 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeHeatV2X: Scalable Heterogeneous Collaborative Perception via Efficient Alignment and Interaction
Nov 13, 2025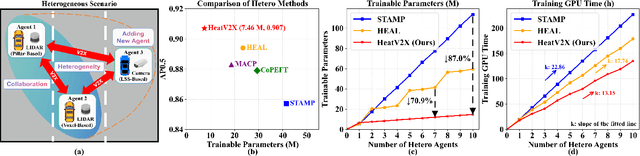
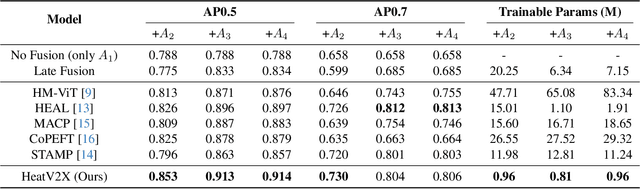
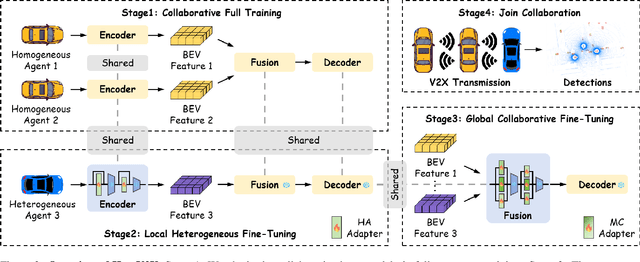
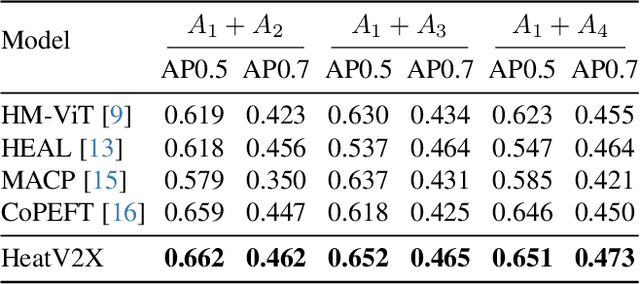
Vehicle-to-Everything (V2X) collaborative perception extends sensing beyond single vehicle limits through transmission. However, as more agents participate, existing frameworks face two key challenges: (1) the participating agents are inherently multi-modal and heterogeneous, and (2) the collaborative framework must be scalable to accommodate new agents. The former requires effective cross-agent feature alignment to mitigate heterogeneity loss, while the latter renders full-parameter training impractical, highlighting the importance of scalable adaptation. To address these issues, we propose Heterogeneous Adaptation (HeatV2X), a scalable collaborative framework. We first train a high-performance agent based on heterogeneous graph attention as the foundation for collaborative learning. Then, we design Local Heterogeneous Fine-Tuning and Global Collaborative Fine-Tuning to achieve effective alignment and interaction among heterogeneous agents. The former efficiently extracts modality-specific differences using Hetero-Aware Adapters, while the latter employs the Multi-Cognitive Adapter to enhance cross-agent collaboration and fully exploit the fusion potential. These designs enable substantial performance improvement of the collaborative framework with minimal training cost. We evaluate our approach on the OPV2V-H and DAIR-V2X datasets. Experimental results demonstrate that our method achieves superior perception performance with significantly reduced training overhead, outperforming existing state-of-the-art approaches. Our implementation will be released soon.
Frequency Matters: When Time Series Foundation Models Fail Under Spectral Shift
Nov 06, 2025Time series foundation models (TSFMs) have shown strong results on public benchmarks, prompting comparisons to a "BERT moment" for time series. Their effectiveness in industrial settings, however, remains uncertain. We examine why TSFMs often struggle to generalize and highlight spectral shift (a mismatch between the dominant frequency components in downstream tasks and those represented during pretraining) as a key factor. We present evidence from an industrial-scale player engagement prediction task in mobile gaming, where TSFMs underperform domain-adapted baselines. To isolate the mechanism, we design controlled synthetic experiments contrasting signals with seen versus unseen frequency bands, observing systematic degradation under spectral mismatch. These findings position frequency awareness as critical for robust TSFM deployment and motivate new pretraining and evaluation protocols that explicitly account for spectral diversity.
Efficient Unified Caching for Accelerating Heterogeneous AI Workloads
Jun 14, 2025Modern AI clusters, which host diverse workloads like data pre-processing, training and inference, often store the large-volume data in cloud storage and employ caching frameworks to facilitate remote data access. To avoid code-intrusion complexity and minimize cache space wastage, it is desirable to maintain a unified cache shared by all the workloads. However, existing cache management strategies, designed for specific workloads, struggle to handle the heterogeneous AI workloads in a cluster -- which usually exhibit heterogeneous access patterns and item storage granularities. In this paper, we propose IGTCache, a unified, high-efficacy cache for modern AI clusters. IGTCache leverages a hierarchical access abstraction, AccessStreamTree, to organize the recent data accesses in a tree structure, facilitating access pattern detection at various granularities. Using this abstraction, IGTCache applies hypothesis testing to categorize data access patterns as sequential, random, or skewed. Based on these detected access patterns and granularities, IGTCache tailors optimal cache management strategies including prefetching, eviction, and space allocation accordingly. Experimental results show that IGTCache increases the cache hit ratio by 55.6% over state-of-the-art caching frameworks, reducing the overall job completion time by 52.2%.
Dynamic Bipedal MPC with Foot-level Obstacle Avoidance and Adjustable Step Timing
May 19, 2025Collision-free planning is essential for bipedal robots operating within unstructured environments. This paper presents a real-time Model Predictive Control (MPC) framework that addresses both body and foot avoidance for dynamic bipedal robots. Our contribution is two-fold: we introduce (1) a novel formulation for adjusting step timing to facilitate faster body avoidance and (2) a novel 3D foot-avoidance formulation that implicitly selects swing trajectories and footholds that either steps over or navigate around obstacles with awareness of Center of Mass (COM) dynamics. We achieve body avoidance by applying a half-space relaxation of the safe region but introduce a switching heuristic based on tracking error to detect a need to change foot-timing schedules. To enable foot avoidance and viable landing footholds on all sides of foot-level obstacles, we decompose the non-convex safe region on the ground into several convex polygons and use Mixed-Integer Quadratic Programming to determine the optimal candidate. We found that introducing a soft minimum-travel-distance constraint is effective in preventing the MPC from being trapped in local minima that can stall half-space relaxation methods behind obstacles. We demonstrated the proposed algorithms on multibody simulations on the bipedal robot platforms, Cassie and Digit, as well as hardware experiments on Digit.
PillarMamba: Learning Local-Global Context for Roadside Point Cloud via Hybrid State Space Model
May 08, 2025Serving the Intelligent Transport System (ITS) and Vehicle-to-Everything (V2X) tasks, roadside perception has received increasing attention in recent years, as it can extend the perception range of connected vehicles and improve traffic safety. However, roadside point cloud oriented 3D object detection has not been effectively explored. To some extent, the key to the performance of a point cloud detector lies in the receptive field of the network and the ability to effectively utilize the scene context. The recent emergence of Mamba, based on State Space Model (SSM), has shaken up the traditional convolution and transformers that have long been the foundational building blocks, due to its efficient global receptive field. In this work, we introduce Mamba to pillar-based roadside point cloud perception and propose a framework based on Cross-stage State-space Group (CSG), called PillarMamba. It enhances the expressiveness of the network and achieves efficient computation through cross-stage feature fusion. However, due to the limitations of scan directions, state space model faces local connection disrupted and historical relationship forgotten. To address this, we propose the Hybrid State-space Block (HSB) to obtain the local-global context of roadside point cloud. Specifically, it enhances neighborhood connections through local convolution and preserves historical memory through residual attention. The proposed method outperforms the state-of-the-art methods on the popular large scale roadside benchmark: DAIR-V2X-I. The code will be released soon.
HeightFormer: Learning Height Prediction in Voxel Features for Roadside Vision Centric 3D Object Detection via Transformer
Mar 13, 2025
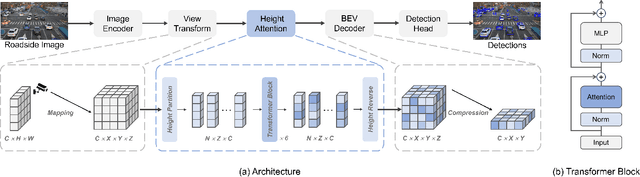


Roadside vision centric 3D object detection has received increasing attention in recent years. It expands the perception range of autonomous vehicles, enhances the road safety. Previous methods focused on predicting per-pixel height rather than depth, making significant gains in roadside visual perception. While it is limited by the perspective property of near-large and far-small on image features, making it difficult for network to understand real dimension of objects in the 3D world. BEV features and voxel features present the real distribution of objects in 3D world compared to the image features. However, BEV features tend to lose details due to the lack of explicit height information, and voxel features are computationally expensive. Inspired by this insight, an efficient framework learning height prediction in voxel features via transformer is proposed, dubbed HeightFormer. It groups the voxel features into local height sequences, and utilize attention mechanism to obtain height distribution prediction. Subsequently, the local height sequences are reassembled to generate accurate 3D features. The proposed method is applied to two large-scale roadside benchmarks, DAIR-V2X-I and Rope3D. Extensive experiments are performed and the HeightFormer outperforms the state-of-the-art methods in roadside vision centric 3D object detection task.
MPO: An Efficient Post-Processing Framework for Mixing Diverse Preference Alignment
Feb 25, 2025Reinforcement Learning from Human Feedback (RLHF) has shown promise in aligning large language models (LLMs). Yet its reliance on a singular reward model often overlooks the diversity of human preferences. Recent approaches address this limitation by leveraging multi-dimensional feedback to fine-tune corresponding reward models and train LLMs using reinforcement learning. However, the process is costly and unstable, especially given the competing and heterogeneous nature of human preferences. In this paper, we propose Mixing Preference Optimization (MPO), a post-processing framework for aggregating single-objective policies as an alternative to both multi-objective RLHF (MORLHF) and MaxMin-RLHF. MPO avoids alignment from scratch. Instead, it log-linearly combines existing policies into a unified one with the weight of each policy computed via a batch stochastic mirror descent. Empirical results demonstrate that MPO achieves balanced performance across diverse preferences, outperforming or matching existing models with significantly reduced computational costs.
Unified Approaches in Self-Supervised Event Stream Modeling: Progress and Prospects
Feb 07, 2025



The proliferation of digital interactions across diverse domains, such as healthcare, e-commerce, gaming, and finance, has resulted in the generation of vast volumes of event stream (ES) data. ES data comprises continuous sequences of timestamped events that encapsulate detailed contextual information relevant to each domain. While ES data holds significant potential for extracting actionable insights and enhancing decision-making, its effective utilization is hindered by challenges such as the scarcity of labeled data and the fragmented nature of existing research efforts. Self-Supervised Learning (SSL) has emerged as a promising paradigm to address these challenges by enabling the extraction of meaningful representations from unlabeled ES data. In this survey, we systematically review and synthesize SSL methodologies tailored for ES modeling across multiple domains, bridging the gaps between domain-specific approaches that have traditionally operated in isolation. We present a comprehensive taxonomy of SSL techniques, encompassing both predictive and contrastive paradigms, and analyze their applicability and effectiveness within different application contexts. Furthermore, we identify critical gaps in current research and propose a future research agenda aimed at developing scalable, domain-agnostic SSL frameworks for ES modeling. By unifying disparate research efforts and highlighting cross-domain synergies, this survey aims to accelerate innovation, improve reproducibility, and expand the applicability of SSL to diverse real-world ES challenges.
Expressivity of Representation Learning on Continuous-Time Dynamic Graphs: An Information-Flow Centric Review
Dec 05, 2024Graphs are ubiquitous in real-world applications, ranging from social networks to biological systems, and have inspired the development of Graph Neural Networks (GNNs) for learning expressive representations. While most research has centered on static graphs, many real-world scenarios involve dynamic, temporally evolving graphs, motivating the need for Continuous-Time Dynamic Graph (CTDG) models. This paper provides a comprehensive review of Graph Representation Learning (GRL) on CTDGs with a focus on Self-Supervised Representation Learning (SSRL). We introduce a novel theoretical framework that analyzes the expressivity of CTDG models through an Information-Flow (IF) lens, quantifying their ability to propagate and encode temporal and structural information. Leveraging this framework, we categorize existing CTDG methods based on their suitability for different graph types and application scenarios. Within the same scope, we examine the design of SSRL methods tailored to CTDGs, such as predictive and contrastive approaches, highlighting their potential to mitigate the reliance on labeled data. Empirical evaluations on synthetic and real-world datasets validate our theoretical insights, demonstrating the strengths and limitations of various methods across long-range, bi-partite and community-based graphs. This work offers both a theoretical foundation and practical guidance for selecting and developing CTDG models, advancing the understanding of GRL in dynamic settings.
Understanding Players as if They Are Talking to the Game in a Customized Language: A Pilot Study
Oct 24, 2024

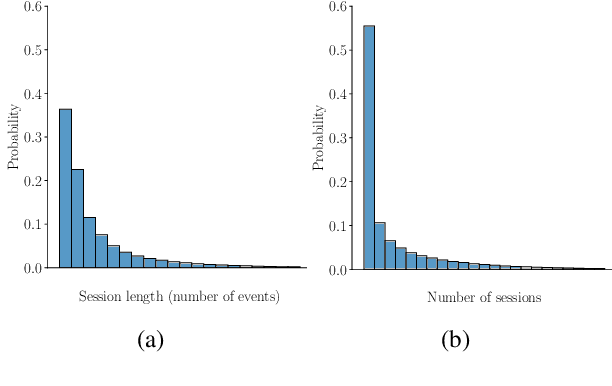

This pilot study explores the application of language models (LMs) to model game event sequences, treating them as a customized natural language. We investigate a popular mobile game, transforming raw event data into textual sequences and pretraining a Longformer model on this data. Our approach captures the rich and nuanced interactions within game sessions, effectively identifying meaningful player segments. The results demonstrate the potential of self-supervised LMs in enhancing game design and personalization without relying on ground-truth labels.