 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastNER: Contrastive-based Prompt Tuning for Few-shot NER
May 29, 2023Prompt-based language models have produced encouraging results in numerous applications, including Named Entity Recognition (NER) tasks. NER aims to identify entities in a sentence and provide their types. However, the strong performance of most available NER approaches is heavily dependent on the design of discrete prompts and a verbalizer to map the model-predicted outputs to entity categories, which are complicated undertakings. To address these challenges, we present ContrastNER, a prompt-based NER framework that employs both discrete and continuous tokens in prompts and uses a contrastive learning approach to learn the continuous prompts and forecast entity types. The experimental results demonstrate that ContrastNER obtains competitive performance to the state-of-the-art NER methods in high-resource settings and outperforms the state-of-the-art models in low-resource circumstances without requiring extensive manual prompt engineering and verbalizer design.
* 9 pages, 5 figures, COMPSAC2023
DeepAqua: Self-Supervised Semantic Segmentation of Wetlands from SAR Images using Knowledge Distillation
May 02, 2023



Remote sensing has significantly advanced water detection by applying semantic segmentation techniques to satellite imagery. However, semantic segmentation remains challenging due to the substantial amount of annotated data required. This is particularly problematic in wetland detection, where water extent varies over time and space, necessitating multiple annotations for the same area. In this paper, we present DeepAqua, a self-supervised deep learning model that leverages knowledge distillation to eliminate the need for manual annotations during the training phase. DeepAqua utilizes the Normalized Difference Water Index (NDWI) as a teacher model to train a Convolutional Neural Network (CNN) for segmenting water from Synthetic Aperture Radar (SAR) images. To train the student model, we exploit cases where optical- and radar-based water masks coincide, enabling the detection of both open and vegetated water surfaces. Our model represents a significant advancement in computer vision techniques by effectively training semantic segmentation models without any manually annotated data. This approach offers a practical solution for monitoring wetland water extent changes without needing ground truth data, making it highly adaptable and scalable for wetland conservation efforts.
Accelerate Model Parallel Training by Using Efficient Graph Traversal Order in Device Placement
Jan 21, 2022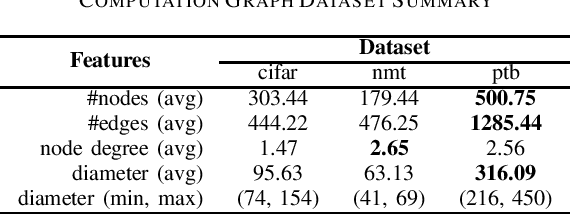
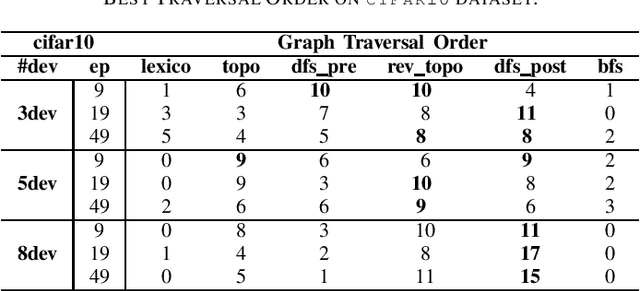
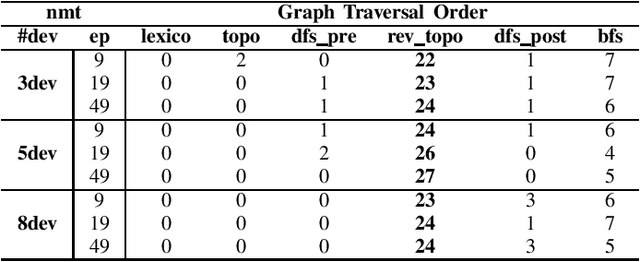
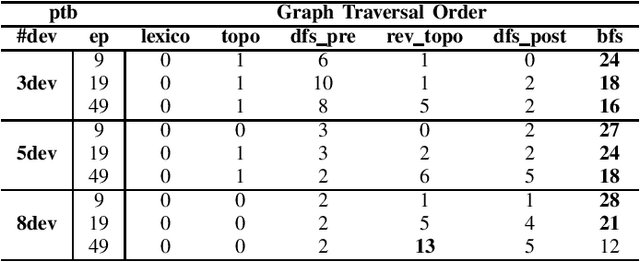
Modern neural networks require long training to reach decent performance on massive datasets. One common approach to speed up training is model parallelization, where large neural networks are split across multiple devices. However, different device placements of the same neural network lead to different training times. Most of the existing device placement solutions treat the problem as sequential decision-making by traversing neural network graphs and assigning their neurons to different devices. This work studies the impact of graph traversal order on device placement. In particular, we empirically study how different graph traversal order leads to different device placement, which in turn affects the training execution time. Our experiment results show that the best graph traversal order depends on the type of neural networks and their computation graphs features. In this work, we also provide recommendations on choosing graph traversal order in device placement for various neural network families to improve the training time in model parallelization.