 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeIncrementally Learning Multiple Diverse Data Domains via Multi-Source Dynamic Expansion Model
Jan 15, 2025



Continual Learning seeks to develop a model capable of incrementally assimilating new information while retaining prior knowledge. However, current research predominantly addresses a straightforward learning context, wherein all data samples originate from a singular data domain. This paper shifts focus to a more complex and realistic learning environment, characterized by data samples sourced from multiple distinct domains. We tackle this intricate learning challenge by introducing a novel methodology, termed the Multi-Source Dynamic Expansion Model (MSDEM), which leverages various pre-trained models as backbones and progressively establishes new experts based on them to adapt to emerging tasks. Additionally, we propose an innovative dynamic expandable attention mechanism designed to selectively harness knowledge from multiple backbones, thereby accelerating the new task learning. Moreover, we introduce a dynamic graph weight router that strategically reuses all previously acquired parameters and representations for new task learning, maximizing the positive knowledge transfer effect, which further improves generalization performance. We conduct a comprehensive series of experiments, and the empirical findings indicate that our proposed approach achieves state-of-the-art performance.
Diffusion Models Meet Network Management: Improving Traffic Matrix Analysis with Diffusion-based Approach
Nov 29, 2024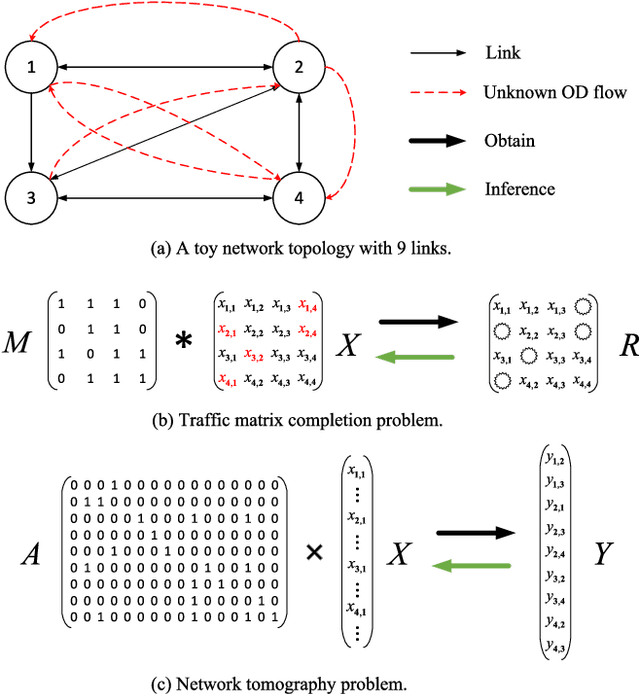
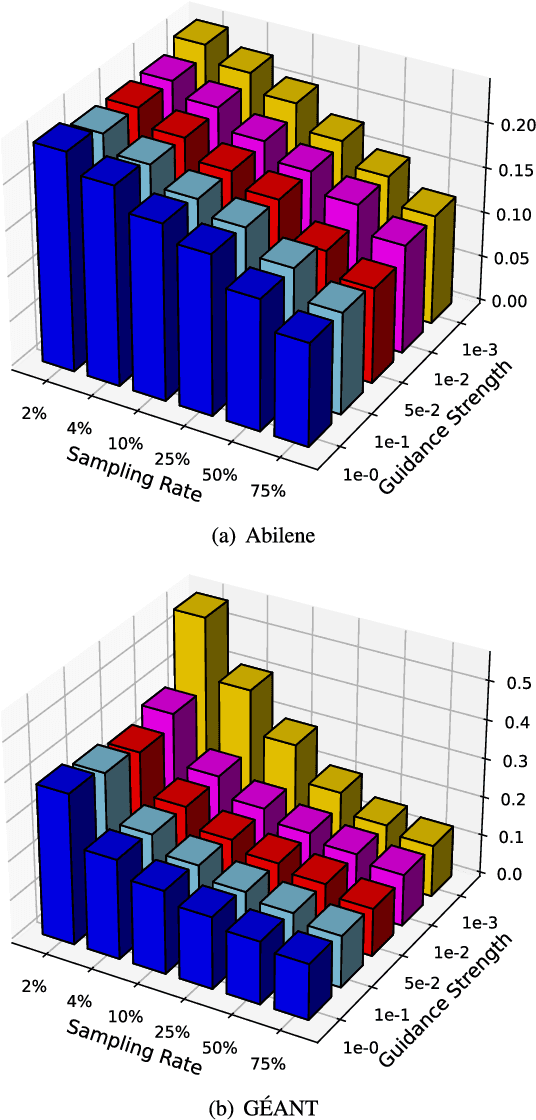
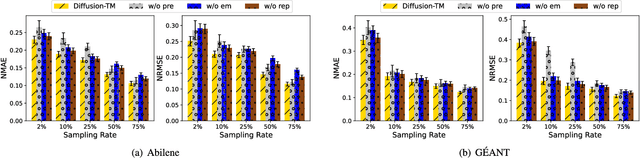
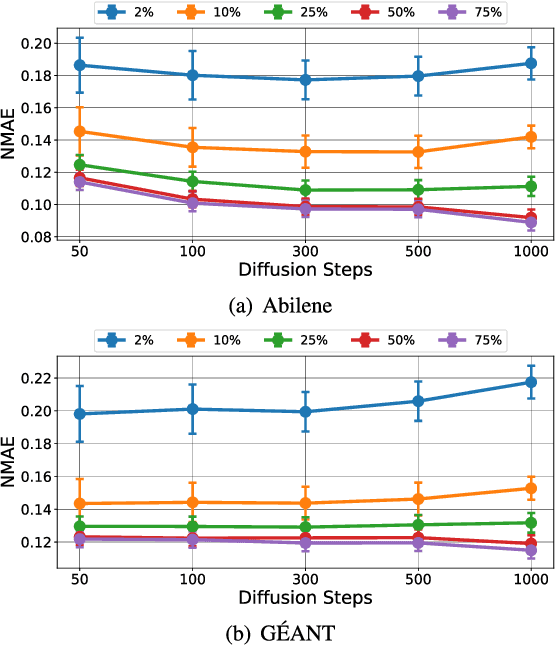
Due to network operation and maintenance relying heavily on network traffic monitoring, traffic matrix analysis has been one of the most crucial issues for network management related tasks. However, it is challenging to reliably obtain the precise measurement in computer networks because of the high measurement cost, and the unavoidable transmission loss. Although some methods proposed in recent years allowed estimating network traffic from partial flow-level or link-level measurements, they often perform poorly for traffic matrix estimation nowadays. Despite strong assumptions like low-rank structure and the prior distribution, existing techniques are usually task-specific and tend to be significantly worse as modern network communication is extremely complicated and dynamic. To address the dilemma, this paper proposed a diffusion-based traffic matrix analysis framework named Diffusion-TM, which leverages problem-agnostic diffusion to notably elevate the estimation performance in both traffic distribution and accuracy. The novel framework not only takes advantage of the powerful generative ability of diffusion models to produce realistic network traffic, but also leverages the denoising process to unbiasedly estimate all end-to-end traffic in a plug-and-play manner under theoretical guarantee. Moreover, taking into account that compiling an intact traffic dataset is usually infeasible, we also propose a two-stage training scheme to make our framework be insensitive to missing values in the dataset. With extensive experiments with real-world datasets, we illustrate the effectiveness of Diffusion-TM on several tasks. Moreover, the results also demonstrate that our method can obtain promising results even with $5\%$ known values left in the datasets.
Traffic Matrix Estimation based on Denoising Diffusion Probabilistic Model
Oct 21, 2024



The traffic matrix estimation (TME) problem has been widely researched for decades of years. Recent progresses in deep generative models offer new opportunities to tackle TME problems in a more advanced way. In this paper, we leverage the powerful ability of denoising diffusion probabilistic models (DDPMs) on distribution learning, and for the first time adopt DDPM to address the TME problem. To ensure a good performance of DDPM on learning the distributions of TMs, we design a preprocessing module to reduce the dimensions of TMs while keeping the data variety of each OD flow. To improve the estimation accuracy, we parameterize the noise factors in DDPM and transform the TME problem into a gradient-descent optimization problem. Finally, we compared our method with the state-of-the-art TME methods using two real-world TM datasets, the experimental results strongly demonstrate the superiority of our method on both TM synthesis and TM estimation.
Joint Prediction and Time Estimation of COVID-19 Developing Severe Symptoms using Chest CT Scan
May 07, 2020
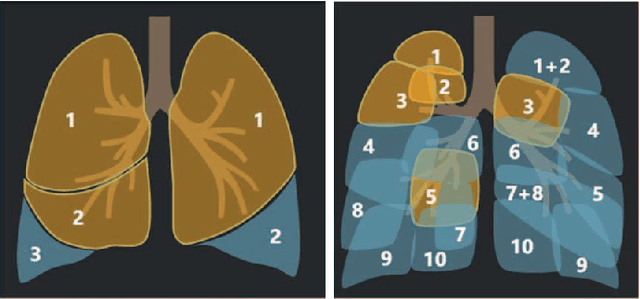
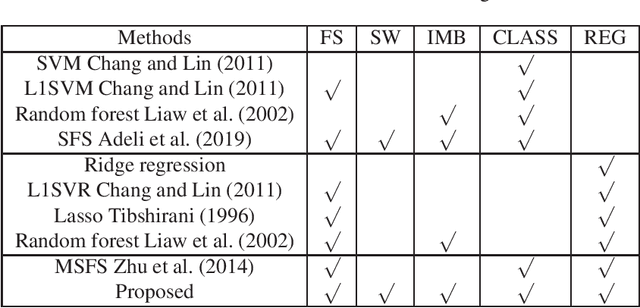
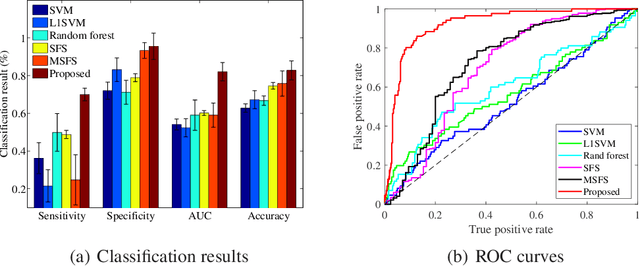
With the rapidly worldwide spread of Coronavirus disease (COVID-19), it is of great importance to conduct early diagnosis of COVID-19 and predict the time that patients might convert to the severe stage, for designing effective treatment plan and reducing the clinicians' workloads. In this study, we propose a joint classification and regression method to determine whether the patient would develop severe symptoms in the later time, and if yes, predict the possible conversion time that the patient would spend to convert to the severe stage. To do this, the proposed method takes into account 1) the weight for each sample to reduce the outliers' influence and explore the problem of imbalance classification, and 2) the weight for each feature via a sparsity regularization term to remove the redundant features of high-dimensional data and learn the shared information across the classification task and the regression task. To our knowledge, this study is the first work to predict the disease progression and the conversion time, which could help clinicians to deal with the potential severe cases in time or even save the patients' lives. Experimental analysis was conducted on a real data set from two hospitals with 422 chest computed tomography (CT) scans, where 52 cases were converted to severe on average 5.64 days and 34 cases were severe at admission. Results show that our method achieves the best classification (e.g., 85.91% of accuracy) and regression (e.g., 0.462 of the correlation coefficient) performance, compared to all comparison methods. Moreover, our proposed method yields 76.97% of accuracy for predicting the severe cases, 0.524 of the correlation coefficient, and 0.55 days difference for the converted time.