mitigating the peak truncation loss caused by extreme values. Furthermore, we design a Range-floating Flexible Allocator (RFA) with an adaptive threshold to flexibly round values. This approach preserves high-frequency details and maintains the SSM's feature extraction capability. Notably, RFA also enables pre-deployment weight quantization, striking a balance between computational efficiency and model accuracy. Extensive experiments on IR tasks demonstrate that Q-MambaIR consistently outperforms existing quantized SSMs, achieving much higher state-of-the-art (SOTA) accuracy results with only a negligible increase in training computation and storage saving.