 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFlash-VAED: Plug-and-Play VAE Decoders for Efficient Video Generation
Feb 22, 2026Latent diffusion models have enabled high-quality video synthesis, yet their inference remains costly and time-consuming. As diffusion transformers become increasingly efficient, the latency bottleneck inevitably shifts to VAE decoders. To reduce their latency while maintaining quality, we propose a universal acceleration framework for VAE decoders that preserves full alignment with the original latent distribution. Specifically, we propose (1) an independence-aware channel pruning method to effectively mitigate severe channel redundancy, and (2) a stage-wise dominant operator optimization strategy to address the high inference cost of the widely used causal 3D convolutions in VAE decoders. Based on these innovations, we construct a Flash-VAED family. Moreover, we design a three-phase dynamic distillation framework that efficiently transfers the capabilities of the original VAE decoder to Flash-VAED. Extensive experiments on Wan and LTX-Video VAE decoders demonstrate that our method outperforms baselines in both quality and speed, achieving approximately a 6$\times$ speedup while maintaining the reconstruction performance up to 96.9%. Notably, Flash-VAED accelerates the end-to-end generation pipeline by up to 36% with negligible quality drops on VBench-2.0.
Scalable and General Whole-Body Control for Cross-Humanoid Locomotion
Feb 05, 2026Learning-based whole-body controllers have become a key driver for humanoid robots, yet most existing approaches require robot-specific training. In this paper, we study the problem of cross-embodiment humanoid control and show that a single policy can robustly generalize across a wide range of humanoid robot designs with one-time training. We introduce XHugWBC, a novel cross-embodiment training framework that enables generalist humanoid control through: (1) physics-consistent morphological randomization, (2) semantically aligned observation and action spaces across diverse humanoid robots, and (3) effective policy architectures modeling morphological and dynamical properties. XHugWBC is not tied to any specific robot. Instead, it internalizes a broad distribution of morphological and dynamical characteristics during training. By learning motion priors from diverse randomized embodiments, the policy acquires a strong structural bias that supports zero-shot transfer to previously unseen robots. Experiments on twelve simulated humanoids and seven real-world robots demonstrate the strong generalization and robustness of the resulting universal controller.
Embodiment-Aware Generalist Specialist Distillation for Unified Humanoid Whole-Body Control
Feb 03, 2026Humanoid Whole-Body Controllers trained with reinforcement learning (RL) have recently achieved remarkable performance, yet many target a single robot embodiment. Variations in dynamics, degrees of freedom (DoFs), and kinematic topology still hinder a single policy from commanding diverse humanoids. Moreover, obtaining a generalist policy that not only transfers across embodiments but also supports richer behaviors-beyond simple walking to squatting, leaning-remains especially challenging. In this work, we tackle these obstacles by introducing EAGLE, an iterative generalist-specialist distillation framework that produces a single unified policy that controls multiple heterogeneous humanoids without per-robot reward tuning. During each cycle, embodiment-specific specialists are forked from the current generalist, refined on their respective robots, and new skills are distilled back into the generalist by training on the pooled embodiment set. Repeating this loop until performance convergence produces a robust Whole-Body Controller validated on robots such as Unitree H1, G1, and Fourier N1. We conducted experiments on five different robots in simulation and four in real-world settings. Through quantitative evaluations, EAGLE achieves high tracking accuracy and robustness compared to other methods, marking a step toward scalable, fleet-level humanoid control. See more details at https://eagle-wbc.github.io/
A Unified and General Humanoid Whole-Body Controller for Fine-Grained Locomotion
Feb 06, 2025Locomotion is a fundamental skill for humanoid robots. However, most existing works made locomotion a single, tedious, unextendable, and passive movement. This limits the kinematic capabilities of humanoid robots. In contrast, humans possess versatile athletic abilities-running, jumping, hopping, and finely adjusting walking parameters such as frequency, and foot height. In this paper, we investigate solutions to bring such versatility into humanoid locomotion and thereby propose HUGWBC: a unified and general humanoid whole-body controller for fine-grained locomotion. By designing a general command space in the aspect of tasks and behaviors, along with advanced techniques like symmetrical loss and intervention training for learning a whole-body humanoid controlling policy in simulation, HugWBC enables real-world humanoid robots to produce various natural gaits, including walking (running), jumping, standing, and hopping, with customizable parameters such as frequency, foot swing height, further combined with different body height, waist rotation, and body pitch, all in one single policy. Beyond locomotion, HUGWBC also supports real-time interventions from external upper-body controllers like teleoperation, enabling loco-manipulation while maintaining precise control under any locomotive behavior. Our experiments validate the high tracking accuracy and robustness of HUGWBC with/without upper-body intervention for all commands, and we further provide an in-depth analysis of how the various commands affect humanoid movement and offer insights into the relationships between these commands. To our knowledge, HugWBC is the first humanoid whole-body controller that supports such fine-grained locomotion behaviors with high robustness and flexibility.
Ask1: Development and Reinforcement Learning-Based Control of a Custom Quadruped Robot
Dec 11, 2024



In this work, we present the design, development, and experimental validation of a custom-built quadruped robot, Ask1. The Ask1 robot shares similar morphology with the Unitree Go1, but features custom hardware components and a different control architecture. We transfer and extend previous reinforcement learning (RL)-based control methods to the Ask1 robot, demonstrating the applicability of our approach in real-world scenarios. By eliminating the need for Adversarial Motion Priors (AMP) and reference trajectories, we introduce a novel reward function to guide the robot's motion style. We demonstrate the generalization capability of the proposed RL algorithm by training it on both the Go1 and Ask1 robots. Simulation and real-world experiments validate the effectiveness of this method, showing that Ask1, like the Go1, is capable of navigating various rugged terrains.
Experience-Learning Inspired Two-Step Reward Method for Efficient Legged Locomotion Learning Towards Natural and Robust Gaits
Jan 22, 2024



Multi-legged robots offer enhanced stability in complex terrains, yet autonomously learning natural and robust motions in such environments remains challenging. Drawing inspiration from animals' progressive learning patterns, from simple to complex tasks, we introduce a universal two-stage learning framework with two-step reward setting based on self-acquired experience, which efficiently enables legged robots to incrementally learn natural and robust movements. In the first stage, robots learn through gait-related rewards to track velocity on flat terrain, acquiring natural, robust movements and generating effective motion experience data. In the second stage, mirroring animal learning from existing experiences, robots learn to navigate challenging terrains with natural and robust movements using adversarial imitation learning. To demonstrate our method's efficacy, we trained both quadruped robots and a hexapod robot, and the policy were successfully transferred to a physical quadruped robot GO1, which exhibited natural gait patterns and remarkable robustness in various terrains.
Learning Multiple Gaits within Latent Space for Quadruped Robots
Aug 06, 2023



Learning multiple gaits is non-trivial for legged robots, especially when encountering different terrains and velocity commands. In this work, we present an end-to-end training framework for learning multiple gaits for quadruped robots, tailored to the needs of robust locomotion, agile locomotion, and user's commands. A latent space is constructed concurrently by a gait encoder and a gait generator, which helps the agent to reuse multiple gait skills to achieve adaptive gait behaviors. To learn natural behaviors for multiple gaits, we design gait-dependent rewards that are constructed explicitly from gait parameters and implicitly from conditional adversarial motion priors (CAMP). We demonstrate such multiple gaits control on a quadruped robot Go1 with only proprioceptive sensors.
CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X
Mar 30, 2023



Large pre-trained code generation models, such as OpenAI Codex, can generate syntax- and function-correct code, making the coding of programmers more productive and our pursuit of artificial general intelligence closer. In this paper, we introduce CodeGeeX, a multilingual model with 13 billion parameters for code generation. CodeGeeX is pre-trained on 850 billion tokens of 23 programming languages as of June 2022. Our extensive experiments suggest that CodeGeeX outperforms multilingual code models of similar scale for both the tasks of code generation and translation on HumanEval-X. Building upon HumanEval (Python only), we develop the HumanEval-X benchmark for evaluating multilingual models by hand-writing the solutions in C++, Java, JavaScript, and Go. In addition, we build CodeGeeX-based extensions on Visual Studio Code, JetBrains, and Cloud Studio, generating 4.7 billion tokens for tens of thousands of active users per week. Our user study demonstrates that CodeGeeX can help to increase coding efficiency for 83.4% of its users. Finally, CodeGeeX is publicly accessible and in Sep. 2022, we open-sourced its code, model weights (the version of 850B tokens), API, extensions, and HumanEval-X at https://github.com/THUDM/CodeGeeX.
GLM-130B: An Open Bilingual Pre-trained Model
Oct 05, 2022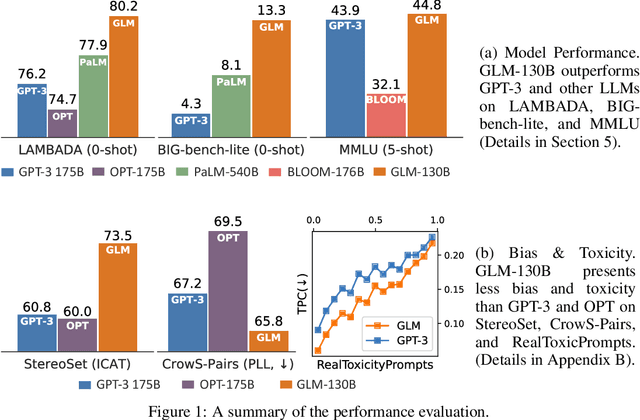
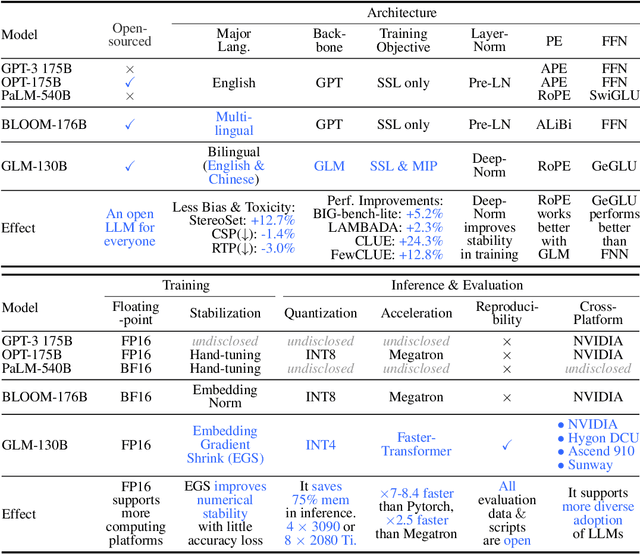

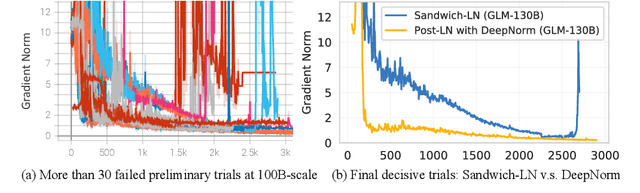
We introduce GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It is an attempt to open-source a 100B-scale model at least as good as GPT-3 and unveil how models of such a scale can be successfully pre-trained. Over the course of this effort, we face numerous unexpected technical and engineering challenges, particularly on loss spikes and disconvergence. In this paper, we introduce the training process of GLM-130B including its design choices, training strategies for both efficiency and stability, and engineering efforts. The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4$\times$RTX 3090 (24G) or 8$\times$RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models. The GLM-130B model weights are publicly accessible and its code, training logs, related toolkit, and lessons learned are open-sourced at https://github.com/THUDM/GLM-130B .