 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeClinEnv: An Interactive Multi-Stage Long Horizon EHR Environment for Agents
Jun 01, 2026Clinical practice is not the selection of an answer from enumerated options: a physician gathers heterogeneous information incrementally and commits to sequential, irreversible decisions under uncertainty. Static benchmarks cannot probe and existing interactive medical benchmarks each compromise on at least one of them. We present ClinEnv, an interactive benchmark that evaluates LLMs as attending physicians over real inpatient admissions under a paradigm we term Longitudinal Inpatient Simulation. Each case is automatically constructed into an ordered sequence of decision stages; at every stage the model must actively query four specialized agents before committing to medications, procedures, and diagnoses. ClinEnv scores both what the model decides, through deterministic ontology-grounded matching, and how it gathers information. Across seven models, the strongest reaches only 0.31 decision F1, and outcome quality is sharply decoupled from process quality. Difficulty concentrates in management decisions and later stages, where models recover discharge diagnoses far more reliably than management actions (0.51 vs. 0.17 F1) and continue to issue redundant queries as cases progress. ClinEnv makes this information-acquisition gap, invisible to outcome-only evaluation, directly measurable.
Test Time Training for Supervised Causal Learning
May 28, 2026Supervised Causal Learning (SCL) has shown promise in causal discovery by framing it as a supervised learning problem. However, it suffers from significant out-of-distribution generalization challenges. We reveal three limitations of previous SCL practices: a significant performance gap between synthetic benchmarks and real-world data, fragility to distribution shifts, and failure in compositional generalization, collectively questioning its real-world applicability. To address this, we propose Test-Time Training for Supervised Causal Learning (TTT-SCL), a novel framework that dynamically generates training sets explicitly aligned with any specific test instance. We demonstrate the correlation between TTT-SCL and score-based methods, and design an efficient module for generating training sets based on the classic scoring function. Experiments on synthetic benchmarks, pseudo-real and real-world datasets demonstrate that TTT-SCL significantly outperforms existing SCL and traditional causal discovery methods.
Training the Knowledge Base through Evidence Distillation and Write-Back Enrichment
Mar 26, 2026The knowledge base in a retrieval-augmented generation (RAG) system is typically assembled once and never revised, even though the facts a query requires are often fragmented across documents and buried in irrelevant content. We argue that the knowledge base should be treated as a trainable component and propose WriteBack-RAG, a framework that uses labeled examples to identify where retrieval succeeds, isolate the relevant documents, and distill them into compact knowledge units that are indexed alongside the original corpus. Because the method modifies only the corpus, it can be applied once as an offline preprocessing step and combined with any RAG pipeline. Across four RAG methods, six benchmarks, and two LLM backbones, WriteBack-RAG improves every evaluated setting, with gains averaging +2.14%. Cross-method transfer experiments further show that the distilled knowledge benefits RAG pipelines other than the one used to produce it, confirming that the improvement resides in the corpus itself.
LLM-as-RNN: A Recurrent Language Model for Memory Updates and Sequence Prediction
Jan 19, 2026Large language models are strong sequence predictors, yet standard inference relies on immutable context histories. After making an error at generation step t, the model lacks an updatable memory mechanism that improves predictions for step t+1. We propose LLM-as-RNN, an inference-only framework that turns a frozen LLM into a recurrent predictor by representing its hidden state as natural-language memory. This state, implemented as a structured system-prompt summary, is updated at each timestep via feedback-driven text rewrites, enabling learning without parameter updates. Under a fixed token budget, LLM-as-RNN corrects errors and retains task-relevant patterns, effectively performing online learning through language. We evaluate the method on three sequential benchmarks in healthcare, meteorology, and finance across Llama, Gemma, and GPT model families. LLM-as-RNN significantly outperforms zero-shot, full-history, and MemPrompt baselines, improving predictive accuracy by 6.5% on average, while producing interpretable, human-readable learning traces absent in standard context accumulation.
DoctorRAG: Medical RAG Fusing Knowledge with Patient Analogy through Textual Gradients
May 26, 2025Existing medical RAG systems mainly leverage knowledge from medical knowledge bases, neglecting the crucial role of experiential knowledge derived from similar patient cases -- a key component of human clinical reasoning. To bridge this gap, we propose DoctorRAG, a RAG framework that emulates doctor-like reasoning by integrating both explicit clinical knowledge and implicit case-based experience. DoctorRAG enhances retrieval precision by first allocating conceptual tags for queries and knowledge sources, together with a hybrid retrieval mechanism from both relevant knowledge and patient. In addition, a Med-TextGrad module using multi-agent textual gradients is integrated to ensure that the final output adheres to the retrieved knowledge and patient query. Comprehensive experiments on multilingual, multitask datasets demonstrate that DoctorRAG significantly outperforms strong baseline RAG models and gains improvements from iterative refinements. Our approach generates more accurate, relevant, and comprehensive responses, taking a step towards more doctor-like medical reasoning systems.
Any-to-Any Learning in Computational Pathology via Triplet Multimodal Pretraining
May 19, 2025



Recent advances in computational pathology and artificial intelligence have significantly enhanced the utilization of gigapixel whole-slide images and and additional modalities (e.g., genomics) for pathological diagnosis. Although deep learning has demonstrated strong potential in pathology, several key challenges persist: (1) fusing heterogeneous data types requires sophisticated strategies beyond simple concatenation due to high computational costs; (2) common scenarios of missing modalities necessitate flexible strategies that allow the model to learn robustly in the absence of certain modalities; (3) the downstream tasks in CPath are diverse, ranging from unimodal to multimodal, cnecessitating a unified model capable of handling all modalities. To address these challenges, we propose ALTER, an any-to-any tri-modal pretraining framework that integrates WSIs, genomics, and pathology reports. The term "any" emphasizes ALTER's modality-adaptive design, enabling flexible pretraining with any subset of modalities, and its capacity to learn robust, cross-modal representations beyond WSI-centric approaches. We evaluate ALTER across extensive clinical tasks including survival prediction, cancer subtyping, gene mutation prediction, and report generation, achieving superior or comparable performance to state-of-the-art baselines.
Comprehensive Manuscript Assessment with Text Summarization Using 69707 articles
Mar 26, 2025



Rapid and efficient assessment of the future impact of research articles is a significant concern for both authors and reviewers. The most common standard for measuring the impact of academic papers is the number of citations. In recent years, numerous efforts have been undertaken to predict citation counts within various citation windows. However, most of these studies focus solely on a specific academic field or require early citation counts for prediction, rendering them impractical for the early-stage evaluation of papers. In this work, we harness Scopus to curate a significantly comprehensive and large-scale dataset of information from 69707 scientific articles sourced from 99 journals spanning multiple disciplines. We propose a deep learning methodology for the impact-based classification tasks, which leverages semantic features extracted from the manuscripts and paper metadata. To summarize the semantic features, such as titles and abstracts, we employ a Transformer-based language model to encode semantic features and design a text fusion layer to capture shared information between titles and abstracts. We specifically focus on the following impact-based prediction tasks using information of scientific manuscripts in pre-publication stage: (1) The impact of journals in which the manuscripts will be published. (2) The future impact of manuscripts themselves. Extensive experiments on our datasets demonstrate the superiority of our proposed model for impact-based prediction tasks. We also demonstrate potentials in generating manuscript's feedback and improvement suggestions.
KARMA: Leveraging Multi-Agent LLMs for Automated Knowledge Graph Enrichment
Feb 10, 2025
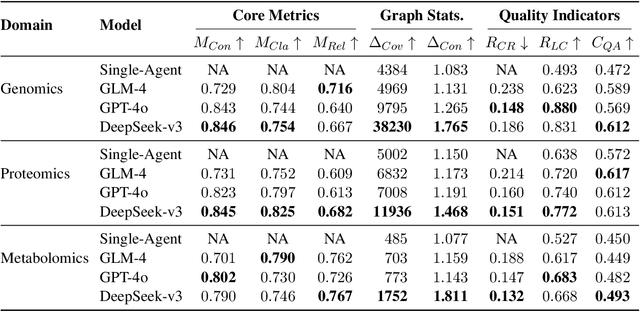
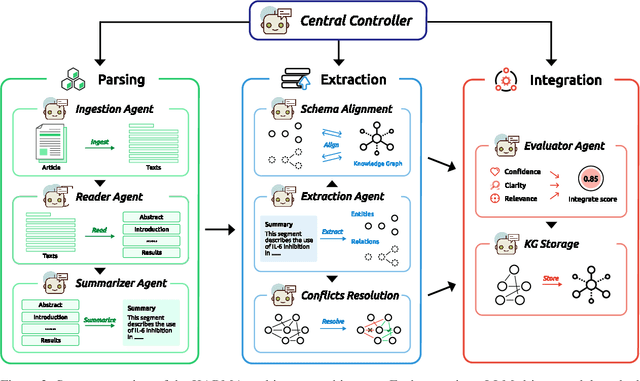
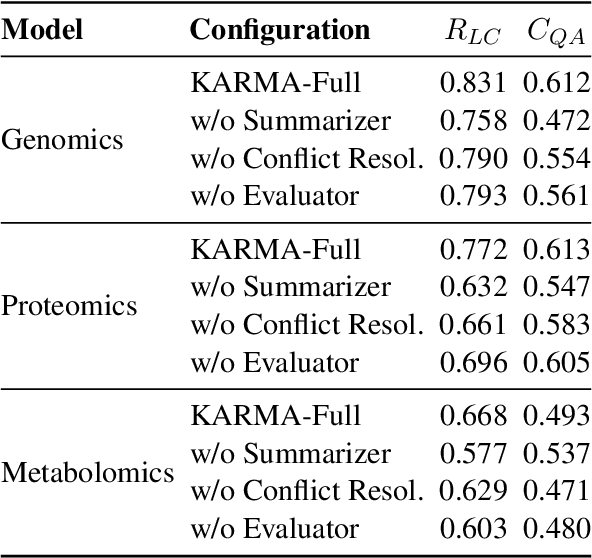
Maintaining comprehensive and up-to-date knowledge graphs (KGs) is critical for modern AI systems, but manual curation struggles to scale with the rapid growth of scientific literature. This paper presents KARMA, a novel framework employing multi-agent large language models (LLMs) to automate KG enrichment through structured analysis of unstructured text. Our approach employs nine collaborative agents, spanning entity discovery, relation extraction, schema alignment, and conflict resolution that iteratively parse documents, verify extracted knowledge, and integrate it into existing graph structures while adhering to domain-specific schema. Experiments on 1,200 PubMed articles from three different domains demonstrate the effectiveness of KARMA in knowledge graph enrichment, with the identification of up to 38,230 new entities while achieving 83.1\% LLM-verified correctness and reducing conflict edges by 18.6\% through multi-layer assessments.
Context Matters: Query-aware Dynamic Long Sequence Modeling of Gigapixel Images
Jan 31, 2025Whole slide image (WSI) analysis presents significant computational challenges due to the massive number of patches in gigapixel images. While transformer architectures excel at modeling long-range correlations through self-attention, their quadratic computational complexity makes them impractical for computational pathology applications. Existing solutions like local-global or linear self-attention reduce computational costs but compromise the strong modeling capabilities of full self-attention. In this work, we propose Querent, i.e., the query-aware long contextual dynamic modeling framework, which maintains the expressive power of full self-attention while achieving practical efficiency. Our method adaptively predicts which surrounding regions are most relevant for each patch, enabling focused yet unrestricted attention computation only with potentially important contexts. By using efficient region-wise metadata computation and importance estimation, our approach dramatically reduces computational overhead while preserving global perception to model fine-grained patch correlations. Through comprehensive experiments on biomarker prediction, gene mutation prediction, cancer subtyping, and survival analysis across over 10 WSI datasets, our method demonstrates superior performance compared to the state-of-the-art approaches. Code will be made available at https://github.com/dddavid4real/Querent.
Biomedical Knowledge Graph: A Survey of Domains, Tasks, and Real-World Applications
Jan 20, 2025



Biomedical knowledge graphs (BKGs) have emerged as powerful tools for organizing and leveraging the vast and complex data found across the biomedical field. Yet, current reviews of BKGs often limit their scope to specific domains or methods, overlooking the broader landscape and the rapid technological progress reshaping it. In this survey, we address this gap by offering a systematic review of BKGs from three core perspectives: domains, tasks, and applications. We begin by examining how BKGs are constructed from diverse data sources, including molecular interactions, pharmacological datasets, and clinical records. Next, we discuss the essential tasks enabled by BKGs, focusing on knowledge management, retrieval, reasoning, and interpretation. Finally, we highlight real-world applications in precision medicine, drug discovery, and scientific research, illustrating the translational impact of BKGs across multiple sectors. By synthesizing these perspectives into a unified framework, this survey not only clarifies the current state of BKG research but also establishes a foundation for future exploration, enabling both innovative methodological advances and practical implementations.