 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAdversarial Client Detection via Non-parametric Subspace Monitoring in the Internet of Federated Things
Oct 02, 2023
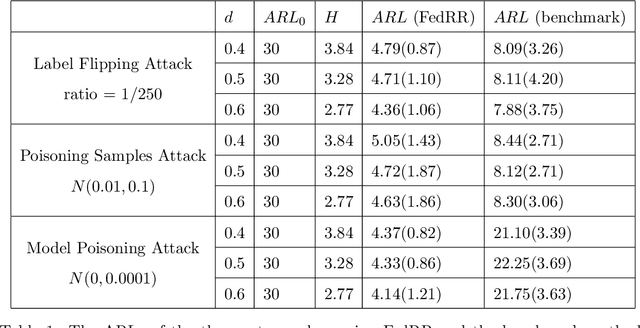


The Internet of Federated Things (IoFT) represents a network of interconnected systems with federated learning as the backbone, facilitating collaborative knowledge acquisition while ensuring data privacy for individual systems. The wide adoption of IoFT, however, is hindered by security concerns, particularly the susceptibility of federated learning networks to adversarial attacks. In this paper, we propose an effective non-parametric approach FedRR, which leverages the low-rank features of the transmitted parameter updates generated by federated learning to address the adversarial attack problem. Besides, our proposed method is capable of accurately detecting adversarial clients and controlling the false alarm rate under the scenario with no attack occurring. Experiments based on digit recognition using the MNIST datasets validated the advantages of our approach.
Ano-SuPs: Multi-size anomaly detection for manufactured products by identifying suspected patches
Sep 20, 2023Image-based systems have gained popularity owing to their capacity to provide rich manufacturing status information, low implementation costs and high acquisition rates. However, the complexity of the image background and various anomaly patterns pose new challenges to existing matrix decomposition methods, which are inadequate for modeling requirements. Moreover, the uncertainty of the anomaly can cause anomaly contamination problems, making the designed model and method highly susceptible to external disturbances. To address these challenges, we propose a two-stage strategy anomaly detection method that detects anomalies by identifying suspected patches (Ano-SuPs). Specifically, we propose to detect the patches with anomalies by reconstructing the input image twice: the first step is to obtain a set of normal patches by removing those suspected patches, and the second step is to use those normal patches to refine the identification of the patches with anomalies. To demonstrate its effectiveness, we evaluate the proposed method systematically through simulation experiments and case studies. We further identified the key parameters and designed steps that impact the model's performance and efficiency.
Tensor Dirichlet Process Multinomial Mixture Model for Passenger Trajectory Clustering
Jun 23, 2023Passenger clustering based on travel records is essential for transportation operators. However, existing methods cannot easily cluster the passengers due to the hierarchical structure of the passenger trip information, namely: each passenger has multiple trips, and each trip contains multi-dimensional multi-mode information. Furthermore, existing approaches rely on an accurate specification of the clustering number to start, which is difficult when millions of commuters are using the transport systems on a daily basis. In this paper, we propose a novel Tensor Dirichlet Process Multinomial Mixture model (Tensor-DPMM), which is designed to preserve the multi-mode and hierarchical structure of the multi-dimensional trip information via tensor, and cluster them in a unified one-step manner. The model also has the ability to determine the number of clusters automatically by using the Dirichlet Process to decide the probabilities for a passenger to be either assigned in an existing cluster or to create a new cluster: This allows our model to grow the clusters as needed in a dynamic manner. Finally, existing methods do not consider spatial semantic graphs such as geographical proximity and functional similarity between the locations, which may cause inaccurate clustering. To this end, we further propose a variant of our model, namely the Tensor-DPMM with Graph. For the algorithm, we propose a tensor Collapsed Gibbs Sampling method, with an innovative step of "disband and relocating", which disbands clusters with too small amount of members and relocates them to the remaining clustering. This avoids uncontrollable growing amounts of clusters. A case study based on Hong Kong metro passenger data is conducted to demonstrate the automatic process of learning the number of clusters, and the learned clusters are better in within-cluster compactness and cross-cluster separateness.
CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X
Mar 30, 2023



Large pre-trained code generation models, such as OpenAI Codex, can generate syntax- and function-correct code, making the coding of programmers more productive and our pursuit of artificial general intelligence closer. In this paper, we introduce CodeGeeX, a multilingual model with 13 billion parameters for code generation. CodeGeeX is pre-trained on 850 billion tokens of 23 programming languages as of June 2022. Our extensive experiments suggest that CodeGeeX outperforms multilingual code models of similar scale for both the tasks of code generation and translation on HumanEval-X. Building upon HumanEval (Python only), we develop the HumanEval-X benchmark for evaluating multilingual models by hand-writing the solutions in C++, Java, JavaScript, and Go. In addition, we build CodeGeeX-based extensions on Visual Studio Code, JetBrains, and Cloud Studio, generating 4.7 billion tokens for tens of thousands of active users per week. Our user study demonstrates that CodeGeeX can help to increase coding efficiency for 83.4% of its users. Finally, CodeGeeX is publicly accessible and in Sep. 2022, we open-sourced its code, model weights (the version of 850B tokens), API, extensions, and HumanEval-X at https://github.com/THUDM/CodeGeeX.
Additive Tensor Decomposition Considering Structural Data Information
Jul 27, 2020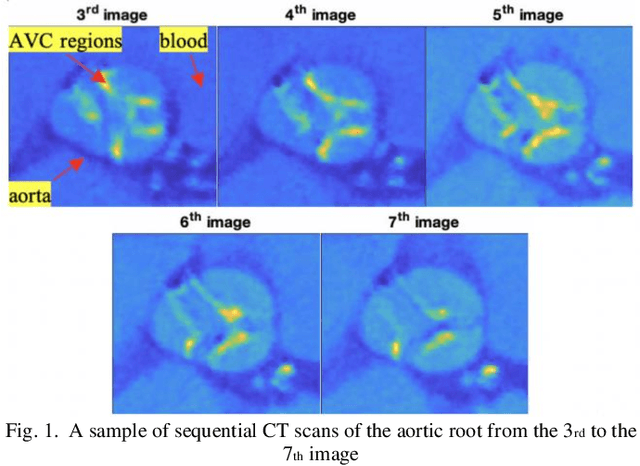
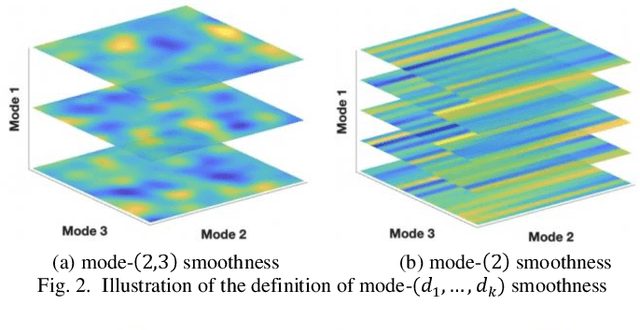

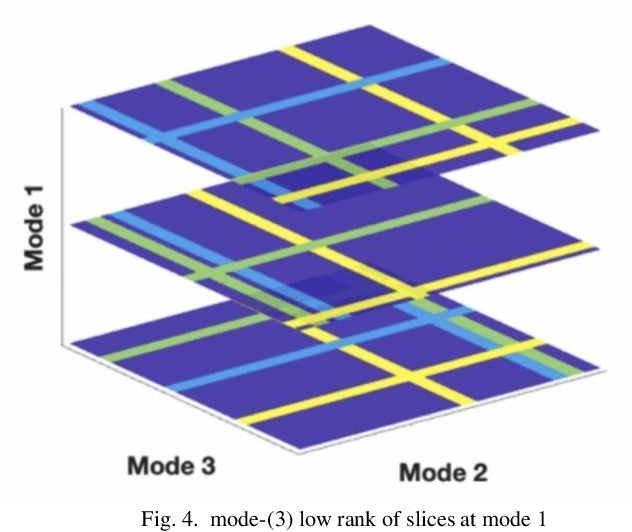
Tensor data with rich structural information becomes increasingly important in process modeling, monitoring, and diagnosis. Here structural information is referred to structural properties such as sparsity, smoothness, low-rank, and piecewise constancy. To reveal useful information from tensor data, we propose to decompose the tensor into the summation of multiple components based on different structural information of them. In this paper, we provide a new definition of structural information in tensor data. Based on it, we propose an additive tensor decomposition (ATD) framework to extract useful information from tensor data. This framework specifies a high dimensional optimization problem to obtain the components with distinct structural information. An alternating direction method of multipliers (ADMM) algorithm is proposed to solve it, which is highly parallelable and thus suitable for the proposed optimization problem. Two simulation examples and a real case study in medical image analysis illustrate the versatility and effectiveness of the ATD framework.