 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-Tuning vs. RAG for Multi-Hop Question Answering with Novel Knowledge
Jan 11, 2026Multi-hop question answering is widely used to evaluate the reasoning capabilities of large language models (LLMs), as it requires integrating multiple pieces of supporting knowledge to arrive at a correct answer. While prior work has explored different mechanisms for providing knowledge to LLMs, such as finetuning and retrieval-augmented generation (RAG), their relative effectiveness for multi-hop question answering remains insufficiently understood, particularly when the required knowledge is temporally novel. In this paper, we systematically compare parametric and non-parametric knowledge injection methods for open-domain multi-hop question answering. We evaluate unsupervised fine-tuning (continual pretraining), supervised fine-tuning, and retrieval-augmented generation across three 7B-parameter open-source LLMs. Experiments are conducted on two benchmarks: QASC, a standard multi-hop science question answering dataset, and a newly constructed dataset of over 10,000 multi-hop questions derived from Wikipedia events in 2024, designed to test knowledge beyond the models' pretraining cutoff. Our results show that unsupervised fine-tuning provides only limited gains over base models, suggesting that continual pretraining alone is insufficient for improving multi-hop reasoning accuracy. In contrast, retrieval-augmented generation yields substantial and consistent improvements, particularly when answering questions that rely on temporally novel information. Supervised fine-tuning achieves the highest overall accuracy across models and datasets. These findings highlight fundamental differences in how knowledge injection mechanisms support multi-hop question answering and underscore the importance of retrieval-based methods when external or compositional knowledge is required.
VPO: Aligning Text-to-Video Generation Models with Prompt Optimization
Mar 26, 2025

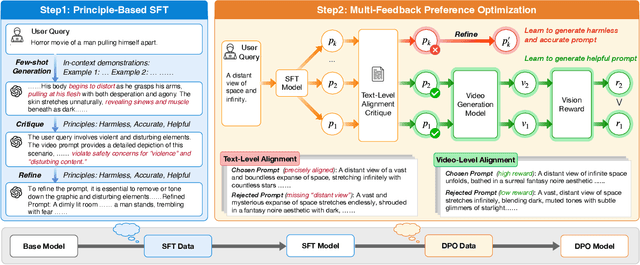
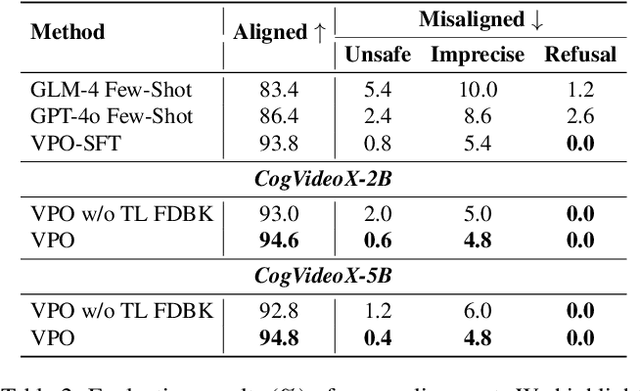
Video generation models have achieved remarkable progress in text-to-video tasks. These models are typically trained on text-video pairs with highly detailed and carefully crafted descriptions, while real-world user inputs during inference are often concise, vague, or poorly structured. This gap makes prompt optimization crucial for generating high-quality videos. Current methods often rely on large language models (LLMs) to refine prompts through in-context learning, but suffer from several limitations: they may distort user intent, omit critical details, or introduce safety risks. Moreover, they optimize prompts without considering the impact on the final video quality, which can lead to suboptimal results. To address these issues, we introduce VPO, a principled framework that optimizes prompts based on three core principles: harmlessness, accuracy, and helpfulness. The generated prompts faithfully preserve user intents and, more importantly, enhance the safety and quality of generated videos. To achieve this, VPO employs a two-stage optimization approach. First, we construct and refine a supervised fine-tuning (SFT) dataset based on principles of safety and alignment. Second, we introduce both text-level and video-level feedback to further optimize the SFT model with preference learning. Our extensive experiments demonstrate that VPO significantly improves safety, alignment, and video quality compared to baseline methods. Moreover, VPO shows strong generalization across video generation models. Furthermore, we demonstrate that VPO could outperform and be combined with RLHF methods on video generation models, underscoring the effectiveness of VPO in aligning video generation models. Our code and data are publicly available at https://github.com/thu-coai/VPO.
LogLLaMA: Transformer-based log anomaly detection with LLaMA
Mar 19, 2025



Log anomaly detection refers to the task that distinguishes the anomalous log messages from normal log messages. Transformer-based large language models (LLMs) are becoming popular for log anomaly detection because of their superb ability to understand complex and long language patterns. In this paper, we propose LogLLaMA, a novel framework that leverages LLaMA2. LogLLaMA is first finetuned on normal log messages from three large-scale datasets to learn their patterns. After finetuning, the model is capable of generating successive log messages given previous log messages. Our generative model is further trained to identify anomalous log messages using reinforcement learning (RL). The experimental results show that LogLLaMA outperforms the state-of-the-art approaches for anomaly detection on BGL, Thunderbird, and HDFS datasets.
Concat-ID: Towards Universal Identity-Preserving Video Synthesis
Mar 18, 2025We present Concat-ID, a unified framework for identity-preserving video generation. Concat-ID employs Variational Autoencoders to extract image features, which are concatenated with video latents along the sequence dimension, leveraging solely 3D self-attention mechanisms without the need for additional modules. A novel cross-video pairing strategy and a multi-stage training regimen are introduced to balance identity consistency and facial editability while enhancing video naturalness. Extensive experiments demonstrate Concat-ID's superiority over existing methods in both single and multi-identity generation, as well as its seamless scalability to multi-subject scenarios, including virtual try-on and background-controllable generation. Concat-ID establishes a new benchmark for identity-preserving video synthesis, providing a versatile and scalable solution for a wide range of applications.
MotionBench: Benchmarking and Improving Fine-grained Video Motion Understanding for Vision Language Models
Jan 06, 2025
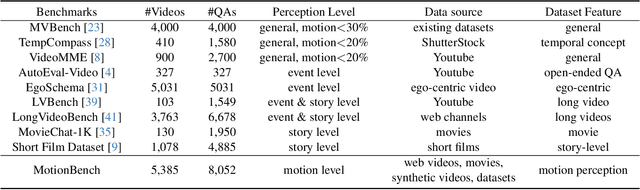


In recent years, vision language models (VLMs) have made significant advancements in video understanding. However, a crucial capability - fine-grained motion comprehension - remains under-explored in current benchmarks. To address this gap, we propose MotionBench, a comprehensive evaluation benchmark designed to assess the fine-grained motion comprehension of video understanding models. MotionBench evaluates models' motion-level perception through six primary categories of motion-oriented question types and includes data collected from diverse sources, ensuring a broad representation of real-world video content. Experimental results reveal that existing VLMs perform poorly in understanding fine-grained motions. To enhance VLM's ability to perceive fine-grained motion within a limited sequence length of LLM, we conduct extensive experiments reviewing VLM architectures optimized for video feature compression and propose a novel and efficient Through-Encoder (TE) Fusion method. Experiments show that higher frame rate inputs and TE Fusion yield improvements in motion understanding, yet there is still substantial room for enhancement. Our benchmark aims to guide and motivate the development of more capable video understanding models, emphasizing the importance of fine-grained motion comprehension. Project page: https://motion-bench.github.io .
VisionReward: Fine-Grained Multi-Dimensional Human Preference Learning for Image and Video Generation
Dec 30, 2024We present a general strategy to aligning visual generation models -- both image and video generation -- with human preference. To start with, we build VisionReward -- a fine-grained and multi-dimensional reward model. We decompose human preferences in images and videos into multiple dimensions, each represented by a series of judgment questions, linearly weighted and summed to an interpretable and accurate score. To address the challenges of video quality assessment, we systematically analyze various dynamic features of videos, which helps VisionReward surpass VideoScore by 17.2% and achieve top performance for video preference prediction. Based on VisionReward, we develop a multi-objective preference learning algorithm that effectively addresses the issue of confounding factors within preference data. Our approach significantly outperforms existing image and video scoring methods on both machine metrics and human evaluation. All code and datasets are provided at https://github.com/THUDM/VisionReward.
Entropy Loss: An Interpretability Amplifier of 3D Object Detection Network for Intelligent Driving
Sep 01, 2024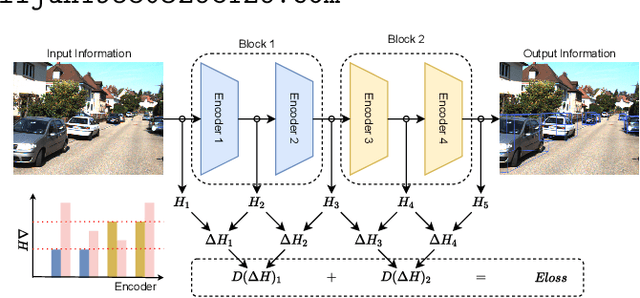
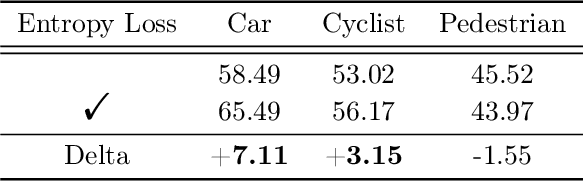
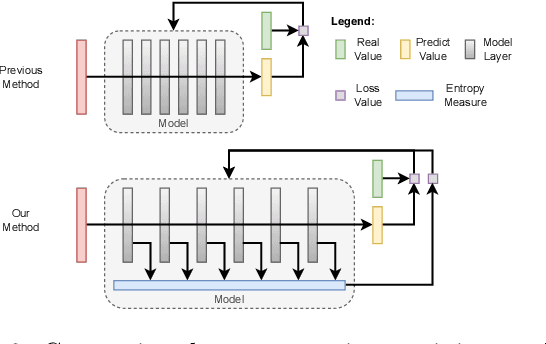
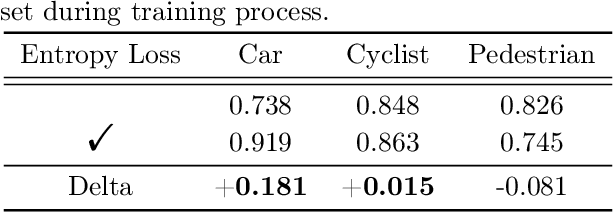
With the increasing complexity of the traffic environment, the significance of safety perception in intelligent driving is intensifying. Traditional methods in the field of intelligent driving perception rely on deep learning, which suffers from limited interpretability, often described as a "black box." This paper introduces a novel type of loss function, termed "Entropy Loss," along with an innovative training strategy. Entropy Loss is formulated based on the functionality of feature compression networks within the perception model. Drawing inspiration from communication systems, the information transmission process in a feature compression network is expected to demonstrate steady changes in information volume and a continuous decrease in information entropy. By modeling network layer outputs as continuous random variables, we construct a probabilistic model that quantifies changes in information volume. Entropy Loss is then derived based on these expectations, guiding the update of network parameters to enhance network interpretability. Our experiments indicate that the Entropy Loss training strategy accelerates the training process. Utilizing the same 60 training epochs, the accuracy of 3D object detection models using Entropy Loss on the KITTI test set improved by up to 4.47\% compared to models without Entropy Loss, underscoring the method's efficacy. The implementation code is available at \url{https://github.com/yhbcode000/Eloss-Interpretability}.
CogVLM2: Visual Language Models for Image and Video Understanding
Aug 29, 2024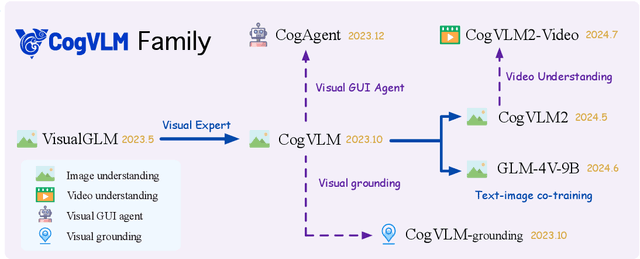

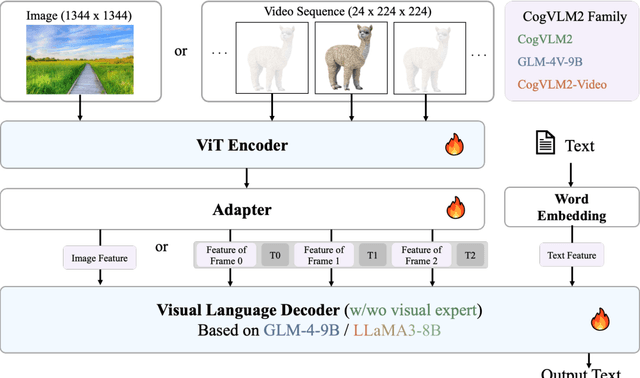
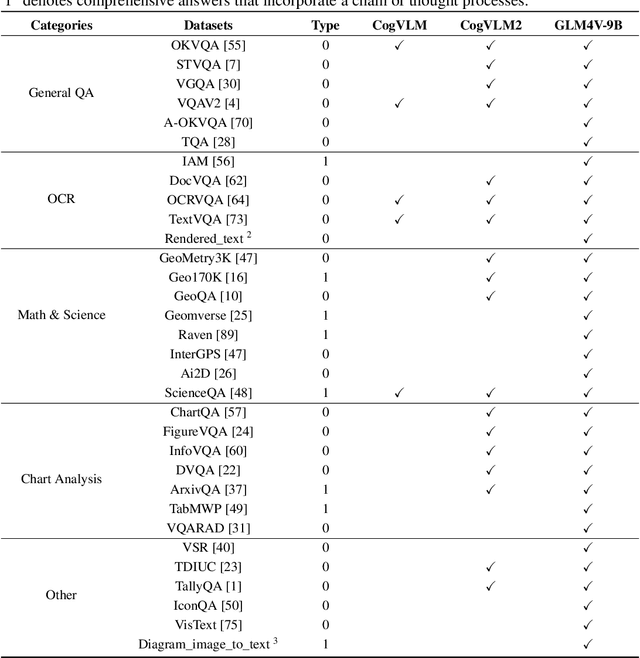
Beginning with VisualGLM and CogVLM, we are continuously exploring VLMs in pursuit of enhanced vision-language fusion, efficient higher-resolution architecture, and broader modalities and applications. Here we propose the CogVLM2 family, a new generation of visual language models for image and video understanding including CogVLM2, CogVLM2-Video and GLM-4V. As an image understanding model, CogVLM2 inherits the visual expert architecture with improved training recipes in both pre-training and post-training stages, supporting input resolution up to $1344 \times 1344$ pixels. As a video understanding model, CogVLM2-Video integrates multi-frame input with timestamps and proposes automated temporal grounding data construction. Notably, CogVLM2 family has achieved state-of-the-art results on benchmarks like MMBench, MM-Vet, TextVQA, MVBench and VCGBench. All models are open-sourced in https://github.com/THUDM/CogVLM2 and https://github.com/THUDM/GLM-4, contributing to the advancement of the field.
CogVideoX: Text-to-Video Diffusion Models with An Expert Transformer
Aug 12, 2024We introduce CogVideoX, a large-scale diffusion transformer model designed for generating videos based on text prompts. To efficently model video data, we propose to levearge a 3D Variational Autoencoder (VAE) to compress videos along both spatial and temporal dimensions. To improve the text-video alignment, we propose an expert transformer with the expert adaptive LayerNorm to facilitate the deep fusion between the two modalities. By employing a progressive training technique, CogVideoX is adept at producing coherent, long-duration videos characterized by significant motions. In addition, we develop an effective text-video data processing pipeline that includes various data preprocessing strategies and a video captioning method. It significantly helps enhance the performance of CogVideoX, improving both generation quality and semantic alignment. Results show that CogVideoX demonstrates state-of-the-art performance across both multiple machine metrics and human evaluations. The model weights of both the 3D Causal VAE and CogVideoX are publicly available at https://github.com/THUDM/CogVideo.
Inf-DiT: Upsampling Any-Resolution Image with Memory-Efficient Diffusion Transformer
May 08, 2024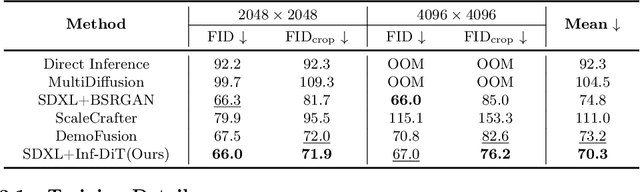
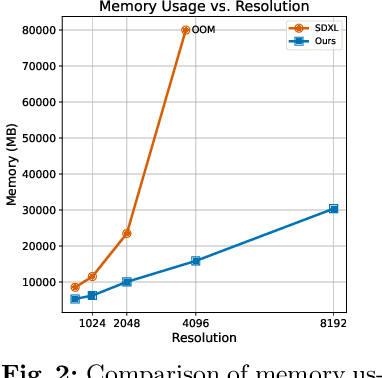

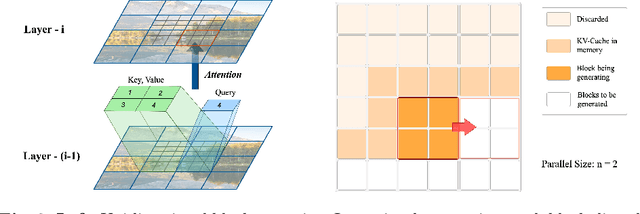
Diffusion models have shown remarkable performance in image generation in recent years. However, due to a quadratic increase in memory during generating ultra-high-resolution images (e.g. 4096*4096), the resolution of generated images is often limited to 1024*1024. In this work. we propose a unidirectional block attention mechanism that can adaptively adjust the memory overhead during the inference process and handle global dependencies. Building on this module, we adopt the DiT structure for upsampling and develop an infinite super-resolution model capable of upsampling images of various shapes and resolutions. Comprehensive experiments show that our model achieves SOTA performance in generating ultra-high-resolution images in both machine and human evaluation. Compared to commonly used UNet structures, our model can save more than 5x memory when generating 4096*4096 images. The project URL is https://github.com/THUDM/Inf-DiT.