 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeScaling Data Science Solutions with Semantics and Machine Learning: Bosch Case
Aug 02, 2023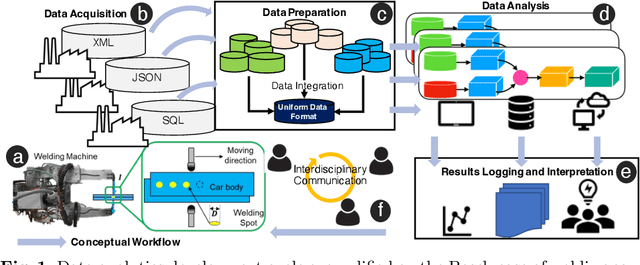
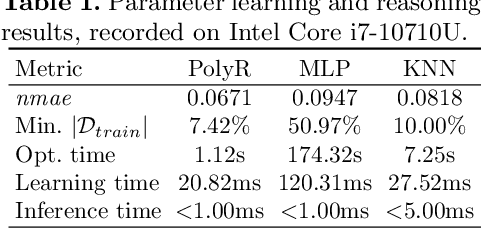
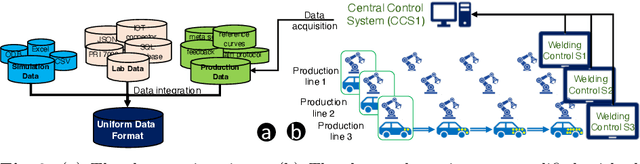
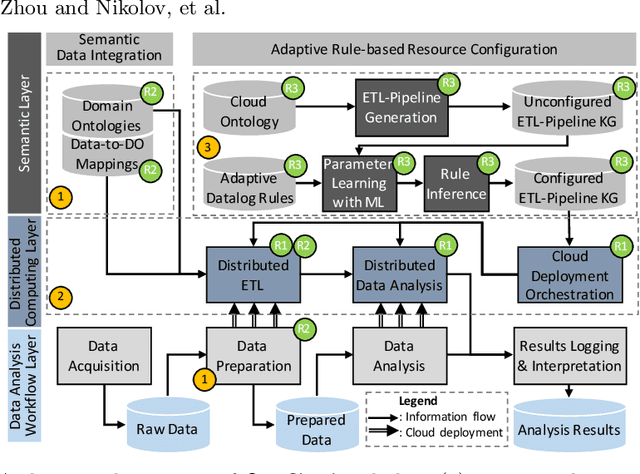
Industry 4.0 and Internet of Things (IoT) technologies unlock unprecedented amount of data from factory production, posing big data challenges in volume and variety. In that context, distributed computing solutions such as cloud systems are leveraged to parallelise the data processing and reduce computation time. As the cloud systems become increasingly popular, there is increased demand that more users that were originally not cloud experts (such as data scientists, domain experts) deploy their solutions on the cloud systems. However, it is non-trivial to address both the high demand for cloud system users and the excessive time required to train them. To this end, we propose SemCloud, a semantics-enhanced cloud system, that couples cloud system with semantic technologies and machine learning. SemCloud relies on domain ontologies and mappings for data integration, and parallelises the semantic data integration and data analysis on distributed computing nodes. Furthermore, SemCloud adopts adaptive Datalog rules and machine learning for automated resource configuration, allowing non-cloud experts to use the cloud system. The system has been evaluated in industrial use case with millions of data, thousands of repeated runs, and domain users, showing promising results.
More Information Supervised Probabilistic Deep Face Embedding Learning
Jun 11, 2020

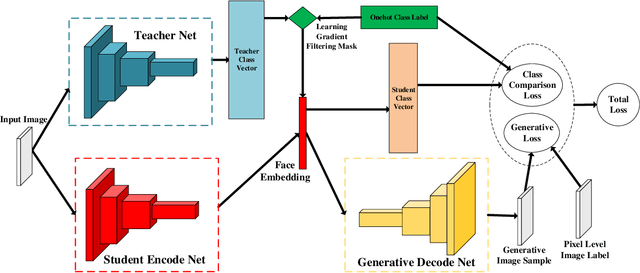

Researches using margin based comparison loss demonstrate the effectiveness of penalizing the distance between face feature and their corresponding class centers. Despite their popularity and excellent performance, they do not explicitly encourage the generic embedding learning for an open set recognition problem. In this paper, we analyse margin based softmax loss in probability view. With this perspective, we propose two general principles: 1) monotonic decreasing and 2) margin probability penalty, for designing new margin loss functions. Unlike methods optimized with single comparison metric, we provide a new perspective to treat open set face recognition as a problem of information transmission. And the generalization capability for face embedding is gained with more clean information. An auto-encoder architecture called Linear-Auto-TS-Encoder(LATSE) is proposed to corroborate this finding. Extensive experiments on several benchmarks demonstrate that LATSE help face embedding to gain more generalization capability and it boosted the single model performance with open training dataset to more than $99\%$ on MegaFace test.
Maximum Margin Principal Components
May 17, 2017
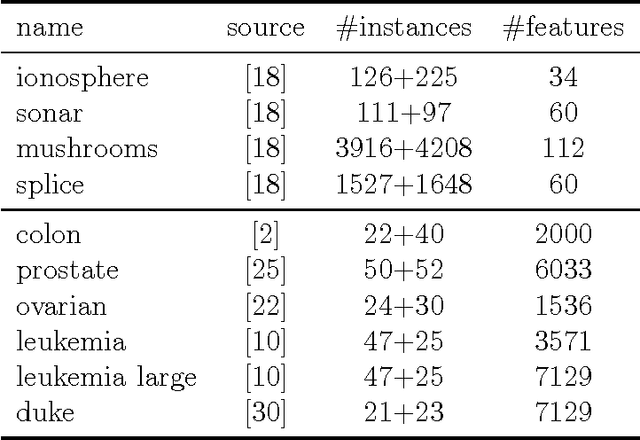

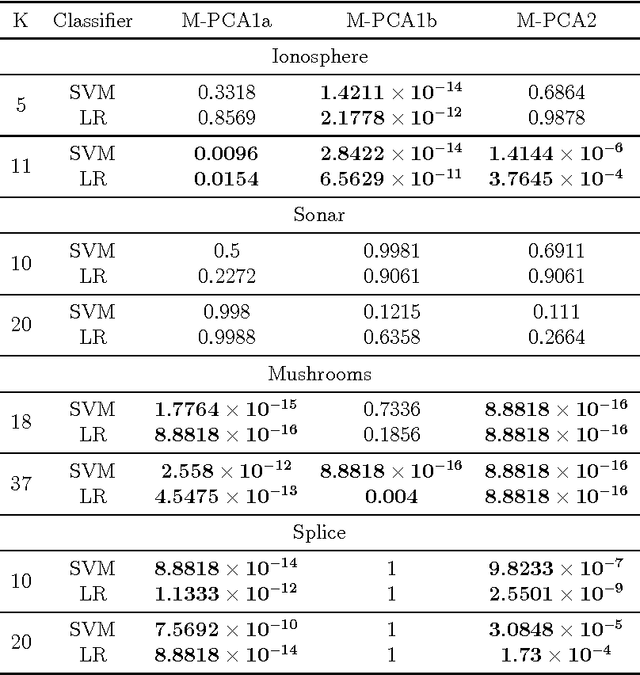
Principal Component Analysis (PCA) is a very successful dimensionality reduction technique, widely used in predictive modeling. A key factor in its widespread use in this domain is the fact that the projection of a dataset onto its first $K$ principal components minimizes the sum of squared errors between the original data and the projected data over all possible rank $K$ projections. Thus, PCA provides optimal low-rank representations of data for least-squares linear regression under standard modeling assumptions. On the other hand, when the loss function for a prediction problem is not the least-squares error, PCA is typically a heuristic choice of dimensionality reduction -- in particular for classification problems under the zero-one loss. In this paper we target classification problems by proposing a straightforward alternative to PCA that aims to minimize the difference in margin distribution between the original and the projected data. Extensive experiments show that our simple approach typically outperforms PCA on any particular dataset, in terms of classification error, though this difference is not always statistically significant, and despite being a filter method is frequently competitive with Partial Least Squares (PLS) and Lasso on a wide range of datasets.