 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTwo stage GNSS outlier detection for factor graph optimization based GNSS-RTK/INS/odometer fusion
Oct 01, 2025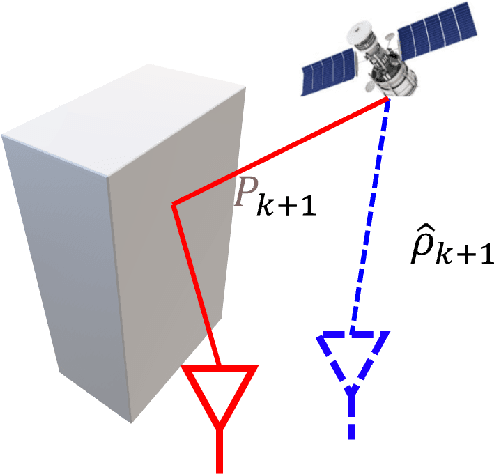
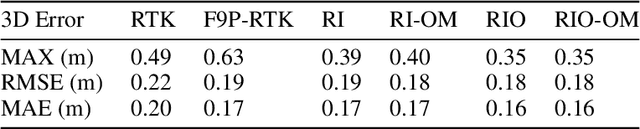
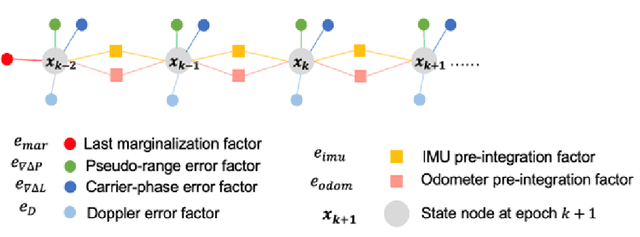
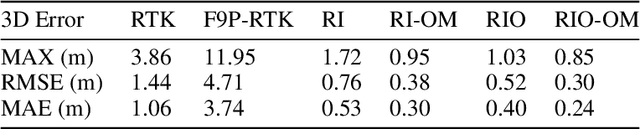
Reliable GNSS positioning in complex environments remains a critical challenge due to non-line-of-sight (NLOS) propagation, multipath effects, and frequent signal blockages. These effects can easily introduce large outliers into the raw pseudo-range measurements, which significantly degrade the performance of global navigation satellite system (GNSS) real-time kinematic (RTK) positioning and limit the effectiveness of tightly coupled GNSS-based integrated navigation system. To address this issue, we propose a two-stage outlier detection method and apply the method in a tightly coupled GNSS-RTK, inertial navigation system (INS), and odometer integration based on factor graph optimization (FGO). In the first stage, Doppler measurements are employed to detect pseudo-range outliers in a GNSS-only manner, since Doppler is less sensitive to multipath and NLOS effects compared with pseudo-range, making it a more stable reference for detecting sudden inconsistencies. In the second stage, pre-integrated inertial measurement units (IMU) and odometer constraints are used to generate predicted double-difference pseudo-range measurements, which enable a more refined identification and rejection of remaining outliers. By combining these two complementary stages, the system achieves improved robustness against both gross pseudo-range errors and degraded satellite measuring quality. The experimental results demonstrate that the two-stage detection framework significantly reduces the impact of pseudo-range outliers, and leads to improved positioning accuracy and consistency compared with representative baseline approaches. In the deep urban canyon test, the outlier mitigation method has limits the RMSE of GNSS-RTK/INS/odometer fusion from 0.52 m to 0.30 m, with 42.3% improvement.
SceneGenAgent: Precise Industrial Scene Generation with Coding Agent
Oct 29, 2024The modeling of industrial scenes is essential for simulations in industrial manufacturing. While large language models (LLMs) have shown significant progress in generating general 3D scenes from textual descriptions, generating industrial scenes with LLMs poses a unique challenge due to their demand for precise measurements and positioning, requiring complex planning over spatial arrangement. To address this challenge, we introduce SceneGenAgent, an LLM-based agent for generating industrial scenes through C# code. SceneGenAgent ensures precise layout planning through a structured and calculable format, layout verification, and iterative refinement to meet the quantitative requirements of industrial scenarios. Experiment results demonstrate that LLMs powered by SceneGenAgent exceed their original performance, reaching up to 81.0% success rate in real-world industrial scene generation tasks and effectively meeting most scene generation requirements. To further enhance accessibility, we construct SceneInstruct, a dataset designed for fine-tuning open-source LLMs to integrate into SceneGenAgent. Experiments show that fine-tuning open-source LLMs on SceneInstruct yields significant performance improvements, with Llama3.1-70B approaching the capabilities of GPT-4o. Our code and data are available at https://github.com/THUDM/SceneGenAgent .
ChatGLM: A Family of Large Language Models from GLM-130B to GLM-4 All Tools
Jun 18, 2024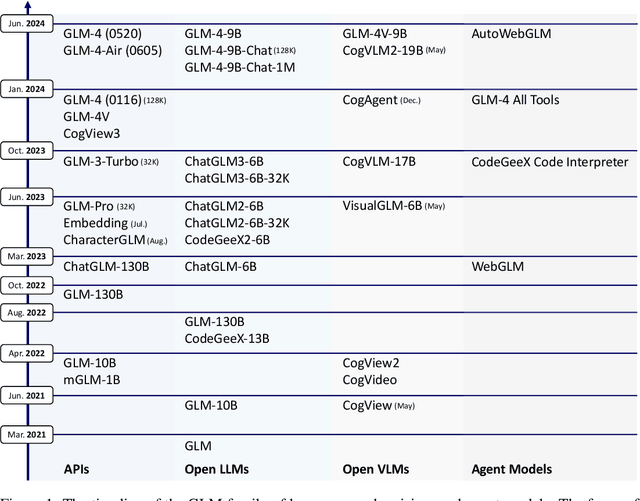
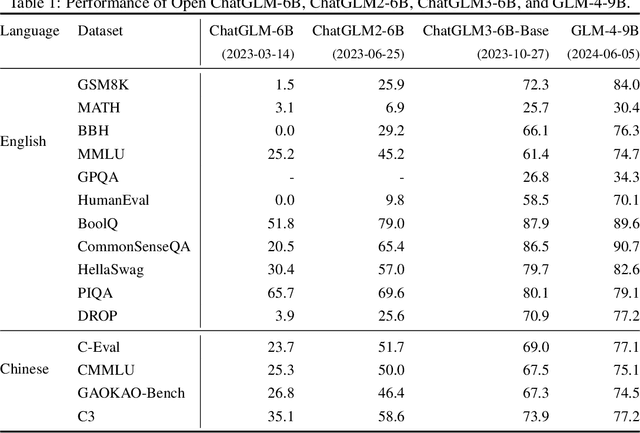
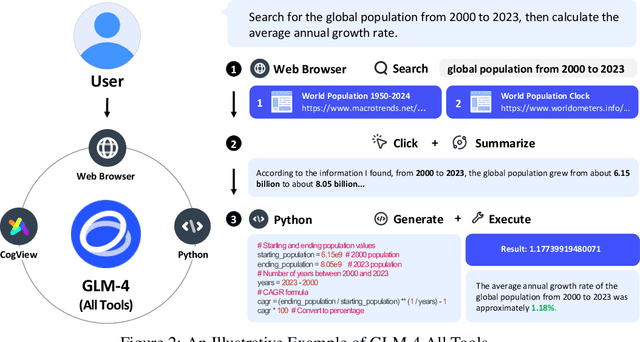
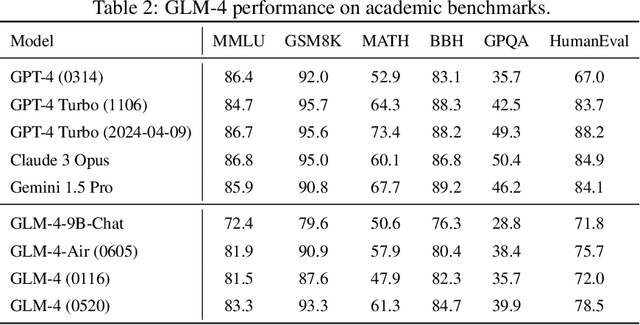
We introduce ChatGLM, an evolving family of large language models that we have been developing over time. This report primarily focuses on the GLM-4 language series, which includes GLM-4, GLM-4-Air, and GLM-4-9B. They represent our most capable models that are trained with all the insights and lessons gained from the preceding three generations of ChatGLM. To date, the GLM-4 models are pre-trained on ten trillions of tokens mostly in Chinese and English, along with a small set of corpus from 24 languages, and aligned primarily for Chinese and English usage. The high-quality alignment is achieved via a multi-stage post-training process, which involves supervised fine-tuning and learning from human feedback. Evaluations show that GLM-4 1) closely rivals or outperforms GPT-4 in terms of general metrics such as MMLU, GSM8K, MATH, BBH, GPQA, and HumanEval, 2) gets close to GPT-4-Turbo in instruction following as measured by IFEval, 3) matches GPT-4 Turbo (128K) and Claude 3 for long context tasks, and 4) outperforms GPT-4 in Chinese alignments as measured by AlignBench. The GLM-4 All Tools model is further aligned to understand user intent and autonomously decide when and which tool(s) touse -- including web browser, Python interpreter, text-to-image model, and user-defined functions -- to effectively complete complex tasks. In practical applications, it matches and even surpasses GPT-4 All Tools in tasks like accessing online information via web browsing and solving math problems using Python interpreter. Over the course, we have open-sourced a series of models, including ChatGLM-6B (three generations), GLM-4-9B (128K, 1M), GLM-4V-9B, WebGLM, and CodeGeeX, attracting over 10 million downloads on Hugging face in the year 2023 alone. The open models can be accessed through https://github.com/THUDM and https://huggingface.co/THUDM.
CodeGeeX: A Pre-Trained Model for Code Generation with Multilingual Evaluations on HumanEval-X
Mar 30, 2023



Large pre-trained code generation models, such as OpenAI Codex, can generate syntax- and function-correct code, making the coding of programmers more productive and our pursuit of artificial general intelligence closer. In this paper, we introduce CodeGeeX, a multilingual model with 13 billion parameters for code generation. CodeGeeX is pre-trained on 850 billion tokens of 23 programming languages as of June 2022. Our extensive experiments suggest that CodeGeeX outperforms multilingual code models of similar scale for both the tasks of code generation and translation on HumanEval-X. Building upon HumanEval (Python only), we develop the HumanEval-X benchmark for evaluating multilingual models by hand-writing the solutions in C++, Java, JavaScript, and Go. In addition, we build CodeGeeX-based extensions on Visual Studio Code, JetBrains, and Cloud Studio, generating 4.7 billion tokens for tens of thousands of active users per week. Our user study demonstrates that CodeGeeX can help to increase coding efficiency for 83.4% of its users. Finally, CodeGeeX is publicly accessible and in Sep. 2022, we open-sourced its code, model weights (the version of 850B tokens), API, extensions, and HumanEval-X at https://github.com/THUDM/CodeGeeX.
GLM-130B: An Open Bilingual Pre-trained Model
Oct 05, 2022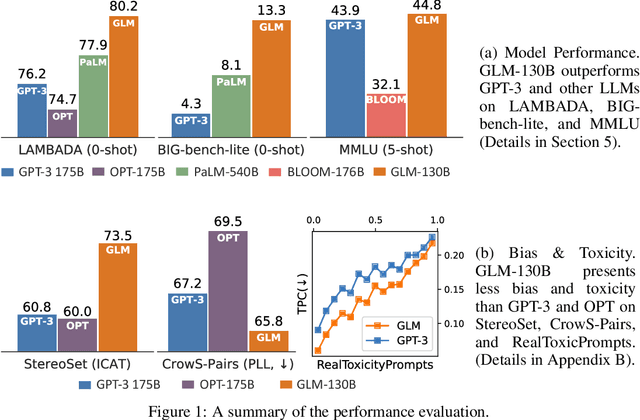
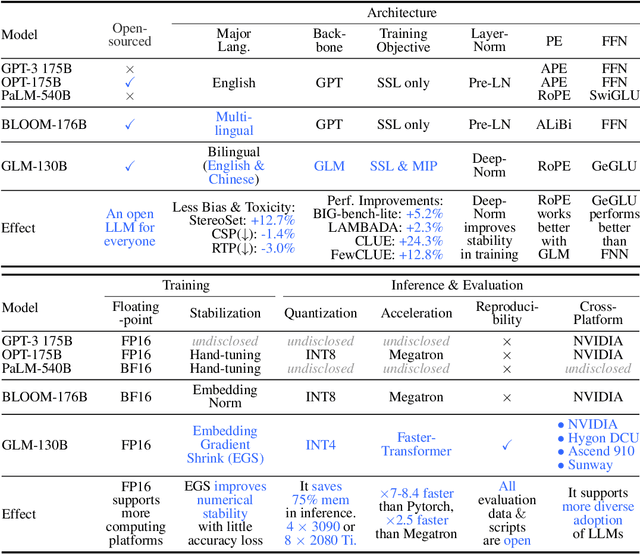

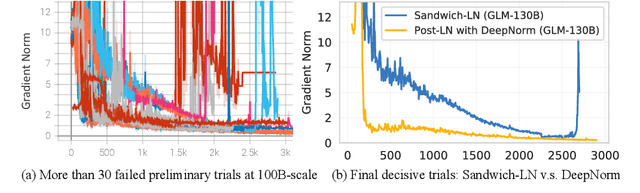
We introduce GLM-130B, a bilingual (English and Chinese) pre-trained language model with 130 billion parameters. It is an attempt to open-source a 100B-scale model at least as good as GPT-3 and unveil how models of such a scale can be successfully pre-trained. Over the course of this effort, we face numerous unexpected technical and engineering challenges, particularly on loss spikes and disconvergence. In this paper, we introduce the training process of GLM-130B including its design choices, training strategies for both efficiency and stability, and engineering efforts. The resultant GLM-130B model offers significant outperformance over GPT-3 175B on a wide range of popular English benchmarks while the performance advantage is not observed in OPT-175B and BLOOM-176B. It also consistently and significantly outperforms ERNIE TITAN 3.0 260B -- the largest Chinese language model -- across related benchmarks. Finally, we leverage a unique scaling property of GLM-130B to reach INT4 quantization, without quantization aware training and with almost no performance loss, making it the first among 100B-scale models. More importantly, the property allows its effective inference on 4$\times$RTX 3090 (24G) or 8$\times$RTX 2080 Ti (11G) GPUs, the most ever affordable GPUs required for using 100B-scale models. The GLM-130B model weights are publicly accessible and its code, training logs, related toolkit, and lessons learned are open-sourced at https://github.com/THUDM/GLM-130B .