 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeA Simple and Efficient Baseline for Zero-Shot Generative Classification
Dec 17, 2024



Large diffusion models have become mainstream generative models in both academic studies and industrial AIGC applications. Recently, a number of works further explored how to employ the power of large diffusion models as zero-shot classifiers. While recent zero-shot diffusion-based classifiers have made performance advancement on benchmark datasets, they still suffered badly from extremely slow classification speed (e.g., ~1000 seconds per classifying single image on ImageNet). The extremely slow classification speed strongly prohibits existing zero-shot diffusion-based classifiers from practical applications. In this paper, we propose an embarrassingly simple and efficient zero-shot Gaussian Diffusion Classifiers (GDC) via pretrained text-to-image diffusion models and DINOv2. The proposed GDC can not only significantly surpass previous zero-shot diffusion-based classifiers by over 10 points (61.40% - 71.44%) on ImageNet, but also accelerate more than 30000 times (1000 - 0.03 seconds) classifying a single image on ImageNet. Additionally, it provides probability interpretation of the results. Our extensive experiments further demonstrate that GDC can achieve highly competitive zero-shot classification performance over various datasets and can promisingly self-improve with stronger diffusion models. To the best of our knowledge, the proposed GDC is the first zero-shot diffusionbased classifier that exhibits both competitive accuracy and practical efficiency.
Entropy Loss: An Interpretability Amplifier of 3D Object Detection Network for Intelligent Driving
Sep 01, 2024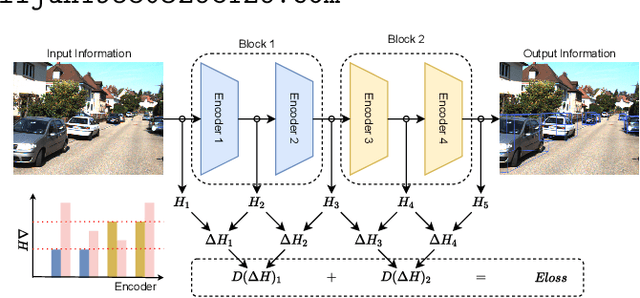
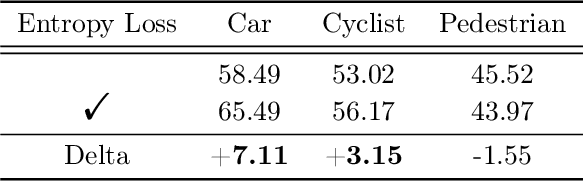
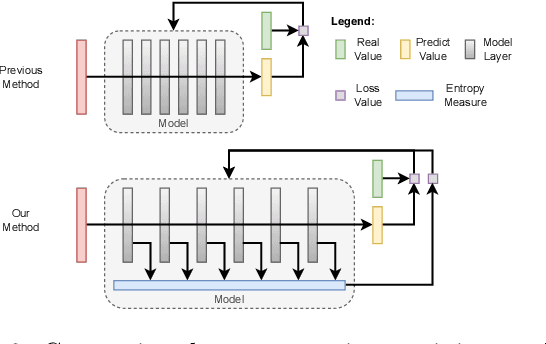
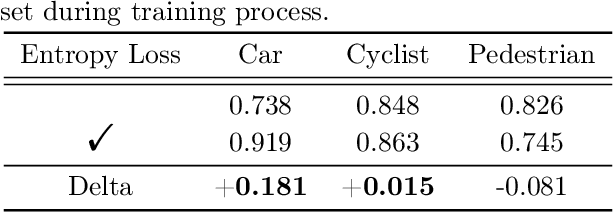
With the increasing complexity of the traffic environment, the significance of safety perception in intelligent driving is intensifying. Traditional methods in the field of intelligent driving perception rely on deep learning, which suffers from limited interpretability, often described as a "black box." This paper introduces a novel type of loss function, termed "Entropy Loss," along with an innovative training strategy. Entropy Loss is formulated based on the functionality of feature compression networks within the perception model. Drawing inspiration from communication systems, the information transmission process in a feature compression network is expected to demonstrate steady changes in information volume and a continuous decrease in information entropy. By modeling network layer outputs as continuous random variables, we construct a probabilistic model that quantifies changes in information volume. Entropy Loss is then derived based on these expectations, guiding the update of network parameters to enhance network interpretability. Our experiments indicate that the Entropy Loss training strategy accelerates the training process. Utilizing the same 60 training epochs, the accuracy of 3D object detection models using Entropy Loss on the KITTI test set improved by up to 4.47\% compared to models without Entropy Loss, underscoring the method's efficacy. The implementation code is available at \url{https://github.com/yhbcode000/Eloss-Interpretability}.
Eloss in the way: A Sensitive Input Quality Metrics for Intelligent Driving
Feb 02, 2023With the increasing complexity of the traffic environment, the importance of safety perception in intelligent driving is growing. Conventional methods in the robust perception of intelligent driving focus on training models with anomalous data, letting the deep neural network decide how to tackle anomalies. However, these models cannot adapt smoothly to the diverse and complex real-world environment. This paper proposes a new type of metric known as Eloss and offers a novel training strategy to empower perception models from the aspect of anomaly detection. Eloss is designed based on an explanation of the perception model's information compression layers. Specifically, taking inspiration from the design of a communication system, the information transmission process of an information compression network has two expectations: the amount of information changes steadily, and the information entropy continues to decrease. Then Eloss can be obtained according to the above expectations, guiding the update of related network parameters and producing a sensitive metric to identify anomalies while maintaining the model performance. Our experiments demonstrate that Eloss can deviate from the standard value by a factor over 100 with anomalous data and produce distinctive values for similar but different types of anomalies, showing the effectiveness of the proposed method. Our code is available at: (code available after paper accepted).