 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDyTopo: Dynamic Topology Routing for Multi-Agent Reasoning via Semantic Matching
Feb 05, 2026Multi-agent systems built from prompted large language models can improve multi-round reasoning, yet most existing pipelines rely on fixed, trajectory-wide communication patterns that are poorly matched to the stage-dependent needs of iterative problem solving. We introduce DyTopo, a manager-guided multi-agent framework that reconstructs a sparse directed communication graph at each round. Conditioned on the manager's round goal, each agent outputs lightweight natural-language query (need) and \key (offer) descriptors; DyTopo embeds these descriptors and performs semantic matching, routing private messages only along the induced edges. Across code generation and mathematical reasoning benchmarks and four LLM backbones, DyTopo consistently outperforms over the strongest baseline (avg. +6.2). Beyond accuracy, DyTopo yields an interpretable coordination trace via the evolving graphs, enabling qualitative inspection of how communication pathways reconfigure across rounds.
LLM-as-RNN: A Recurrent Language Model for Memory Updates and Sequence Prediction
Jan 19, 2026Large language models are strong sequence predictors, yet standard inference relies on immutable context histories. After making an error at generation step t, the model lacks an updatable memory mechanism that improves predictions for step t+1. We propose LLM-as-RNN, an inference-only framework that turns a frozen LLM into a recurrent predictor by representing its hidden state as natural-language memory. This state, implemented as a structured system-prompt summary, is updated at each timestep via feedback-driven text rewrites, enabling learning without parameter updates. Under a fixed token budget, LLM-as-RNN corrects errors and retains task-relevant patterns, effectively performing online learning through language. We evaluate the method on three sequential benchmarks in healthcare, meteorology, and finance across Llama, Gemma, and GPT model families. LLM-as-RNN significantly outperforms zero-shot, full-history, and MemPrompt baselines, improving predictive accuracy by 6.5% on average, while producing interpretable, human-readable learning traces absent in standard context accumulation.
MEDVISTAGYM: A Scalable Training Environment for Thinking with Medical Images via Tool-Integrated Reinforcement Learning
Jan 12, 2026Vision language models (VLMs) achieve strong performance on general image understanding but struggle to think with medical images, especially when performing multi-step reasoning through iterative visual interaction. Medical VLMs often rely on static visual embeddings and single-pass inference, preventing models from re-examining, verifying, or refining visual evidence during reasoning. While tool-integrated reasoning offers a promising path forward, open-source VLMs lack the training infrastructure to learn effective tool selection, invocation, and coordination in multi-modal medical reasoning. We introduce MedVistaGym, a scalable and interactive training environment that incentivizes tool-integrated visual reasoning for medical image analysis. MedVistaGym equips VLMs to determine when and which tools to invoke, localize task-relevant image regions, and integrate single or multiple sub-image evidence into interleaved multimodal reasoning within a unified, executable interface for agentic training. Using MedVistaGym, we train MedVistaGym-R1 to interleave tool use with agentic reasoning through trajectory sampling and end-to-end reinforcement learning. Across six medical VQA benchmarks, MedVistaGym-R1-8B exceeds comparably sized tool-augmented baselines by 19.10% to 24.21%, demonstrating that structured agentic training--not tool access alone--unlocks effective tool-integrated reasoning for medical image analysis.
DoctorRAG: Medical RAG Fusing Knowledge with Patient Analogy through Textual Gradients
May 26, 2025Existing medical RAG systems mainly leverage knowledge from medical knowledge bases, neglecting the crucial role of experiential knowledge derived from similar patient cases -- a key component of human clinical reasoning. To bridge this gap, we propose DoctorRAG, a RAG framework that emulates doctor-like reasoning by integrating both explicit clinical knowledge and implicit case-based experience. DoctorRAG enhances retrieval precision by first allocating conceptual tags for queries and knowledge sources, together with a hybrid retrieval mechanism from both relevant knowledge and patient. In addition, a Med-TextGrad module using multi-agent textual gradients is integrated to ensure that the final output adheres to the retrieved knowledge and patient query. Comprehensive experiments on multilingual, multitask datasets demonstrate that DoctorRAG significantly outperforms strong baseline RAG models and gains improvements from iterative refinements. Our approach generates more accurate, relevant, and comprehensive responses, taking a step towards more doctor-like medical reasoning systems.
Comprehensive Manuscript Assessment with Text Summarization Using 69707 articles
Mar 26, 2025Rapid and efficient assessment of the future impact of research articles is a significant concern for both authors and reviewers. The most common standard for measuring the impact of academic papers is the number of citations. In recent years, numerous efforts have been undertaken to predict citation counts within various citation windows. However, most of these studies focus solely on a specific academic field or require early citation counts for prediction, rendering them impractical for the early-stage evaluation of papers. In this work, we harness Scopus to curate a significantly comprehensive and large-scale dataset of information from 69707 scientific articles sourced from 99 journals spanning multiple disciplines. We propose a deep learning methodology for the impact-based classification tasks, which leverages semantic features extracted from the manuscripts and paper metadata. To summarize the semantic features, such as titles and abstracts, we employ a Transformer-based language model to encode semantic features and design a text fusion layer to capture shared information between titles and abstracts. We specifically focus on the following impact-based prediction tasks using information of scientific manuscripts in pre-publication stage: (1) The impact of journals in which the manuscripts will be published. (2) The future impact of manuscripts themselves. Extensive experiments on our datasets demonstrate the superiority of our proposed model for impact-based prediction tasks. We also demonstrate potentials in generating manuscript's feedback and improvement suggestions.
KARMA: Leveraging Multi-Agent LLMs for Automated Knowledge Graph Enrichment
Feb 10, 2025
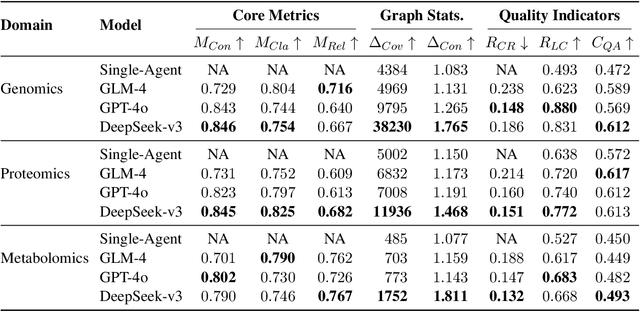
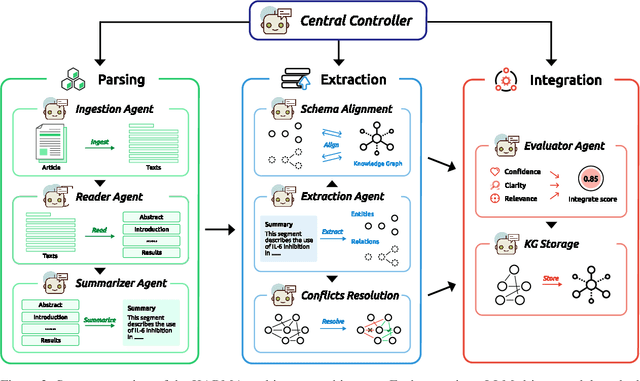
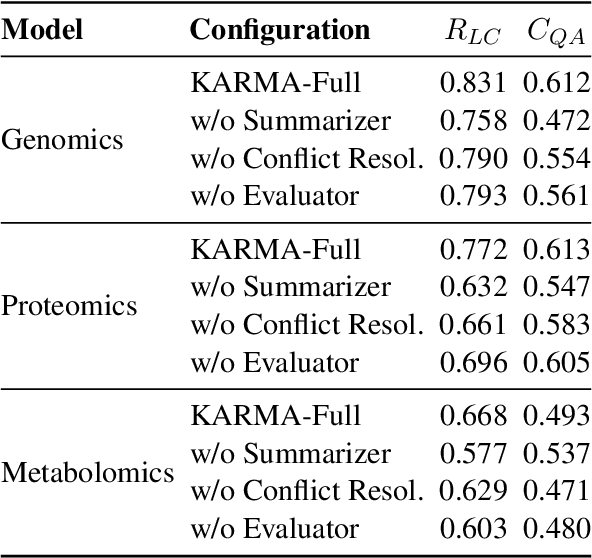
Maintaining comprehensive and up-to-date knowledge graphs (KGs) is critical for modern AI systems, but manual curation struggles to scale with the rapid growth of scientific literature. This paper presents KARMA, a novel framework employing multi-agent large language models (LLMs) to automate KG enrichment through structured analysis of unstructured text. Our approach employs nine collaborative agents, spanning entity discovery, relation extraction, schema alignment, and conflict resolution that iteratively parse documents, verify extracted knowledge, and integrate it into existing graph structures while adhering to domain-specific schema. Experiments on 1,200 PubMed articles from three different domains demonstrate the effectiveness of KARMA in knowledge graph enrichment, with the identification of up to 38,230 new entities while achieving 83.1\% LLM-verified correctness and reducing conflict edges by 18.6\% through multi-layer assessments.
Biomedical Knowledge Graph: A Survey of Domains, Tasks, and Real-World Applications
Jan 20, 2025



Biomedical knowledge graphs (BKGs) have emerged as powerful tools for organizing and leveraging the vast and complex data found across the biomedical field. Yet, current reviews of BKGs often limit their scope to specific domains or methods, overlooking the broader landscape and the rapid technological progress reshaping it. In this survey, we address this gap by offering a systematic review of BKGs from three core perspectives: domains, tasks, and applications. We begin by examining how BKGs are constructed from diverse data sources, including molecular interactions, pharmacological datasets, and clinical records. Next, we discuss the essential tasks enabled by BKGs, focusing on knowledge management, retrieval, reasoning, and interpretation. Finally, we highlight real-world applications in precision medicine, drug discovery, and scientific research, illustrating the translational impact of BKGs across multiple sectors. By synthesizing these perspectives into a unified framework, this survey not only clarifies the current state of BKG research but also establishes a foundation for future exploration, enabling both innovative methodological advances and practical implementations.
END$^2$: Robust Dual-Decoder Watermarking Framework Against Non-Differentiable Distortions
Dec 13, 2024DNN-based watermarking methods have rapidly advanced, with the ``Encoder-Noise Layer-Decoder'' (END) framework being the most widely used. To ensure end-to-end training, the noise layer in the framework must be differentiable. However, real-world distortions are often non-differentiable, leading to challenges in end-to-end training. Existing solutions only treat the distortion perturbation as additive noise, which does not fully integrate the effect of distortion in training. To better incorporate non-differentiable distortions into training, we propose a novel dual-decoder architecture (END$^2$). Unlike conventional END architecture, our method employs two structurally identical decoders: the Teacher Decoder, processing pure watermarked images, and the Student Decoder, handling distortion-perturbed images. The gradient is backpropagated only through the Teacher Decoder branch to optimize the encoder thus bypassing the problem of non-differentiability. To ensure resistance to arbitrary distortions, we enforce alignment of the two decoders' feature representations by maximizing the cosine similarity between their intermediate vectors on a hypersphere. Extensive experiments demonstrate that our scheme outperforms state-of-the-art algorithms under various non-differentiable distortions. Moreover, even without the differentiability constraint, our method surpasses baselines with a differentiable noise layer. Our approach is effective and easily implementable across all END architectures, enhancing practicality and generalizability.
Ask1: Development and Reinforcement Learning-Based Control of a Custom Quadruped Robot
Dec 11, 2024



In this work, we present the design, development, and experimental validation of a custom-built quadruped robot, Ask1. The Ask1 robot shares similar morphology with the Unitree Go1, but features custom hardware components and a different control architecture. We transfer and extend previous reinforcement learning (RL)-based control methods to the Ask1 robot, demonstrating the applicability of our approach in real-world scenarios. By eliminating the need for Adversarial Motion Priors (AMP) and reference trajectories, we introduce a novel reward function to guide the robot's motion style. We demonstrate the generalization capability of the proposed RL algorithm by training it on both the Go1 and Ask1 robots. Simulation and real-world experiments validate the effectiveness of this method, showing that Ask1, like the Go1, is capable of navigating various rugged terrains.
RAG and RAU: A Survey on Retrieval-Augmented Language Model in Natural Language Processing
Apr 30, 2024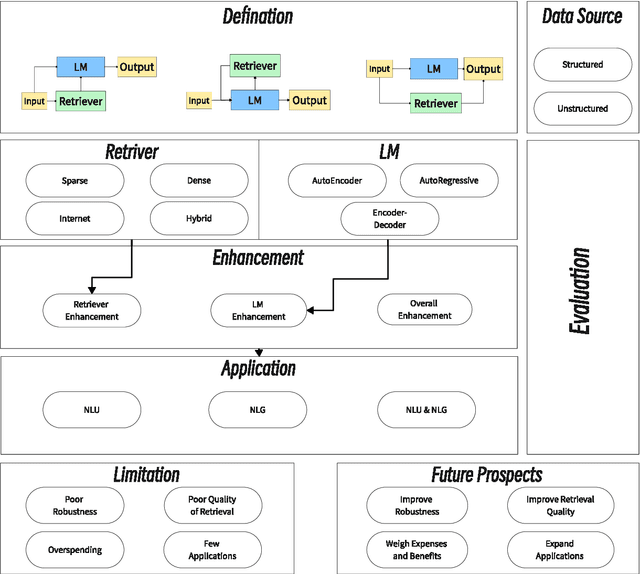



Large Language Models (LLMs) have catalyzed significant advancements in Natural Language Processing (NLP), yet they encounter challenges such as hallucination and the need for domain-specific knowledge. To mitigate these, recent methodologies have integrated information retrieved from external resources with LLMs, substantially enhancing their performance across NLP tasks. This survey paper addresses the absence of a comprehensive overview on Retrieval-Augmented Language Models (RALMs), both Retrieval-Augmented Generation (RAG) and Retrieval-Augmented Understanding (RAU), providing an in-depth examination of their paradigm, evolution, taxonomy, and applications. The paper discusses the essential components of RALMs, including Retrievers, Language Models, and Augmentations, and how their interactions lead to diverse model structures and applications. RALMs demonstrate utility in a spectrum of tasks, from translation and dialogue systems to knowledge-intensive applications. The survey includes several evaluation methods of RALMs, emphasizing the importance of robustness, accuracy, and relevance in their assessment. It also acknowledges the limitations of RALMs, particularly in retrieval quality and computational efficiency, offering directions for future research. In conclusion, this survey aims to offer a structured insight into RALMs, their potential, and the avenues for their future development in NLP. The paper is supplemented with a Github Repository containing the surveyed works and resources for further study: https://github.com/2471023025/RALM_Survey.