 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGradient-Guided Parameter Mask for Multi-Scenario Image Restoration Under Adverse Weather
Nov 23, 2024Removing adverse weather conditions such as rain, raindrop, and snow from images is critical for various real-world applications, including autonomous driving, surveillance, and remote sensing. However, existing multi-task approaches typically rely on augmenting the model with additional parameters to handle multiple scenarios. While this enables the model to address diverse tasks, the introduction of extra parameters significantly complicates its practical deployment. In this paper, we propose a novel Gradient-Guided Parameter Mask for Multi-Scenario Image Restoration under adverse weather, designed to effectively handle image degradation under diverse weather conditions without additional parameters. Our method segments model parameters into common and specific components by evaluating the gradient variation intensity during training for each specific weather condition. This enables the model to precisely and adaptively learn relevant features for each weather scenario, improving both efficiency and effectiveness without compromising on performance. This method constructs specific masks based on gradient fluctuations to isolate parameters influenced by other tasks, ensuring that the model achieves strong performance across all scenarios without adding extra parameters. We demonstrate the state-of-the-art performance of our framework through extensive experiments on multiple benchmark datasets. Specifically, our method achieves PSNR scores of 29.22 on the Raindrop dataset, 30.76 on the Rain dataset, and 29.56 on the Snow100K dataset. Code is available at: \href{https://github.com/AierLab/MultiTask}{https://github.com/AierLab/MultiTask}.
Entropy Loss: An Interpretability Amplifier of 3D Object Detection Network for Intelligent Driving
Sep 01, 2024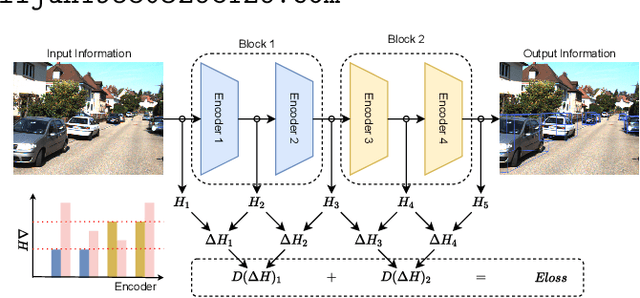
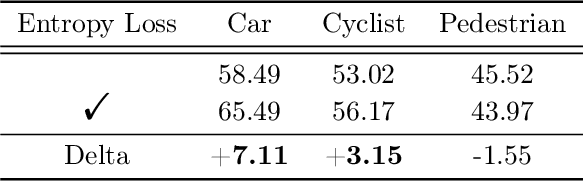
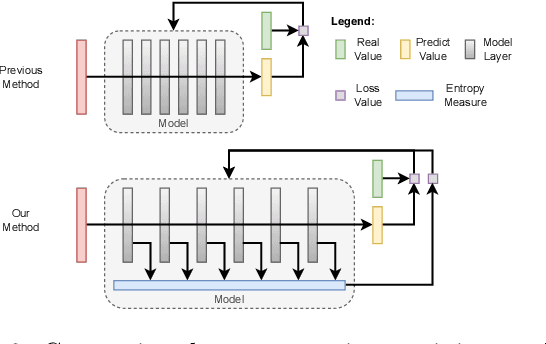
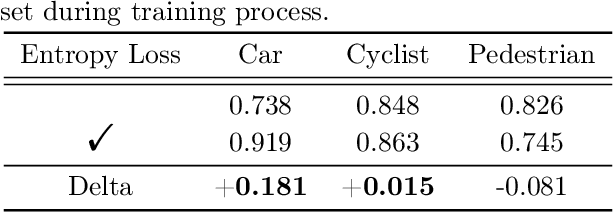
With the increasing complexity of the traffic environment, the significance of safety perception in intelligent driving is intensifying. Traditional methods in the field of intelligent driving perception rely on deep learning, which suffers from limited interpretability, often described as a "black box." This paper introduces a novel type of loss function, termed "Entropy Loss," along with an innovative training strategy. Entropy Loss is formulated based on the functionality of feature compression networks within the perception model. Drawing inspiration from communication systems, the information transmission process in a feature compression network is expected to demonstrate steady changes in information volume and a continuous decrease in information entropy. By modeling network layer outputs as continuous random variables, we construct a probabilistic model that quantifies changes in information volume. Entropy Loss is then derived based on these expectations, guiding the update of network parameters to enhance network interpretability. Our experiments indicate that the Entropy Loss training strategy accelerates the training process. Utilizing the same 60 training epochs, the accuracy of 3D object detection models using Entropy Loss on the KITTI test set improved by up to 4.47\% compared to models without Entropy Loss, underscoring the method's efficacy. The implementation code is available at \url{https://github.com/yhbcode000/Eloss-Interpretability}.