 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeProbabilistic Textual Time Series Depression Detection
Nov 06, 2025Accurate and interpretable predictions of depression severity are essential for clinical decision support, yet existing models often lack uncertainty estimates and temporal modeling. We propose PTTSD, a Probabilistic Textual Time Series Depression Detection framework that predicts PHQ-8 scores from utterance-level clinical interviews while modeling uncertainty over time. PTTSD includes sequence-to-sequence and sequence-to-one variants, both combining bidirectional LSTMs, self-attention, and residual connections with Gaussian or Student-t output heads trained via negative log-likelihood. Evaluated on E-DAIC and DAIC-WOZ, PTTSD achieves state-of-the-art performance among text-only systems (e.g., MAE = 3.85 on E-DAIC, 3.55 on DAIC) and produces well-calibrated prediction intervals. Ablations confirm the value of attention and probabilistic modeling, while comparisons with MentalBERT establish generality. A three-part calibration analysis and qualitative case studies further highlight the interpretability and clinical relevance of uncertainty-aware forecasting.
BiSparse-AAS: Bilinear Sparse Attention and Adaptive Spans Framework for Scalable and Efficient Text Summarization
Oct 31, 2025Transformer-based architectures have advanced text summarization, yet their quadratic complexity limits scalability on long documents. This paper introduces BiSparse-AAS (Bilinear Sparse Attention with Adaptive Spans), a novel framework that combines sparse attention, adaptive spans, and bilinear attention to address these limitations. Sparse attention reduces computational costs by focusing on the most relevant parts of the input, while adaptive spans dynamically adjust the attention ranges. Bilinear attention complements both by modeling complex token interactions within this refined context. BiSparse-AAS consistently outperforms state-of-the-art baselines in both extractive and abstractive summarization tasks, achieving average ROUGE improvements of about 68.1% on CNN/DailyMail and 52.6% on XSum, while maintaining strong performance on OpenWebText and Gigaword datasets. By addressing efficiency, scalability, and long-sequence modeling, BiSparse-AAS provides a unified, practical solution for real-world text summarization applications.
Leveraging Machine Learning Models to Predict the Outcome of Digital Medical Triage Interviews
Apr 16, 2025



Many existing digital triage systems are questionnaire-based, guiding patients to appropriate care levels based on information (e.g., symptoms, medical history, and urgency) provided by the patients answering questionnaires. Such a system often uses a deterministic model with predefined rules to determine care levels. It faces challenges with incomplete triage interviews since it can only assist patients who finish the process. In this study, we explore the use of machine learning (ML) to predict outcomes of unfinished interviews, aiming to enhance patient care and service quality. Predicting triage outcomes from incomplete data is crucial for patient safety and healthcare efficiency. Our findings show that decision-tree models, particularly LGBMClassifier and CatBoostClassifier, achieve over 80\% accuracy in predicting outcomes from complete interviews while having a linear correlation between the prediction accuracy and interview completeness degree. For example, LGBMClassifier achieves 88,2\% prediction accuracy for interviews with 100\% completeness, 79,6\% accuracy for interviews with 80\% completeness, 58,9\% accuracy for 60\% completeness, and 45,7\% accuracy for 40\% completeness. The TabTransformer model demonstrated exceptional accuracy of over 80\% for all degrees of completeness but required extensive training time, indicating a need for more powerful computational resources. The study highlights the linear correlation between interview completeness and predictive power of the decision-tree models.
CFiCS: Graph-Based Classification of Common Factors and Microcounseling Skills
Mar 28, 2025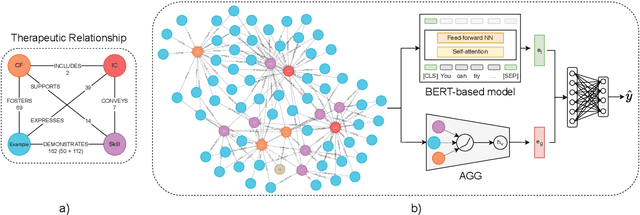
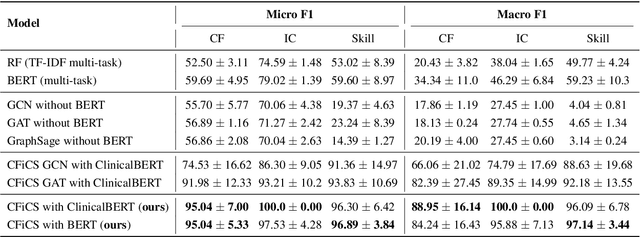
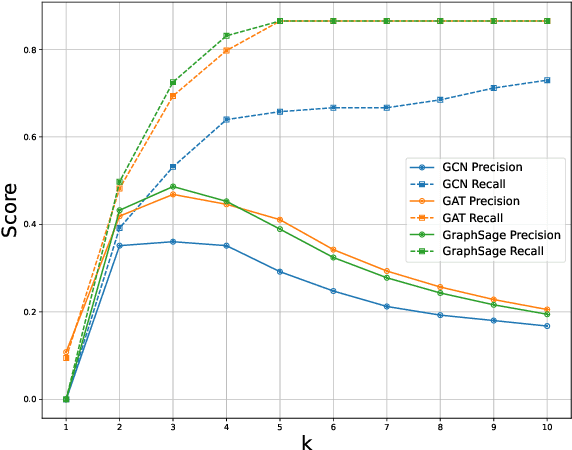
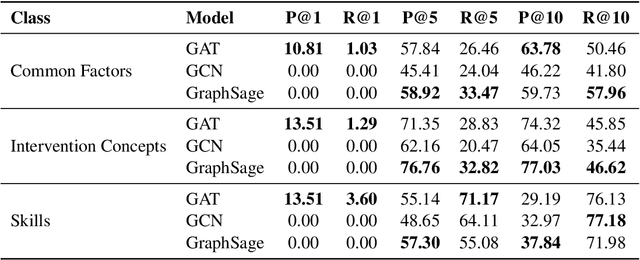
Common factors and microcounseling skills are critical to the effectiveness of psychotherapy. Understanding and measuring these elements provides valuable insights into therapeutic processes and outcomes. However, automatic identification of these change principles from textual data remains challenging due to the nuanced and context-dependent nature of therapeutic dialogue. This paper introduces CFiCS, a hierarchical classification framework integrating graph machine learning with pretrained contextual embeddings. We represent common factors, intervention concepts, and microcounseling skills as a heterogeneous graph, where textual information from ClinicalBERT enriches each node. This structure captures both the hierarchical relationships (e.g., skill-level nodes linking to broad factors) and the semantic properties of therapeutic concepts. By leveraging graph neural networks, CFiCS learns inductive node embeddings that generalize to unseen text samples lacking explicit connections. Our results demonstrate that integrating ClinicalBERT node features and graph structure significantly improves classification performance, especially in fine-grained skill prediction. CFiCS achieves substantial gains in both micro and macro F1 scores across all tasks compared to baselines, including random forests, BERT-based multi-task models, and graph-based methods.
The Impact of Background Removal on Performance of Neural Networks for Fashion Image Classification and Segmentation
Aug 18, 2023



Fashion understanding is a hot topic in computer vision, with many applications having great business value in the market. Fashion understanding remains a difficult challenge for computer vision due to the immense diversity of garments and various scenes and backgrounds. In this work, we try removing the background from fashion images to boost data quality and increase model performance. Having fashion images of evident persons in fully visible garments, we can utilize Salient Object Detection to achieve the background removal of fashion data to our expectations. A fashion image with the background removed is claimed as the "rembg" image, contrasting with the original one in the fashion dataset. We conducted extensive comparative experiments with these two types of images on multiple aspects of model training, including model architectures, model initialization, compatibility with other training tricks and data augmentations, and target task types. Our experiments show that background removal can effectively work for fashion data in simple and shallow networks that are not susceptible to overfitting. It can improve model accuracy by up to 5% in the classification on the FashionStyle14 dataset when training models from scratch. However, background removal does not perform well in deep neural networks due to incompatibility with other regularization techniques like batch normalization, pre-trained initialization, and data augmentations introducing randomness. The loss of background pixels invalidates many existing training tricks in the model training, adding the risk of overfitting for deep models.
Cloud-native RStudio on Kubernetes for Hopsworks
Jul 18, 2023



In order to fully benefit from cloud computing, services are designed following the "multi-tenant" architectural model, which is aimed at maximizing resource sharing among users. However, multi-tenancy introduces challenges of security, performance isolation, scaling, and customization. RStudio server is an open-source Integrated Development Environment (IDE) accessible over a web browser for the R programming language. We present the design and implementation of a multi-user distributed system on Hopsworks, a data-intensive AI platform, following the multi-tenant model that provides RStudio as Software as a Service (SaaS). We use the most popular cloud-native technologies: Docker and Kubernetes, to solve the problems of performance isolation, security, and scaling that are present in a multi-tenant environment. We further enable secure data sharing in RStudio server instances to provide data privacy and allow collaboration among RStudio users. We integrate our system with Apache Spark, which can scale and handle Big Data processing workloads. Also, we provide a UI where users can provide custom configurations and have full control of their own RStudio server instances. Our system was tested on a Google Cloud Platform cluster with four worker nodes, each with 30GB of RAM allocated to them. The tests on this cluster showed that 44 RStudio servers, each with 2GB of RAM, can be run concurrently. Our system can scale out to potentially support hundreds of concurrently running RStudio servers by adding more resources (CPUs and RAM) to the cluster or system.
AIC-AB NET: A Neural Network for Image Captioning with Spatial Attention and Text Attributes
Jul 14, 2023Image captioning is a significant field across computer vision and natural language processing. We propose and present AIC-AB NET, a novel Attribute-Information-Combined Attention-Based Network that combines spatial attention architecture and text attributes in an encoder-decoder. For caption generation, adaptive spatial attention determines which image region best represents the image and whether to attend to the visual features or the visual sentinel. Text attribute information is synchronously fed into the decoder to help image recognition and reduce uncertainty. We have tested and evaluated our AICAB NET on the MS COCO dataset and a new proposed Fashion dataset. The Fashion dataset is employed as a benchmark of single-object images. The results show the superior performance of the proposed model compared to the state-of-the-art baseline and ablated models on both the images from MSCOCO and our single-object images. Our AIC-AB NET outperforms the baseline adaptive attention network by 0.017 (CIDEr score) on the MS COCO dataset and 0.095 (CIDEr score) on the Fashion dataset.
Federated Learning for Medical Applications: A Taxonomy, Current Trends, Challenges, and Future Research Directions
Aug 15, 2022
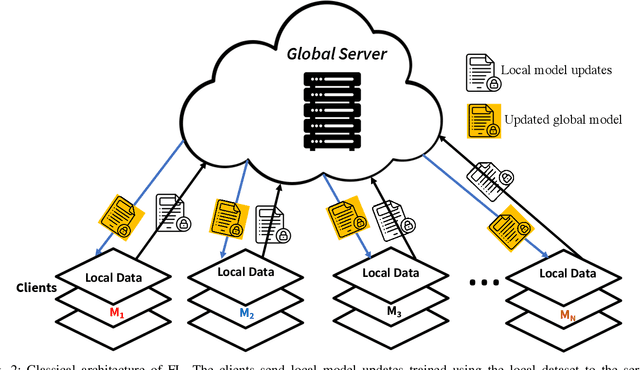
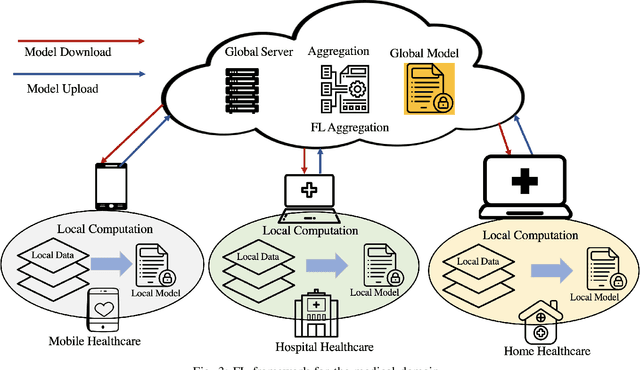
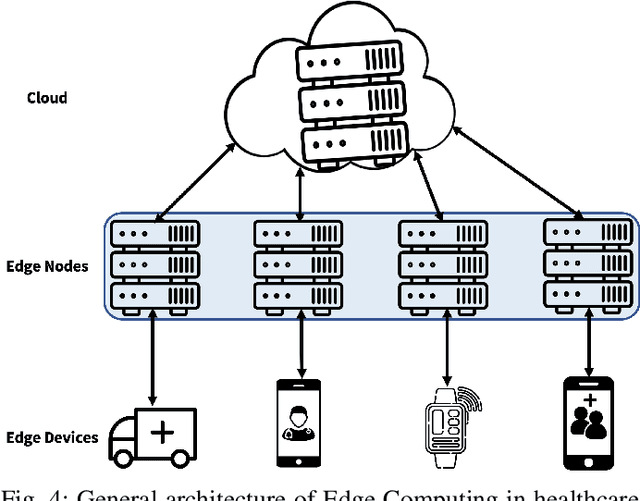
With the advent of the IoT, AI, and ML/DL algorithms, the data-driven medical application has emerged as a promising tool for designing reliable and scalable diagnostic and prognostic models from medical data. This has attracted a great deal of attention from academia to industry in recent years. This has undoubtedly improved the quality of healthcare delivery. However, these AI-based medical applications still have poor adoption due to their difficulties in satisfying strict security, privacy, and quality of service standards (such as low latency). Moreover, medical data are usually fragmented and private, making it challenging to generate robust results across populations. Recent developments in federated learning (FL) have made it possible to train complex machine-learned models in a distributed manner. Thus, FL has become an active research domain, particularly processing the medical data at the edge of the network in a decentralized way to preserve privacy and security concerns. To this end, this survey paper highlights the current and future of FL technology in medical applications where data sharing is a significant burden. It also review and discuss the current research trends and their outcomes for designing reliable and scalable FL models. We outline the general FL's statistical problems, device challenges, security, privacy concerns, and its potential in the medical domain. Moreover, our study is also focused on medical applications where we highlight the burden of global cancer and the efficient use of FL for the development of computer-aided diagnosis tools for addressing them. We hope that this review serves as a checkpoint that sets forth the existing state-of-the-art works in a thorough manner and offers open problems and future research directions for this field.
Accelerate Model Parallel Training by Using Efficient Graph Traversal Order in Device Placement
Jan 21, 2022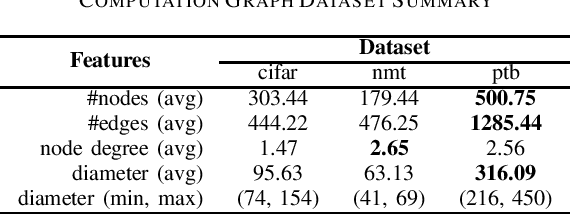
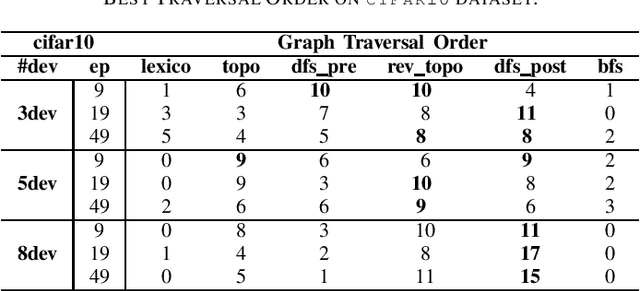
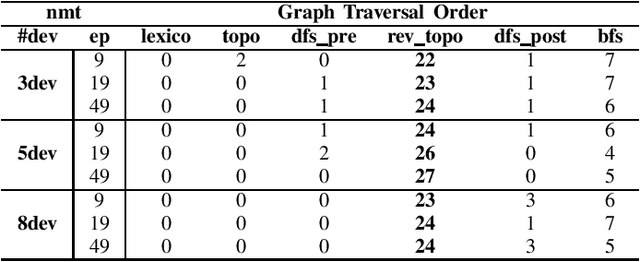
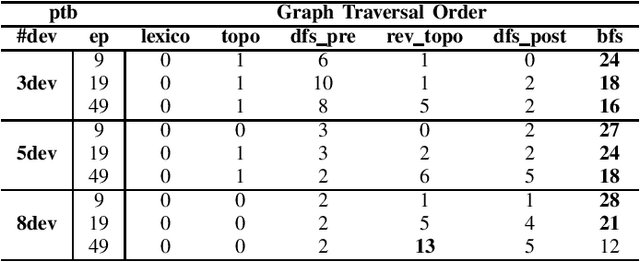
Modern neural networks require long training to reach decent performance on massive datasets. One common approach to speed up training is model parallelization, where large neural networks are split across multiple devices. However, different device placements of the same neural network lead to different training times. Most of the existing device placement solutions treat the problem as sequential decision-making by traversing neural network graphs and assigning their neurons to different devices. This work studies the impact of graph traversal order on device placement. In particular, we empirically study how different graph traversal order leads to different device placement, which in turn affects the training execution time. Our experiment results show that the best graph traversal order depends on the type of neural networks and their computation graphs features. In this work, we also provide recommendations on choosing graph traversal order in device placement for various neural network families to improve the training time in model parallelization.