 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTabPFN for Zero-shot Parametric Engineering Design Generation
Feb 02, 2026Deep generative models for engineering design often require substantial computational cost, large training datasets, and extensive retraining when design requirements or datasets change, limiting their applicability in real-world engineering design workflow. In this work, we propose a zero-shot generation framework for parametric engineering design based on TabPFN, enabling conditional design generation using only a limited number of reference samples and without any task-specific model training or fine-tuning. The proposed method generates design parameters sequentially conditioned on target performance indicators, providing a flexible alternative to conventional generative models. The effectiveness of the proposed approach is evaluated on three engineering design datasets, i.e., ship hull design, BlendedNet aircraft, and UIUC airfoil. Experimental results demonstrate that the proposed method achieves competitive diversity across highly structured parametric design spaces, remains robust to variations in sampling, resolution and parameter dimensionality of geometry generation, and achieves a low performance error (e.g., less than 2% in generated ship hull designs' performance). Compared with diffusion-based generative models, the proposed framework significantly reduces computational overhead and data requirements while preserving reliable generation performance. These results highlight the potential of zero-shot, data-efficient generation as a practical and efficient tool for engineering design, enabling rapid deployment, flexible adaptation to new design settings, and ease of integration into real-world engineering workflows.
RePaint-Enhanced Conditional Diffusion Model for Parametric Engineering Designs under Performance and Parameter Constraints
Jan 30, 2026This paper presents a RePaint-enhanced framework that integrates a pre-trained performance-guided denoising diffusion probabilistic model (DDPM) for performance- and parameter-constraint engineering design generation. The proposed method enables the generation of missing design components based on a partial reference design while satisfying performance constraints, without retraining the underlying model. By applying mask-based resampling during inference process, RePaint allows efficient and controllable repainting of partial designs under both performance and parameter constraints, which is not supported by conventional DDPM-base methods. The framework is evaluated on two representative design problems, parametric ship hull design and airfoil design, demonstrating its ability to generate novel designs with expected performance based on a partial reference design. Results show that the method achieves accuracy comparable to or better than pre-trained models while enabling controlled novelty through fixing partial designs. Overall, the proposed approach provides an efficient, training-free solution for parameter-constraint-aware generative design in engineering applications.
Adaptation and Fine-tuning with TabPFN for Travelling Salesman Problem
Nov 08, 2025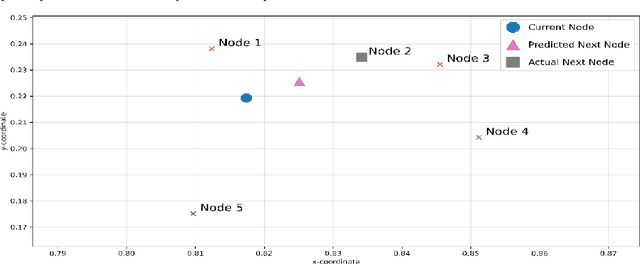
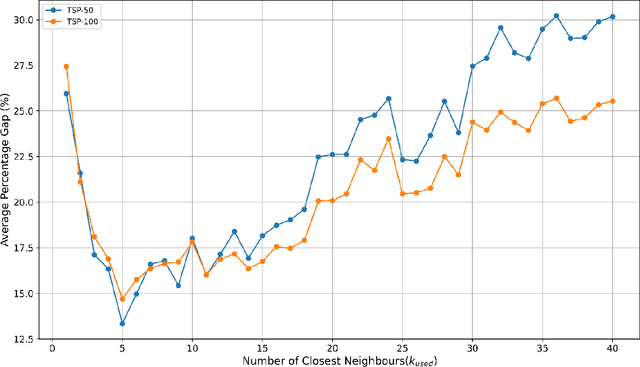
Tabular Prior-Data Fitted Network (TabPFN) is a foundation model designed for small to medium-sized tabular data, which has attracted much attention recently. This paper investigates the application of TabPFN in Combinatorial Optimization (CO) problems. The aim is to lessen challenges in time and data-intensive training requirements often observed in using traditional methods including exact and heuristic algorithms, Machine Learning (ML)-based models, to solve CO problems. Proposing possibly the first ever application of TabPFN for such a purpose, we adapt and fine-tune the TabPFN model to solve the Travelling Salesman Problem (TSP), one of the most well-known CO problems. Specifically, we adopt the node-based approach and the node-predicting adaptation strategy to construct the entire TSP route. Our evaluation with varying instance sizes confirms that TabPFN requires minimal training, adapts to TSP using a single sample, performs better generalization across varying TSP instance sizes, and reduces performance degradation. Furthermore, the training process with adaptation and fine-tuning is completed within minutes. The methodology leads to strong solution quality even without post-processing and achieves performance comparable to other models with post-processing refinement. Our findings suggest that the TabPFN model is a promising approach to solve structured and CO problems efficiently under training resource constraints and rapid deployment requirements.
VLA-Adapter: An Effective Paradigm for Tiny-Scale Vision-Language-Action Model
Sep 11, 2025Vision-Language-Action (VLA) models typically bridge the gap between perceptual and action spaces by pre-training a large-scale Vision-Language Model (VLM) on robotic data. While this approach greatly enhances performance, it also incurs significant training costs. In this paper, we investigate how to effectively bridge vision-language (VL) representations to action (A). We introduce VLA-Adapter, a novel paradigm designed to reduce the reliance of VLA models on large-scale VLMs and extensive pre-training. To this end, we first systematically analyze the effectiveness of various VL conditions and present key findings on which conditions are essential for bridging perception and action spaces. Based on these insights, we propose a lightweight Policy module with Bridge Attention, which autonomously injects the optimal condition into the action space. In this way, our method achieves high performance using only a 0.5B-parameter backbone, without any robotic data pre-training. Extensive experiments on both simulated and real-world robotic benchmarks demonstrate that VLA-Adapter not only achieves state-of-the-art level performance, but also offers the fast inference speed reported to date. Furthermore, thanks to the proposed advanced bridging paradigm, VLA-Adapter enables the training of a powerful VLA model in just 8 hours on a single consumer-grade GPU, greatly lowering the barrier to deploying the VLA model. Project page: https://vla-adapter.github.io/.
Hybrid Metaheuristic Vehicle Routing Problem for Security Dispatch Operations
Mar 03, 2025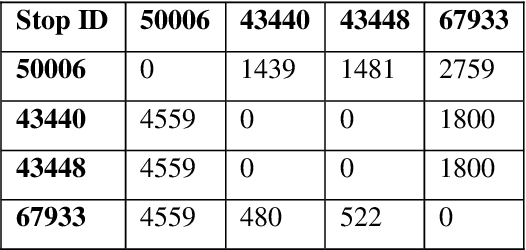
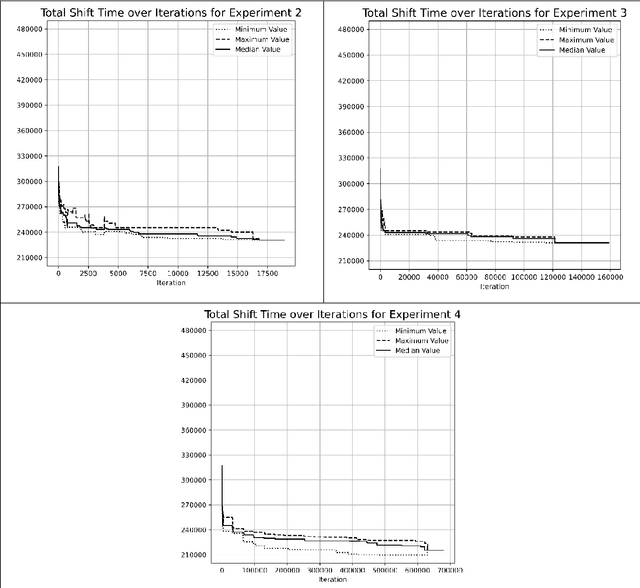
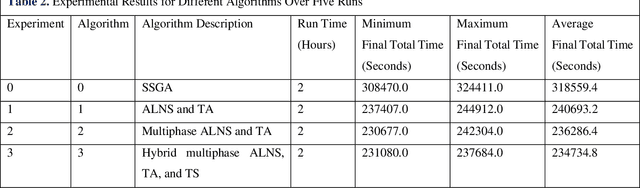

This paper investigates the optimization of the Vehicle Routing Problem for Security Dispatch (VRPSD). VRPSD focuses on security and patrolling applications which involve challenging constraints including precise timing and strict time windows. We propose three algorithms based on different metaheuristics, which are Adaptive Large Neighborhood Search (ALNS), Tabu Search (TS), and Threshold Accepting (TA). The first algorithm combines single-phase ALNS with TA, the second employs a multiphase ALNS with TA, and the third integrates multiphase ALNS, TS, and TA. Experiments are conducted on an instance comprising 251 customer requests. The results demonstrate that the third algorithm, the hybrid multiphase ALNS-TS-TA algorithm, delivers the best performance. This approach simultaneously leverages the large-area search capabilities of ALNS for exploration and effectively escapes local optima when the multiphase ALNS is coupled with TS and TA. Furthermore, in our experiments, the hybrid multiphase ALNS-TS-TA algorithm is the only one that shows potential for improving results with increased computation time across all attempts.
Toward Copyright Integrity and Verifiability via Multi-Bit Watermarking for Intelligent Transportation Systems
Feb 08, 2025Intelligent transportation systems (ITS) use advanced technologies such as artificial intelligence to significantly improve traffic flow management efficiency, and promote the intelligent development of the transportation industry. However, if the data in ITS is attacked, such as tampering or forgery, it will endanger public safety and cause social losses. Therefore, this paper proposes a watermarking that can verify the integrity of copyright in response to the needs of ITS, termed ITSmark. ITSmark focuses on functions such as extracting watermarks, verifying permission, and tracing tampered locations. The scheme uses the copyright information to build the multi-bit space and divides this space into multiple segments. These segments will be assigned to tokens. Thus, the next token is determined by its segment which contains the copyright. In this way, the obtained data contains the custom watermark. To ensure the authorization, key parameters are encrypted during copyright embedding to obtain cipher data. Only by possessing the correct cipher data and private key, can the user entirely extract the watermark. Experiments show that ITSmark surpasses baseline performances in data quality, extraction accuracy, and unforgeability. It also shows unique capabilities of permission verification and tampered location tracing, which ensures the security of extraction and the reliability of copyright verification. Furthermore, ITSmark can also customize the watermark embedding position and proportion according to user needs, making embedding more flexible.
* 11 figures, 10 tables. Accepted for publication in IEEE Transactions on Intelligent Transportation Systems (accepted versions, not the IEEE-published versions). \copyright 2025 IEEE. All rights reserved, including rights for text and data mining, and training of artificial intelligence and similar technologies. Personal use is permitted, but republication/redistribution requires IEEE permission
U-GIFT: Uncertainty-Guided Firewall for Toxic Speech in Few-Shot Scenario
Jan 01, 2025
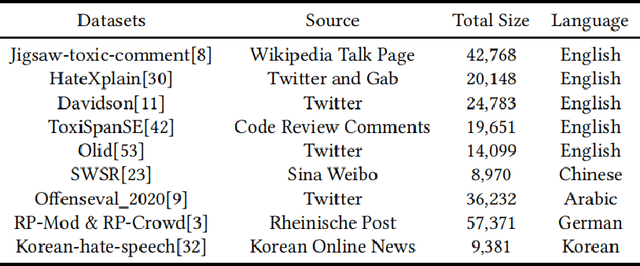
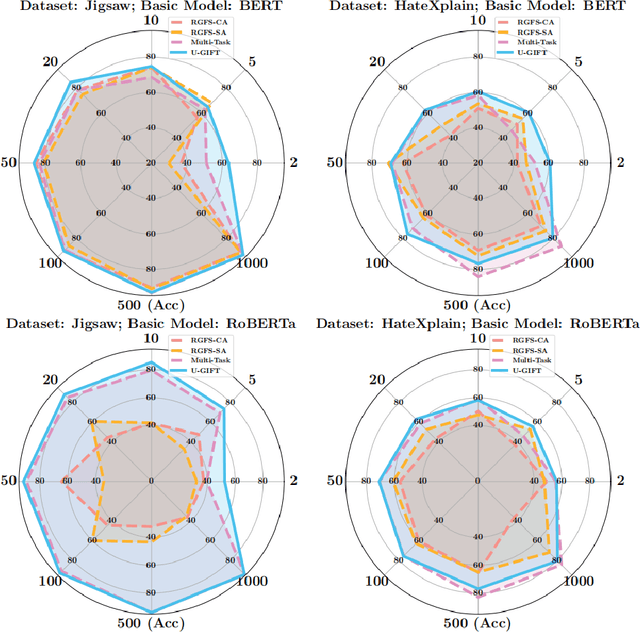
With the widespread use of social media, user-generated content has surged on online platforms. When such content includes hateful, abusive, offensive, or cyberbullying behavior, it is classified as toxic speech, posing a significant threat to the online ecosystem's integrity and safety. While manual content moderation is still prevalent, the overwhelming volume of content and the psychological strain on human moderators underscore the need for automated toxic speech detection. Previously proposed detection methods often rely on large annotated datasets; however, acquiring such datasets is both costly and challenging in practice. To address this issue, we propose an uncertainty-guided firewall for toxic speech in few-shot scenarios, U-GIFT, that utilizes self-training to enhance detection performance even when labeled data is limited. Specifically, U-GIFT combines active learning with Bayesian Neural Networks (BNNs) to automatically identify high-quality samples from unlabeled data, prioritizing the selection of pseudo-labels with higher confidence for training based on uncertainty estimates derived from model predictions. Extensive experiments demonstrate that U-GIFT significantly outperforms competitive baselines in few-shot detection scenarios. In the 5-shot setting, it achieves a 14.92\% performance improvement over the basic model. Importantly, U-GIFT is user-friendly and adaptable to various pre-trained language models (PLMs). It also exhibits robust performance in scenarios with sample imbalance and cross-domain settings, while showcasing strong generalization across various language applications. We believe that U-GIFT provides an efficient solution for few-shot toxic speech detection, offering substantial support for automated content moderation in cyberspace, thereby acting as a firewall to promote advancements in cybersecurity.
State-of-the-art Advances of Deep-learning Linguistic Steganalysis Research
Sep 03, 2024With the evolution of generative linguistic steganography techniques, conventional steganalysis falls short in robustly quantifying the alterations induced by steganography, thereby complicating detection. Consequently, the research paradigm has pivoted towards deep-learning-based linguistic steganalysis. This study offers a comprehensive review of existing contributions and evaluates prevailing developmental trajectories. Specifically, we first provided a formalized exposition of the general formulas for linguistic steganalysis, while comparing the differences between this field and the domain of text classification. Subsequently, we classified the existing work into two levels based on vector space mapping and feature extraction models, thereby comparing the research motivations, model advantages, and other details. A comparative analysis of the experiments is conducted to assess the performances. Finally, the challenges faced by this field are discussed, and several directions for future development and key issues that urgently need to be addressed are proposed.
Entropy Loss: An Interpretability Amplifier of 3D Object Detection Network for Intelligent Driving
Sep 01, 2024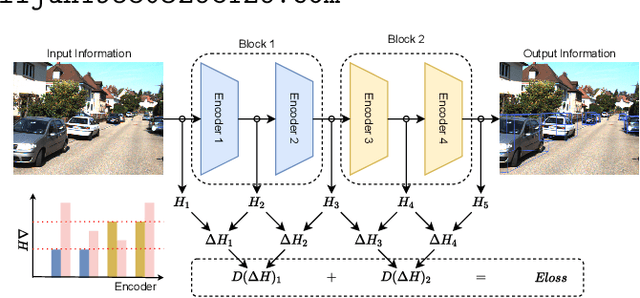
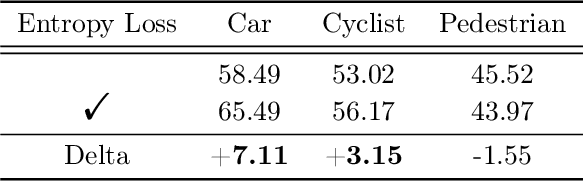
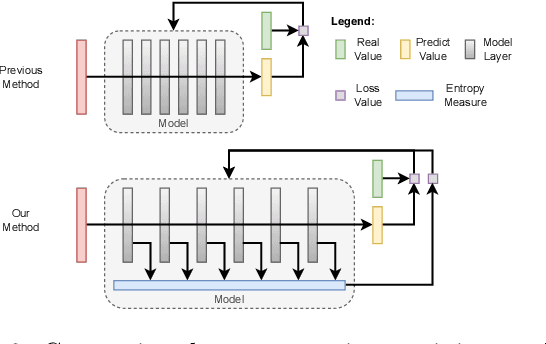
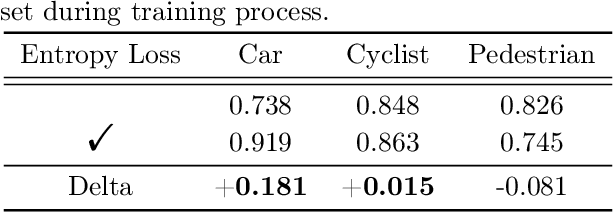
With the increasing complexity of the traffic environment, the significance of safety perception in intelligent driving is intensifying. Traditional methods in the field of intelligent driving perception rely on deep learning, which suffers from limited interpretability, often described as a "black box." This paper introduces a novel type of loss function, termed "Entropy Loss," along with an innovative training strategy. Entropy Loss is formulated based on the functionality of feature compression networks within the perception model. Drawing inspiration from communication systems, the information transmission process in a feature compression network is expected to demonstrate steady changes in information volume and a continuous decrease in information entropy. By modeling network layer outputs as continuous random variables, we construct a probabilistic model that quantifies changes in information volume. Entropy Loss is then derived based on these expectations, guiding the update of network parameters to enhance network interpretability. Our experiments indicate that the Entropy Loss training strategy accelerates the training process. Utilizing the same 60 training epochs, the accuracy of 3D object detection models using Entropy Loss on the KITTI test set improved by up to 4.47\% compared to models without Entropy Loss, underscoring the method's efficacy. The implementation code is available at \url{https://github.com/yhbcode000/Eloss-Interpretability}.
Mobile Robot Oriented Large-Scale Indoor Dataset for Dynamic Scene Understanding
Jun 28, 2024Most existing robotic datasets capture static scene data and thus are limited in evaluating robots' dynamic performance. To address this, we present a mobile robot oriented large-scale indoor dataset, denoted as THUD (Tsinghua University Dynamic) robotic dataset, for training and evaluating their dynamic scene understanding algorithms. Specifically, the THUD dataset construction is first detailed, including organization, acquisition, and annotation methods. It comprises both real-world and synthetic data, collected with a real robot platform and a physical simulation platform, respectively. Our current dataset includes 13 larges-scale dynamic scenarios, 90K image frames, 20M 2D/3D bounding boxes of static and dynamic objects, camera poses, and IMU. The dataset is still continuously expanding. Then, the performance of mainstream indoor scene understanding tasks, e.g. 3D object detection, semantic segmentation, and robot relocalization, is evaluated on our THUD dataset. These experiments reveal serious challenges for some robot scene understanding tasks in dynamic scenes. By sharing this dataset, we aim to foster and iterate new mobile robot algorithms quickly for robot actual working dynamic environment, i.e. complex crowded dynamic scenes.