 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeContrastNER: Contrastive-based Prompt Tuning for Few-shot NER
May 29, 2023Prompt-based language models have produced encouraging results in numerous applications, including Named Entity Recognition (NER) tasks. NER aims to identify entities in a sentence and provide their types. However, the strong performance of most available NER approaches is heavily dependent on the design of discrete prompts and a verbalizer to map the model-predicted outputs to entity categories, which are complicated undertakings. To address these challenges, we present ContrastNER, a prompt-based NER framework that employs both discrete and continuous tokens in prompts and uses a contrastive learning approach to learn the continuous prompts and forecast entity types. The experimental results demonstrate that ContrastNER obtains competitive performance to the state-of-the-art NER methods in high-resource settings and outperforms the state-of-the-art models in low-resource circumstances without requiring extensive manual prompt engineering and verbalizer design.
* 9 pages, 5 figures, COMPSAC2023
Deep Text Mining of Instagram Data Without Strong Supervision
Sep 24, 2019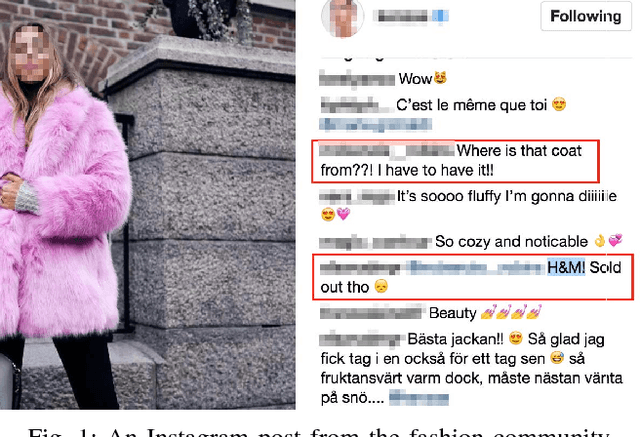
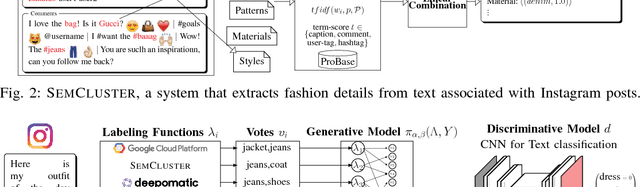
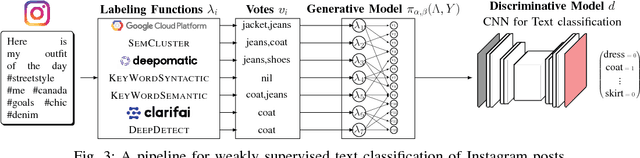

With the advent of social media, our online feeds increasingly consist of short, informal, and unstructured text. This textual data can be analyzed for the purpose of improving user recommendations and detecting trends. Instagram is one of the largest social media platforms, containing both text and images. However, most of the prior research on text processing in social media is focused on analyzing Twitter data, and little attention has been paid to text mining of Instagram data. Moreover, many text mining methods rely on annotated training data, which in practice is both difficult and expensive to obtain. In this paper, we present methods for unsupervised mining of fashion attributes from Instagram text, which can enable a new kind of user recommendation in the fashion domain. In this context, we analyze a corpora of Instagram posts from the fashion domain, introduce a system for extracting fashion attributes from Instagram, and train a deep clothing classifier with weak supervision to classify Instagram posts based on the associated text. With our experiments, we confirm that word embeddings are a useful asset for information extraction. Experimental results show that information extraction using word embeddings outperforms a baseline that uses Levenshtein distance. The results also show the benefit of combining weak supervision signals using generative models instead of majority voting. Using weak supervision and generative modeling, an F1 score of 0.61 is achieved on the task of classifying the image contents of Instagram posts based solely on the associated text, which is on level with human performance. Finally, our empirical study provides one of the few available studies on Instagram text and shows that the text is noisy, that the text distribution exhibits the long-tail phenomenon, and that comment sections on Instagram are multi-lingual.