 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgePillarMamba: Learning Local-Global Context for Roadside Point Cloud via Hybrid State Space Model
May 08, 2025Serving the Intelligent Transport System (ITS) and Vehicle-to-Everything (V2X) tasks, roadside perception has received increasing attention in recent years, as it can extend the perception range of connected vehicles and improve traffic safety. However, roadside point cloud oriented 3D object detection has not been effectively explored. To some extent, the key to the performance of a point cloud detector lies in the receptive field of the network and the ability to effectively utilize the scene context. The recent emergence of Mamba, based on State Space Model (SSM), has shaken up the traditional convolution and transformers that have long been the foundational building blocks, due to its efficient global receptive field. In this work, we introduce Mamba to pillar-based roadside point cloud perception and propose a framework based on Cross-stage State-space Group (CSG), called PillarMamba. It enhances the expressiveness of the network and achieves efficient computation through cross-stage feature fusion. However, due to the limitations of scan directions, state space model faces local connection disrupted and historical relationship forgotten. To address this, we propose the Hybrid State-space Block (HSB) to obtain the local-global context of roadside point cloud. Specifically, it enhances neighborhood connections through local convolution and preserves historical memory through residual attention. The proposed method outperforms the state-of-the-art methods on the popular large scale roadside benchmark: DAIR-V2X-I. The code will be released soon.
HeightFormer: Learning Height Prediction in Voxel Features for Roadside Vision Centric 3D Object Detection via Transformer
Mar 13, 2025
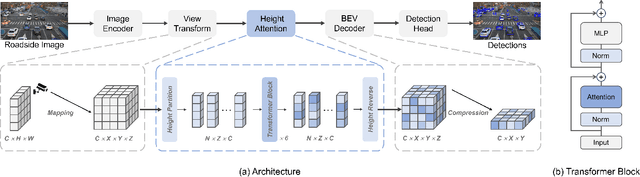


Roadside vision centric 3D object detection has received increasing attention in recent years. It expands the perception range of autonomous vehicles, enhances the road safety. Previous methods focused on predicting per-pixel height rather than depth, making significant gains in roadside visual perception. While it is limited by the perspective property of near-large and far-small on image features, making it difficult for network to understand real dimension of objects in the 3D world. BEV features and voxel features present the real distribution of objects in 3D world compared to the image features. However, BEV features tend to lose details due to the lack of explicit height information, and voxel features are computationally expensive. Inspired by this insight, an efficient framework learning height prediction in voxel features via transformer is proposed, dubbed HeightFormer. It groups the voxel features into local height sequences, and utilize attention mechanism to obtain height distribution prediction. Subsequently, the local height sequences are reassembled to generate accurate 3D features. The proposed method is applied to two large-scale roadside benchmarks, DAIR-V2X-I and Rope3D. Extensive experiments are performed and the HeightFormer outperforms the state-of-the-art methods in roadside vision centric 3D object detection task.