 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSustainable LLM Inference for Edge AI: Evaluating Quantized LLMs for Energy Efficiency, Output Accuracy, and Inference Latency
Apr 04, 2025



Deploying Large Language Models (LLMs) on edge devices presents significant challenges due to computational constraints, memory limitations, inference speed, and energy consumption. Model quantization has emerged as a key technique to enable efficient LLM inference by reducing model size and computational overhead. In this study, we conduct a comprehensive analysis of 28 quantized LLMs from the Ollama library, which applies by default Post-Training Quantization (PTQ) and weight-only quantization techniques, deployed on an edge device (Raspberry Pi 4 with 4GB RAM). We evaluate energy efficiency, inference performance, and output accuracy across multiple quantization levels and task types. Models are benchmarked on five standardized datasets (CommonsenseQA, BIG-Bench Hard, TruthfulQA, GSM8K, and HumanEval), and we employ a high-resolution, hardware-based energy measurement tool to capture real-world power consumption. Our findings reveal the trade-offs between energy efficiency, inference speed, and accuracy in different quantization settings, highlighting configurations that optimize LLM deployment for resource-constrained environments. By integrating hardware-level energy profiling with LLM benchmarking, this study provides actionable insights for sustainable AI, bridging a critical gap in existing research on energy-aware LLM deployment.
Literal-Aware Knowledge Graph Embedding for Welding Quality Monitoring: A Bosch Case
Aug 02, 2023



Recently there has been a series of studies in knowledge graph embedding (KGE), which attempts to learn the embeddings of the entities and relations as numerical vectors and mathematical mappings via machine learning (ML). However, there has been limited research that applies KGE for industrial problems in manufacturing. This paper investigates whether and to what extent KGE can be used for an important problem: quality monitoring for welding in manufacturing industry, which is an impactful process accounting for production of millions of cars annually. The work is in line with Bosch research of data-driven solutions that intends to replace the traditional way of destroying cars, which is extremely costly and produces waste. The paper tackles two very challenging questions simultaneously: how large the welding spot diameter is; and to which car body the welded spot belongs to. The problem setting is difficult for traditional ML because there exist a high number of car bodies that should be assigned as class labels. We formulate the problem as link prediction, and experimented popular KGE methods on real industry data, with consideration of literals. Our results reveal both limitations and promising aspects of adapted KGE methods.
Scaling Data Science Solutions with Semantics and Machine Learning: Bosch Case
Aug 02, 2023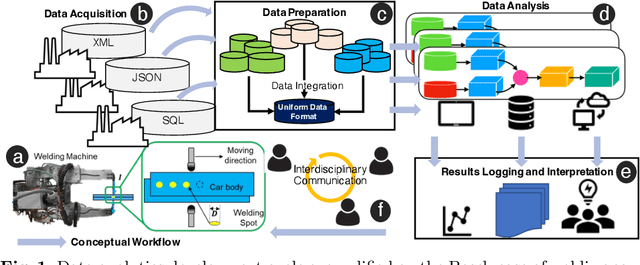
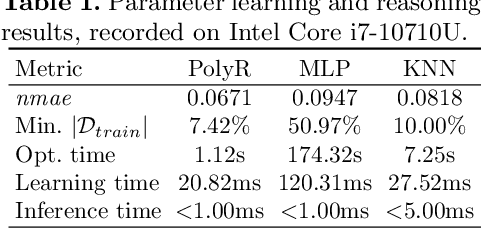
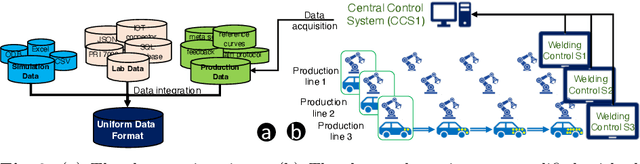
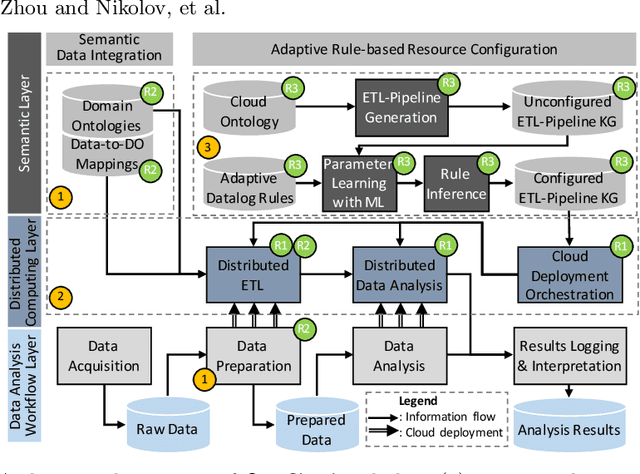
Industry 4.0 and Internet of Things (IoT) technologies unlock unprecedented amount of data from factory production, posing big data challenges in volume and variety. In that context, distributed computing solutions such as cloud systems are leveraged to parallelise the data processing and reduce computation time. As the cloud systems become increasingly popular, there is increased demand that more users that were originally not cloud experts (such as data scientists, domain experts) deploy their solutions on the cloud systems. However, it is non-trivial to address both the high demand for cloud system users and the excessive time required to train them. To this end, we propose SemCloud, a semantics-enhanced cloud system, that couples cloud system with semantic technologies and machine learning. SemCloud relies on domain ontologies and mappings for data integration, and parallelises the semantic data integration and data analysis on distributed computing nodes. Furthermore, SemCloud adopts adaptive Datalog rules and machine learning for automated resource configuration, allowing non-cloud experts to use the cloud system. The system has been evaluated in industrial use case with millions of data, thousands of repeated runs, and domain users, showing promising results.
ContrastNER: Contrastive-based Prompt Tuning for Few-shot NER
May 29, 2023Prompt-based language models have produced encouraging results in numerous applications, including Named Entity Recognition (NER) tasks. NER aims to identify entities in a sentence and provide their types. However, the strong performance of most available NER approaches is heavily dependent on the design of discrete prompts and a verbalizer to map the model-predicted outputs to entity categories, which are complicated undertakings. To address these challenges, we present ContrastNER, a prompt-based NER framework that employs both discrete and continuous tokens in prompts and uses a contrastive learning approach to learn the continuous prompts and forecast entity types. The experimental results demonstrate that ContrastNER obtains competitive performance to the state-of-the-art NER methods in high-resource settings and outperforms the state-of-the-art models in low-resource circumstances without requiring extensive manual prompt engineering and verbalizer design.
* 9 pages, 5 figures, COMPSAC2023
Query-based Industrial Analytics over Knowledge Graphs with Ontology Reshaping
Sep 22, 2022Industrial analytics that includes among others equipment diagnosis and anomaly detection heavily relies on integration of heterogeneous production data. Knowledge Graphs (KGs) as the data format and ontologies as the unified data schemata are a prominent solution that offers high quality data integration and a convenient and standardised way to exchange data and to layer analytical applications over it. However, poor design of ontologies of high degree of mismatch between them and industrial data naturally lead to KGs of low quality that impede the adoption and scalability of industrial analytics. Indeed, such KGs substantially increase the training time of writing queries for users, consume high volume of storage for redundant information, and are hard to maintain and update. To address this problem we propose an ontology reshaping approach to transform ontologies into KG schemata that better reflect the underlying data and thus help to construct better KGs. In this poster we present a preliminary discussion of our on-going research, evaluate our approach with a rich set of SPARQL queries on real-world industry data at Bosch and discuss our findings.