 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlockGaussian: Efficient Large-Scale Scene Novel View Synthesis via Adaptive Block-Based Gaussian Splatting
Apr 15, 2025
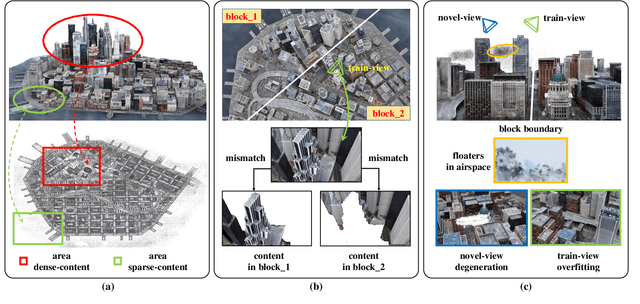
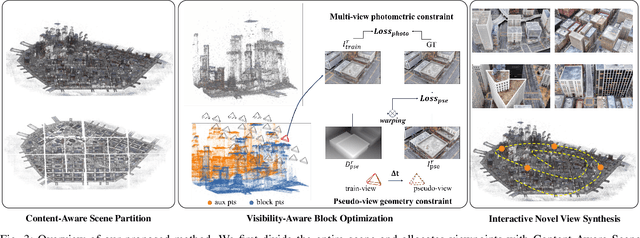
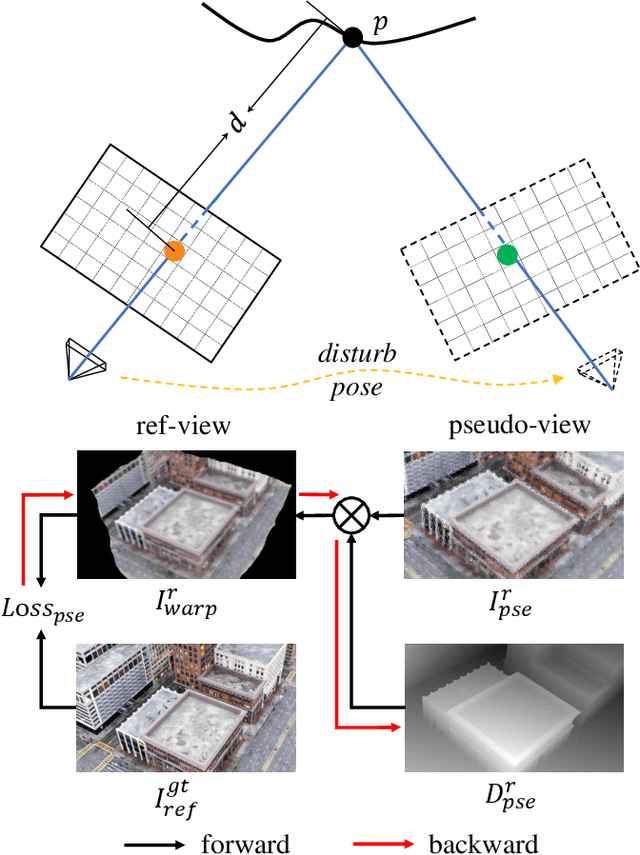
The recent advancements in 3D Gaussian Splatting (3DGS) have demonstrated remarkable potential in novel view synthesis tasks. The divide-and-conquer paradigm has enabled large-scale scene reconstruction, but significant challenges remain in scene partitioning, optimization, and merging processes. This paper introduces BlockGaussian, a novel framework incorporating a content-aware scene partition strategy and visibility-aware block optimization to achieve efficient and high-quality large-scale scene reconstruction. Specifically, our approach considers the content-complexity variation across different regions and balances computational load during scene partitioning, enabling efficient scene reconstruction. To tackle the supervision mismatch issue during independent block optimization, we introduce auxiliary points during individual block optimization to align the ground-truth supervision, which enhances the reconstruction quality. Furthermore, we propose a pseudo-view geometry constraint that effectively mitigates rendering degradation caused by airspace floaters during block merging. Extensive experiments on large-scale scenes demonstrate that our approach achieves state-of-the-art performance in both reconstruction efficiency and rendering quality, with a 5x speedup in optimization and an average PSNR improvement of 1.21 dB on multiple benchmarks. Notably, BlockGaussian significantly reduces computational requirements, enabling large-scale scene reconstruction on a single 24GB VRAM device. The project page is available at https://github.com/SunshineWYC/BlockGaussian
Bayesian Neural Networks for One-to-Many Mapping in Image Enhancement
Jan 24, 2025



In image enhancement tasks, such as low-light and underwater image enhancement, a degraded image can correspond to multiple plausible target images due to dynamic photography conditions, such as variations in illumination. This naturally results in a one-to-many mapping challenge. To address this, we propose a Bayesian Enhancement Model (BEM) that incorporates Bayesian Neural Networks (BNNs) to capture data uncertainty and produce diverse outputs. To achieve real-time inference, we introduce a two-stage approach: Stage I employs a BNN to model the one-to-many mappings in the low-dimensional space, while Stage II refines fine-grained image details using a Deterministic Neural Network (DNN). To accelerate BNN training and convergence, we introduce a dynamic \emph{Momentum Prior}. Extensive experiments on multiple low-light and underwater image enhancement benchmarks demonstrate the superiority of our method over deterministic models.
Zigzag Diffusion Sampling: Diffusion Models Can Self-Improve via Self-Reflection
Dec 17, 2024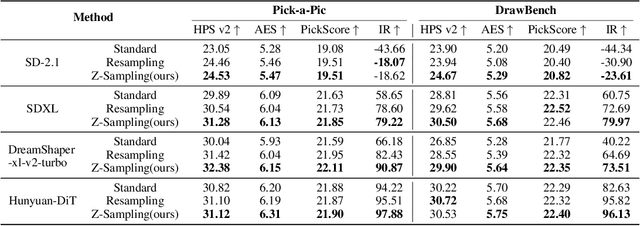


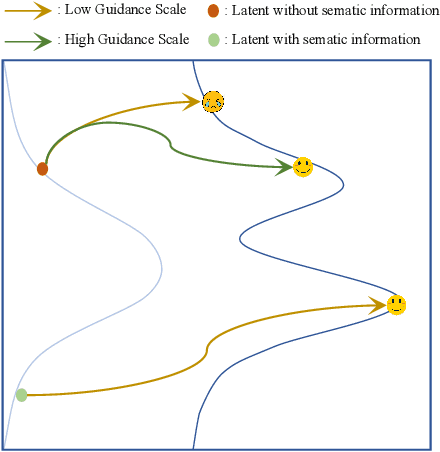
Diffusion models, the most popular generative paradigm so far, can inject conditional information into the generation path to guide the latent towards desired directions. However, existing text-to-image diffusion models often fail to maintain high image quality and high prompt-image alignment for those challenging prompts. To mitigate this issue and enhance existing pretrained diffusion models, we mainly made three contributions in this paper. First, we propose diffusion self-reflection that alternately performs denoising and inversion and demonstrate that such diffusion self-reflection can leverage the guidance gap between denoising and inversion to capture prompt-related semantic information with theoretical and empirical evidence. Second, motivated by theoretical analysis, we derive Zigzag Diffusion Sampling (Z-Sampling), a novel self-reflection-based diffusion sampling method that leverages the guidance gap between denosing and inversion to accumulate semantic information step by step along the sampling path, leading to improved sampling results. Moreover, as a plug-and-play method, Z-Sampling can be generally applied to various diffusion models (e.g., accelerated ones and Transformer-based ones) with very limited coding and computational costs. Third, our extensive experiments demonstrate that Z-Sampling can generally and significantly enhance generation quality across various benchmark datasets, diffusion models, and performance evaluation metrics. For example, DreamShaper with Z-Sampling can self-improve with the HPSv2 winning rate up to 94% over the original results. Moreover, Z-Sampling can further enhance existing diffusion models combined with other orthogonal methods, including Diffusion-DPO.
A Simple and Efficient Baseline for Zero-Shot Generative Classification
Dec 17, 2024



Large diffusion models have become mainstream generative models in both academic studies and industrial AIGC applications. Recently, a number of works further explored how to employ the power of large diffusion models as zero-shot classifiers. While recent zero-shot diffusion-based classifiers have made performance advancement on benchmark datasets, they still suffered badly from extremely slow classification speed (e.g., ~1000 seconds per classifying single image on ImageNet). The extremely slow classification speed strongly prohibits existing zero-shot diffusion-based classifiers from practical applications. In this paper, we propose an embarrassingly simple and efficient zero-shot Gaussian Diffusion Classifiers (GDC) via pretrained text-to-image diffusion models and DINOv2. The proposed GDC can not only significantly surpass previous zero-shot diffusion-based classifiers by over 10 points (61.40% - 71.44%) on ImageNet, but also accelerate more than 30000 times (1000 - 0.03 seconds) classifying a single image on ImageNet. Additionally, it provides probability interpretation of the results. Our extensive experiments further demonstrate that GDC can achieve highly competitive zero-shot classification performance over various datasets and can promisingly self-improve with stronger diffusion models. To the best of our knowledge, the proposed GDC is the first zero-shot diffusionbased classifier that exhibits both competitive accuracy and practical efficiency.
Efficient Semantic Splatting for Remote Sensing Multi-view Segmentation
Dec 08, 2024



In this paper, we propose a novel semantic splatting approach based on Gaussian Splatting to achieve efficient and low-latency. Our method projects the RGB attributes and semantic features of point clouds onto the image plane, simultaneously rendering RGB images and semantic segmentation results. Leveraging the explicit structure of point clouds and a one-time rendering strategy, our approach significantly enhances efficiency during optimization and rendering. Additionally, we employ SAM2 to generate pseudo-labels for boundary regions, which often lack sufficient supervision, and introduce two-level aggregation losses at the 2D feature map and 3D spatial levels to improve the view-consistent and spatial continuity.
Not All Noises Are Created Equally:Diffusion Noise Selection and Optimization
Jul 19, 2024



Diffusion models that can generate high-quality data from randomly sampled Gaussian noises have become the mainstream generative method in both academia and industry. Are randomly sampled Gaussian noises equally good for diffusion models? While a large body of works tried to understand and improve diffusion models, previous works overlooked the possibility to select or optimize the sampled noise the possibility of selecting or optimizing sampled noises for improving diffusion models. In this paper, we mainly made three contributions. First, we report that not all noises are created equally for diffusion models. We are the first to hypothesize and empirically observe that the generation quality of diffusion models significantly depend on the noise inversion stability. This naturally provides us a noise selection method according to the inversion stability. Second, we further propose a novel noise optimization method that actively enhances the inversion stability of arbitrary given noises. Our method is the first one that works on noise space to generally improve generated results without fine-tuning diffusion models. Third, our extensive experiments demonstrate that the proposed noise selection and noise optimization methods both significantly improve representative diffusion models, such as SDXL and SDXL-turbo, in terms of human preference and other objective evaluation metrics. For example, the human preference winning rates of noise selection and noise optimization over the baselines can be up to 57% and 72.5%, respectively, on DrawBench.
Multi-view Remote Sensing Image Segmentation With SAM priors
May 23, 2024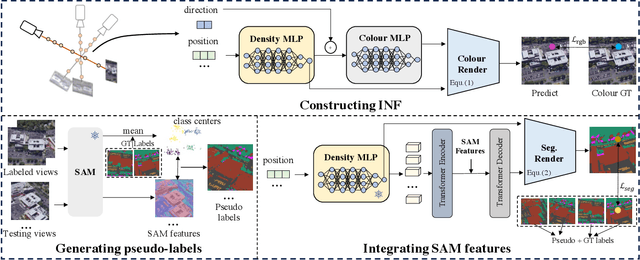
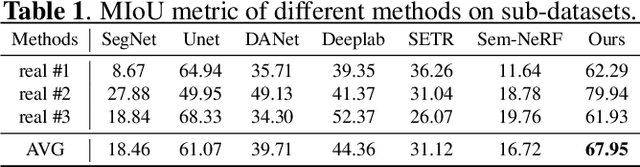
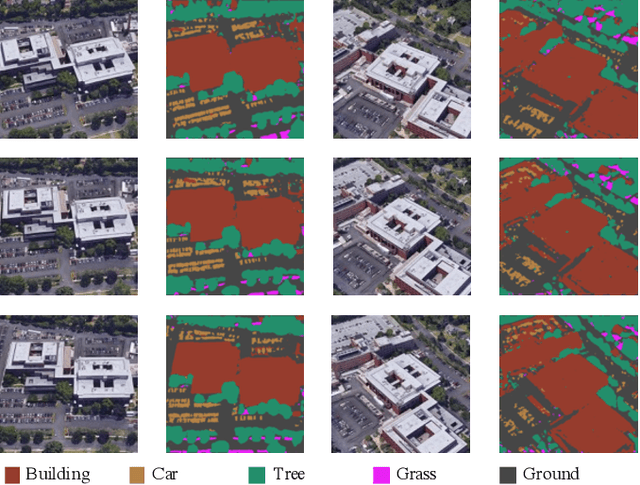
Multi-view segmentation in Remote Sensing (RS) seeks to segment images from diverse perspectives within a scene. Recent methods leverage 3D information extracted from an Implicit Neural Field (INF), bolstering result consistency across multiple views while using limited accounts of labels (even within 3-5 labels) to streamline labor. Nonetheless, achieving superior performance within the constraints of limited-view labels remains challenging due to inadequate scene-wide supervision and insufficient semantic features within the INF. To address these. we propose to inject the prior of the visual foundation model-Segment Anything(SAM), to the INF to obtain better results under the limited number of training data. Specifically, we contrast SAM features between testing and training views to derive pseudo labels for each testing view, augmenting scene-wide labeling information. Subsequently, we introduce SAM features via a transformer into the INF of the scene, supplementing the semantic information. The experimental results demonstrate that our method outperforms the mainstream method, confirming the efficacy of SAM as a supplement to the INF for this task.
Change-Agent: Towards Interactive Comprehensive Remote Sensing Change Interpretation and Analysis
Apr 01, 2024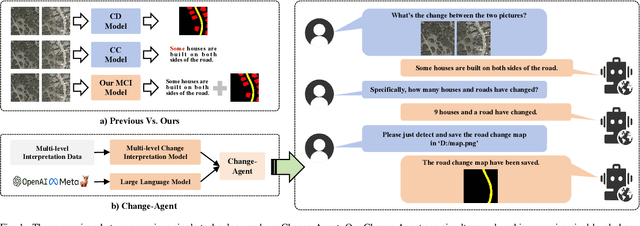


Monitoring changes in the Earth's surface is crucial for understanding natural processes and human impacts, necessitating precise and comprehensive interpretation methodologies. Remote sensing satellite imagery offers a unique perspective for monitoring these changes, leading to the emergence of remote sensing image change interpretation (RSICI) as a significant research focus. Current RSICI technology encompasses change detection and change captioning, each with its limitations in providing comprehensive interpretation. To address this, we propose an interactive Change-Agent, which can follow user instructions to achieve comprehensive change interpretation and insightful analysis according to user instructions, such as change detection and change captioning, change object counting, change cause analysis, etc. The Change-Agent integrates a multi-level change interpretation (MCI) model as the eyes and a large language model (LLM) as the brain. The MCI model contains two branches of pixel-level change detection and semantic-level change captioning, in which multiple BI-temporal Iterative Interaction (BI3) layers utilize Local Perception Enhancement (LPE) and the Global Difference Fusion Attention (GDFA) modules to enhance the model's discriminative feature representation capabilities. To support the training of the MCI model, we build the LEVIR-MCI dataset with a large number of change masks and captions of changes. Extensive experiments demonstrate the effectiveness of the proposed MCI model and highlight the promising potential of our Change-Agent in facilitating comprehensive and intelligent interpretation of surface changes. To facilitate future research, we will make our dataset and codebase of the MCI model and Change-Agent publicly available at https://github.com/Chen-Yang-Liu/Change-Agent
Learning to detect cloud and snow in remote sensing images from noisy labels
Jan 17, 2024


Detecting clouds and snow in remote sensing images is an essential preprocessing task for remote sensing imagery. Previous works draw inspiration from semantic segmentation models in computer vision, with most research focusing on improving model architectures to enhance detection performance. However, unlike natural images, the complexity of scenes and the diversity of cloud types in remote sensing images result in many inaccurate labels in cloud and snow detection datasets, introducing unnecessary noises into the training and testing processes. By constructing a new dataset and proposing a novel training strategy with the curriculum learning paradigm, we guide the model in reducing overfitting to noisy labels. Additionally, we design a more appropriate model performance evaluation method, that alleviates the performance assessment bias caused by noisy labels. By conducting experiments on models with UNet and Segformer, we have validated the effectiveness of our proposed method. This paper is the first to consider the impact of label noise on the detection of clouds and snow in remote sensing images.
Pixel-Level Change Detection Pseudo-Label Learning for Remote Sensing Change Captioning
Dec 23, 2023


The existing methods for Remote Sensing Image Change Captioning (RSICC) perform well in simple scenes but exhibit poorer performance in complex scenes. This limitation is primarily attributed to the model's constrained visual ability to distinguish and locate changes. Acknowledging the inherent correlation between change detection (CD) and RSICC tasks, we believe pixel-level CD is significant for describing the differences between images through language. Regrettably, the current RSICC dataset lacks readily available pixel-level CD labels. To address this deficiency, we leverage a model trained on existing CD datasets to derive CD pseudo-labels. We propose an innovative network with an auxiliary CD branch, supervised by pseudo-labels. Furthermore, a semantic fusion augment (SFA) module is proposed to fuse the feature information extracted by the CD branch, thereby facilitating the nuanced description of changes. Experiments demonstrate that our method achieves state-of-the-art performance and validate that learning pixel-level CD pseudo-labels significantly contributes to change captioning. Our code will be available at: https://github.com/Chen-Yang-Liu/Pix4Cap