 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAR-VLA: True Autoregressive Action Expert for Vision-Language-Action Models
Mar 10, 2026We propose a standalone autoregressive (AR) Action Expert that generates actions as a continuous causal sequence while conditioning on refreshable vision-language prefixes. In contrast to existing Vision-Language-Action (VLA) models and diffusion policies that reset temporal context with each new observation and predict actions reactively, our Action Expert maintains its own history through a long-lived memory and is inherently context-aware. This structure addresses the frequency mismatch between fast control and slow reasoning, enabling efficient independent pretraining of kinematic syntax and modular integration with heavy perception backbones, naturally ensuring spatio-temporally consistent action generation across frames. To synchronize these asynchronous hybrid V-L-A modalities, we utilize a re-anchoring mechanism that mathematically accounts for perception staleness during both training and inference. Experiments on simulated and real-robot manipulation tasks demonstrate that the proposed method can effectively replace traditional chunk-based action heads for both specialist and generalist policies. AR-VLA exhibits superior history awareness and substantially smoother action trajectories while maintaining or exceeding the task success rates of state-of-the-art reactive VLAs. Overall, our work introduces a scalable, context-aware action generation schema that provides a robust structural foundation for training effective robotic policies.
Scaling Data Science Solutions with Semantics and Machine Learning: Bosch Case
Aug 02, 2023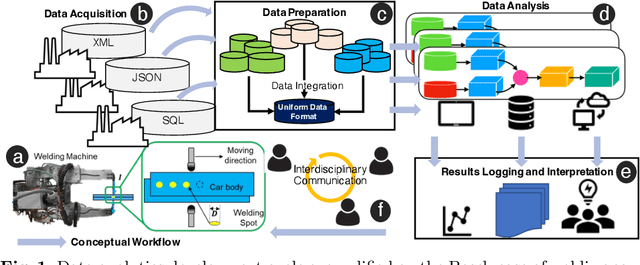
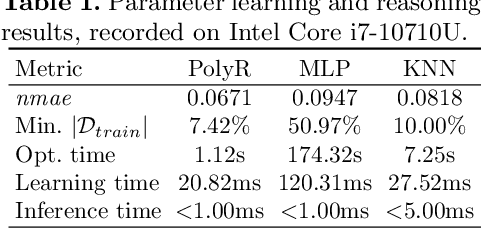
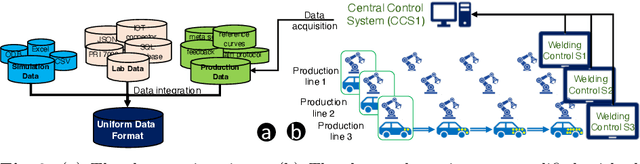
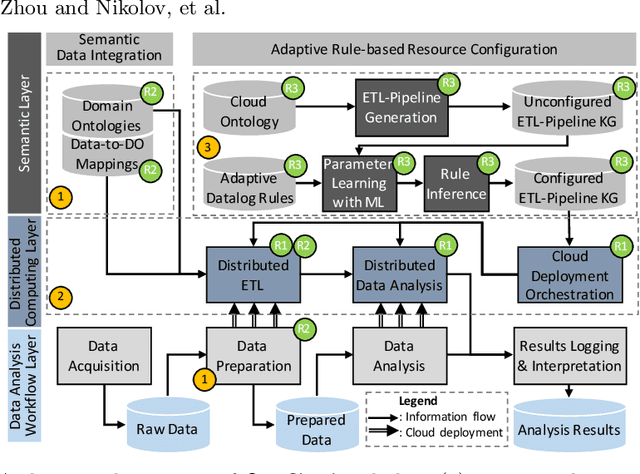
Industry 4.0 and Internet of Things (IoT) technologies unlock unprecedented amount of data from factory production, posing big data challenges in volume and variety. In that context, distributed computing solutions such as cloud systems are leveraged to parallelise the data processing and reduce computation time. As the cloud systems become increasingly popular, there is increased demand that more users that were originally not cloud experts (such as data scientists, domain experts) deploy their solutions on the cloud systems. However, it is non-trivial to address both the high demand for cloud system users and the excessive time required to train them. To this end, we propose SemCloud, a semantics-enhanced cloud system, that couples cloud system with semantic technologies and machine learning. SemCloud relies on domain ontologies and mappings for data integration, and parallelises the semantic data integration and data analysis on distributed computing nodes. Furthermore, SemCloud adopts adaptive Datalog rules and machine learning for automated resource configuration, allowing non-cloud experts to use the cloud system. The system has been evaluated in industrial use case with millions of data, thousands of repeated runs, and domain users, showing promising results.
Hybrid Constructions of Binary Sequences with Low Autocorrelation Sidelobes
Apr 21, 2021

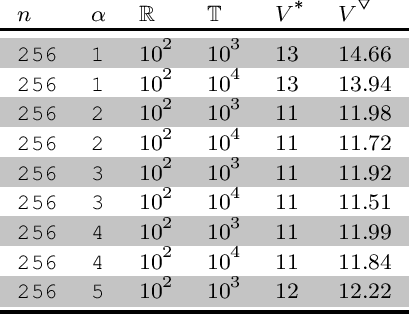
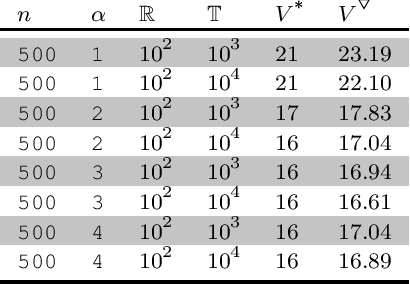
In this work, a classical problem of the digital sequence design, or more precisely, finding binary sequences with optimal peak sidelobe level (PSL), is revisited. By combining some of our previous works, together with some mathematical insights, few hybrid heuristic algorithms were created. During our experiments, and by using the aforementioned algorithms, we were able to find PSL-optimal binary sequences for all those lengths, which were previously found during exhaustive searches by various papers throughout the literature. Then, by using a general-purpose computer, we further demonstrate the effectiveness of the proposed algorithms by revealing binary sequences with lengths between 106 and 300, the majority of which possess record-breaking PSL values. Then, by using some well-known algebraic constructions, we outline few strategies for finding highly competitive binary sequences, which could be efficiently optimized, in terms of PSL, by the proposed algorithms.
On the Generation of Long Binary Sequences with Record-Breaking PSL Values
Apr 02, 2021
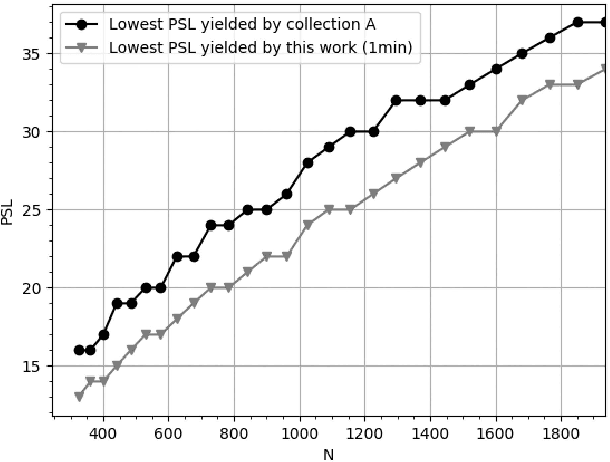
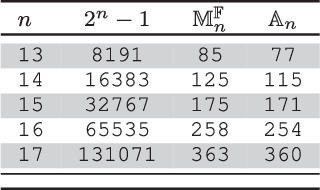
Binary sequences are widely used in various practical fields, such as telecommunications, radar technology, navigation, cryptography, measurement sciences, biology or industry. In this paper, a method to generate long binary sequences (LBS) with low peak sidelobe level (PSL) value is proposed. Having an LBS with length $n$, both the time and memory complexities of the proposed algorithm are $\mathcal{O}(n)$. During our experiments, we repeatedly reach better PSL values than the currently known state of art constructions, such as Legendre sequences, with or without rotations, Rudin-Shapiro sequences or m-sequences, with or without rotations, by always reaching a record-breaking PSL values strictly less than $\sqrt{n}$. Furthermore, the efficiency and simplicity of the proposed method are particularly beneficial to the lightweightness of the implementation, which allowed us to reach record-breaking PSL values for less than a second.
Urban Driving with Conditional Imitation Learning
Dec 05, 2019



Hand-crafting generalised decision-making rules for real-world urban autonomous driving is hard. Alternatively, learning behaviour from easy-to-collect human driving demonstrations is appealing. Prior work has studied imitation learning (IL) for autonomous driving with a number of limitations. Examples include only performing lane-following rather than following a user-defined route, only using a single camera view or heavily cropped frames lacking state observability, only lateral (steering) control, but not longitudinal (speed) control and a lack of interaction with traffic. Importantly, the majority of such systems have been primarily evaluated in simulation - a simple domain, which lacks real-world complexities. Motivated by these challenges, we focus on learning representations of semantics, geometry and motion with computer vision for IL from human driving demonstrations. As our main contribution, we present an end-to-end conditional imitation learning approach, combining both lateral and longitudinal control on a real vehicle for following urban routes with simple traffic. We address inherent dataset bias by data balancing, training our final policy on approximately 30 hours of demonstrations gathered over six months. We evaluate our method on an autonomous vehicle by driving 35km of novel routes in European urban streets.
Information-Directed Exploration for Deep Reinforcement Learning
Dec 18, 2018
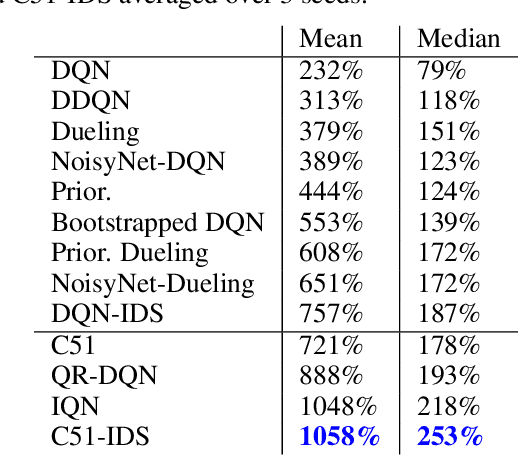
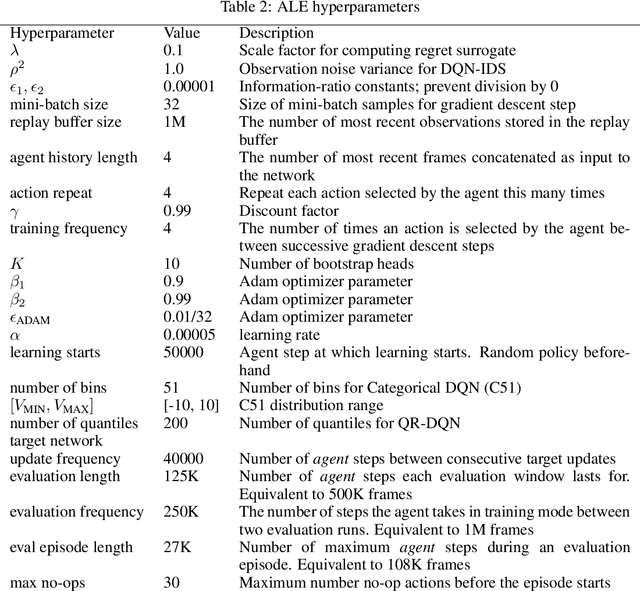
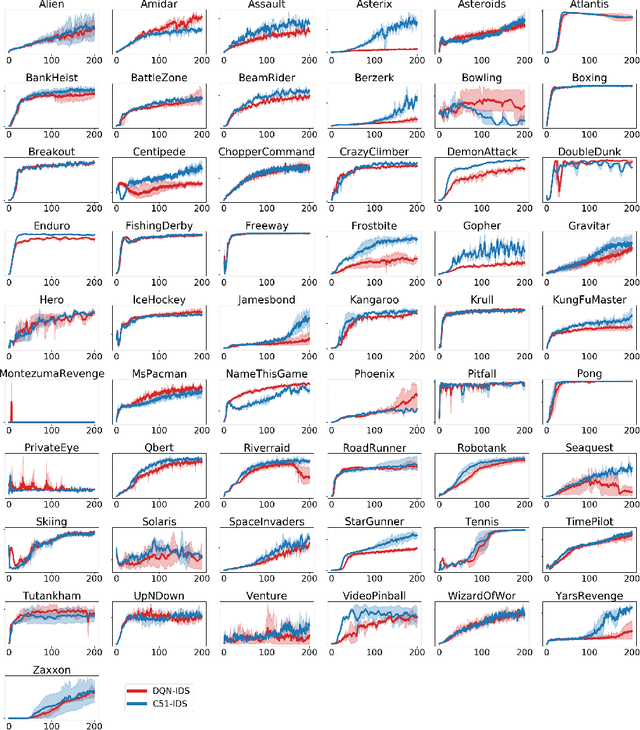
Efficient exploration remains a major challenge for reinforcement learning. One reason is that the variability of the returns often depends on the current state and action, and is therefore heteroscedastic. Classical exploration strategies such as upper confidence bound algorithms and Thompson sampling fail to appropriately account for heteroscedasticity, even in the bandit setting. Motivated by recent findings that address this issue in bandits, we propose to use Information-Directed Sampling (IDS) for exploration in reinforcement learning. As our main contribution, we build on recent advances in distributional reinforcement learning and propose a novel, tractable approximation of IDS for deep Q-learning. The resulting exploration strategy explicitly accounts for both parametric uncertainty and heteroscedastic observation noise. We evaluate our method on Atari games and demonstrate a significant improvement over alternative approaches.