 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDynamic Weight-based Temporal Aggregation for Low-light Video Enhancement
Oct 10, 2025Low-light video enhancement (LLVE) is challenging due to noise, low contrast, and color degradations. Learning-based approaches offer fast inference but still struggle with heavy noise in real low-light scenes, primarily due to limitations in effectively leveraging temporal information. In this paper, we address this issue with DWTA-Net, a novel two-stage framework that jointly exploits short- and long-term temporal cues. Stage I employs Visual State-Space blocks for multi-frame alignment, recovering brightness, color, and structure with local consistency. Stage II introduces a recurrent refinement module with dynamic weight-based temporal aggregation guided by optical flow, adaptively balancing static and dynamic regions. A texture-adaptive loss further preserves fine details while promoting smoothness in flat areas. Experiments on real-world low-light videos show that DWTA-Net effectively suppresses noise and artifacts, delivering superior visual quality compared with state-of-the-art methods.
RUSplatting: Robust 3D Gaussian Splatting for Sparse-View Underwater Scene Reconstruction
May 21, 2025Reconstructing high-fidelity underwater scenes remains a challenging task due to light absorption, scattering, and limited visibility inherent in aquatic environments. This paper presents an enhanced Gaussian Splatting-based framework that improves both the visual quality and geometric accuracy of deep underwater rendering. We propose decoupled learning for RGB channels, guided by the physics of underwater attenuation, to enable more accurate colour restoration. To address sparse-view limitations and improve view consistency, we introduce a frame interpolation strategy with a novel adaptive weighting scheme. Additionally, we introduce a new loss function aimed at reducing noise while preserving edges, which is essential for deep-sea content. We also release a newly collected dataset, Submerged3D, captured specifically in deep-sea environments. Experimental results demonstrate that our framework consistently outperforms state-of-the-art methods with PSNR gains up to 1.90dB, delivering superior perceptual quality and robustness, and offering promising directions for marine robotics and underwater visual analytics.
Visual enhancement and 3D representation for underwater scenes: a review
May 03, 2025



Underwater visual enhancement (UVE) and underwater 3D reconstruction pose significant challenges in computer vision and AI-based tasks due to complex imaging conditions in aquatic environments. Despite the development of numerous enhancement algorithms, a comprehensive and systematic review covering both UVE and underwater 3D reconstruction remains absent. To advance research in these areas, we present an in-depth review from multiple perspectives. First, we introduce the fundamental physical models, highlighting the peculiarities that challenge conventional techniques. We survey advanced methods for visual enhancement and 3D reconstruction specifically designed for underwater scenarios. The paper assesses various approaches from non-learning methods to advanced data-driven techniques, including Neural Radiance Fields and 3D Gaussian Splatting, discussing their effectiveness in handling underwater distortions. Finally, we conduct both quantitative and qualitative evaluations of state-of-the-art UVE and underwater 3D reconstruction algorithms across multiple benchmark datasets. Finally, we highlight key research directions for future advancements in underwater vision.
Marine Snow Removal Using Internally Generated Pseudo Ground Truth
Apr 27, 2025Underwater videos often suffer from degraded quality due to light absorption, scattering, and various noise sources. Among these, marine snow, which is suspended organic particles appearing as bright spots or noise, significantly impacts machine vision tasks, particularly those involving feature matching. Existing methods for removing marine snow are ineffective due to the lack of paired training data. To address this challenge, this paper proposes a novel enhancement framework that introduces a new approach for generating paired datasets from raw underwater videos. The resulting dataset consists of paired images of generated snowy and snow, free underwater videos, enabling supervised training for video enhancement. We describe the dataset creation process, highlight its key characteristics, and demonstrate its effectiveness in enhancing underwater image restoration in the absence of ground truth.
NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images: Methods and Results
Apr 19, 2025



This paper reviews the NTIRE 2025 Challenge on Day and Night Raindrop Removal for Dual-Focused Images. This challenge received a wide range of impressive solutions, which are developed and evaluated using our collected real-world Raindrop Clarity dataset. Unlike existing deraining datasets, our Raindrop Clarity dataset is more diverse and challenging in degradation types and contents, which includes day raindrop-focused, day background-focused, night raindrop-focused, and night background-focused degradations. This dataset is divided into three subsets for competition: 14,139 images for training, 240 images for validation, and 731 images for testing. The primary objective of this challenge is to establish a new and powerful benchmark for the task of removing raindrops under varying lighting and focus conditions. There are a total of 361 participants in the competition, and 32 teams submitting valid solutions and fact sheets for the final testing phase. These submissions achieved state-of-the-art (SOTA) performance on the Raindrop Clarity dataset. The project can be found at https://lixinustc.github.io/CVPR-NTIRE2025-RainDrop-Competition.github.io/.
Bayesian Neural Networks for One-to-Many Mapping in Image Enhancement
Jan 24, 2025



In image enhancement tasks, such as low-light and underwater image enhancement, a degraded image can correspond to multiple plausible target images due to dynamic photography conditions, such as variations in illumination. This naturally results in a one-to-many mapping challenge. To address this, we propose a Bayesian Enhancement Model (BEM) that incorporates Bayesian Neural Networks (BNNs) to capture data uncertainty and produce diverse outputs. To achieve real-time inference, we introduce a two-stage approach: Stage I employs a BNN to model the one-to-many mappings in the low-dimensional space, while Stage II refines fine-grained image details using a Deterministic Neural Network (DNN). To accelerate BNN training and convergence, we introduce a dynamic \emph{Momentum Prior}. Extensive experiments on multiple low-light and underwater image enhancement benchmarks demonstrate the superiority of our method over deterministic models.
Incrementally Learning Multiple Diverse Data Domains via Multi-Source Dynamic Expansion Model
Jan 15, 2025



Continual Learning seeks to develop a model capable of incrementally assimilating new information while retaining prior knowledge. However, current research predominantly addresses a straightforward learning context, wherein all data samples originate from a singular data domain. This paper shifts focus to a more complex and realistic learning environment, characterized by data samples sourced from multiple distinct domains. We tackle this intricate learning challenge by introducing a novel methodology, termed the Multi-Source Dynamic Expansion Model (MSDEM), which leverages various pre-trained models as backbones and progressively establishes new experts based on them to adapt to emerging tasks. Additionally, we propose an innovative dynamic expandable attention mechanism designed to selectively harness knowledge from multiple backbones, thereby accelerating the new task learning. Moreover, we introduce a dynamic graph weight router that strategically reuses all previously acquired parameters and representations for new task learning, maximizing the positive knowledge transfer effect, which further improves generalization performance. We conduct a comprehensive series of experiments, and the empirical findings indicate that our proposed approach achieves state-of-the-art performance.
BVI-RLV: A Fully Registered Dataset and Benchmarks for Low-Light Video Enhancement
Jul 03, 2024
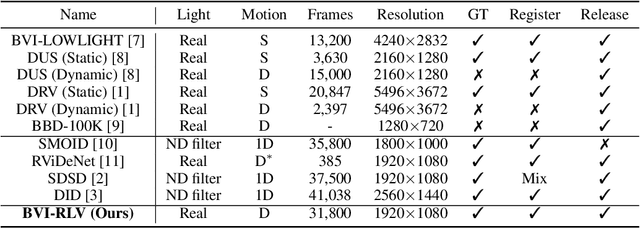
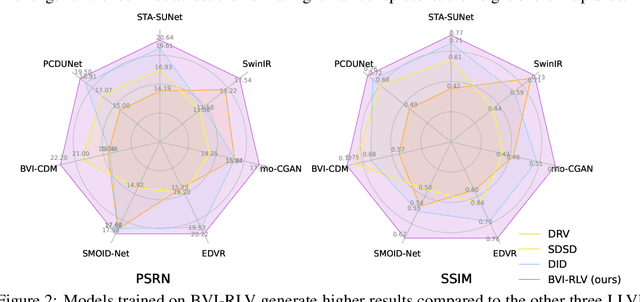
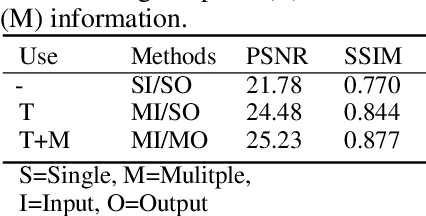
Low-light videos often exhibit spatiotemporal incoherent noise, compromising visibility and performance in computer vision applications. One significant challenge in enhancing such content using deep learning is the scarcity of training data. This paper introduces a novel low-light video dataset, consisting of 40 scenes with various motion scenarios under two distinct low-lighting conditions, incorporating genuine noise and temporal artifacts. We provide fully registered ground truth data captured in normal light using a programmable motorized dolly and refine it via an image-based approach for pixel-wise frame alignment across different light levels. We provide benchmarks based on four different technologies: convolutional neural networks, transformers, diffusion models, and state space models (mamba). Our experimental results demonstrate the significance of fully registered video pairs for low-light video enhancement (LLVE) and the comprehensive evaluation shows that the models trained with our dataset outperform those trained with the existing datasets. Our dataset and links to benchmarks are publicly available at https://doi.org/10.21227/mzny-8c77.
Layered Rendering Diffusion Model for Zero-Shot Guided Image Synthesis
Nov 30, 2023This paper introduces innovative solutions to enhance spatial controllability in diffusion models reliant on text queries. We present two key innovations: Vision Guidance and the Layered Rendering Diffusion (LRDiff) framework. Vision Guidance, a spatial layout condition, acts as a clue in the perturbed distribution, greatly narrowing down the search space, to focus on the image sampling process adhering to the spatial layout condition. The LRDiff framework constructs an image-rendering process with multiple layers, each of which applies the vision guidance to instructively estimate the denoising direction for a single object. Such a layered rendering strategy effectively prevents issues like unintended conceptual blending or mismatches, while allowing for more coherent and contextually accurate image synthesis. The proposed method provides a more efficient and accurate means of synthesising images that align with specific spatial and contextual requirements. We demonstrate through our experiments that our method provides better results than existing techniques both quantitatively and qualitatively. We apply our method to three practical applications: bounding box-to-image, semantic mask-to-image and image editing.
Masked Image Residual Learning for Scaling Deeper Vision Transformers
Sep 25, 2023Deeper Vision Transformers (ViTs) are more challenging to train. We expose a degradation problem in deeper layers of ViT when using masked image modeling (MIM) for pre-training. To ease the training of deeper ViTs, we introduce a self-supervised learning framework called \textbf{M}asked \textbf{I}mage \textbf{R}esidual \textbf{L}earning (\textbf{MIRL}), which significantly alleviates the degradation problem, making scaling ViT along depth a promising direction for performance upgrade. We reformulate the pre-training objective for deeper layers of ViT as learning to recover the residual of the masked image. We provide extensive empirical evidence showing that deeper ViTs can be effectively optimized using MIRL and easily gain accuracy from increased depth. With the same level of computational complexity as ViT-Base and ViT-Large, we instantiate 4.5{$\times$} and 2{$\times$} deeper ViTs, dubbed ViT-S-54 and ViT-B-48. The deeper ViT-S-54, costing 3{$\times$} less than ViT-Large, achieves performance on par with ViT-Large. ViT-B-48 achieves 86.2\% top-1 accuracy on ImageNet. On one hand, deeper ViTs pre-trained with MIRL exhibit excellent generalization capabilities on downstream tasks, such as object detection and semantic segmentation. On the other hand, MIRL demonstrates high pre-training efficiency. With less pre-training time, MIRL yields competitive performance compared to other approaches.