 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNoise-Robustness Through Noise: Asymmetric LoRA Adaption with Poisoning Expert
May 29, 2025Current parameter-efficient fine-tuning methods for adapting pre-trained language models to downstream tasks are susceptible to interference from noisy data. Conventional noise-handling approaches either rely on laborious data pre-processing or employ model architecture modifications prone to error accumulation. In contrast to existing noise-process paradigms, we propose a noise-robust adaptation method via asymmetric LoRA poisoning experts (LoPE), a novel framework that enhances model robustness to noise only with generated noisy data. Drawing inspiration from the mixture-of-experts architecture, LoPE strategically integrates a dedicated poisoning expert in an asymmetric LoRA configuration. Through a two-stage paradigm, LoPE performs noise injection on the poisoning expert during fine-tuning to enhance its noise discrimination and processing ability. During inference, we selectively mask the dedicated poisoning expert to leverage purified knowledge acquired by normal experts for noise-robust output. Extensive experiments demonstrate that LoPE achieves strong performance and robustness purely through the low-cost noise injection, which completely eliminates the requirement of data cleaning.
HASH-RAG: Bridging Deep Hashing with Retriever for Efficient, Fine Retrieval and Augmented Generation
May 22, 2025Retrieval-Augmented Generation (RAG) encounters efficiency challenges when scaling to massive knowledge bases while preserving contextual relevance. We propose Hash-RAG, a framework that integrates deep hashing techniques with systematic optimizations to address these limitations. Our queries directly learn binary hash codes from knowledgebase code, eliminating intermediate feature extraction steps, and significantly reducing storage and computational overhead. Building upon this hash-based efficient retrieval framework, we establish the foundation for fine-grained chunking. Consequently, we design a Prompt-Guided Chunk-to-Context (PGCC) module that leverages retrieved hash-indexed propositions and their original document segments through prompt engineering to enhance the LLM's contextual awareness. Experimental evaluations on NQ, TriviaQA, and HotpotQA datasets demonstrate that our approach achieves a 90% reduction in retrieval time compared to conventional methods while maintaining considerate recall performance. Additionally, The proposed system outperforms retrieval/non-retrieval baselines by 1.4-4.3% in EM scores.
Accelerating Adaptive Retrieval Augmented Generation via Instruction-Driven Representation Reduction of Retrieval Overlaps
May 19, 2025Retrieval-augmented generation (RAG) has emerged as a pivotal method for expanding the knowledge of large language models. To handle complex queries more effectively, researchers developed Adaptive-RAG (A-RAG) to enhance the generated quality through multiple interactions with external knowledge bases. Despite its effectiveness, A-RAG exacerbates the pre-existing efficiency challenges inherent in RAG, which are attributable to its reliance on multiple iterations of generation. Existing A-RAG approaches process all retrieved contents from scratch. However, they ignore the situation where there is a significant overlap in the content of the retrieval results across rounds. The overlapping content is redundantly represented, which leads to a large proportion of repeated computations, thus affecting the overall efficiency. To address this issue, this paper introduces a model-agnostic approach that can be generally applied to A-RAG methods, which is dedicated to reducing the redundant representation process caused by the overlapping of retrieval results. Specifically, we use cache access and parallel generation to speed up the prefilling and decoding stages respectively. Additionally, we also propose an instruction-driven module to further guide the model to more effectively attend to each part of the content in a more suitable way for LLMs. Experiments show that our approach achieves 2.79 and 2.33 times significant acceleration on average for prefilling and decoding respectively while maintaining equal generation quality.
Incrementally Learning Multiple Diverse Data Domains via Multi-Source Dynamic Expansion Model
Jan 15, 2025



Continual Learning seeks to develop a model capable of incrementally assimilating new information while retaining prior knowledge. However, current research predominantly addresses a straightforward learning context, wherein all data samples originate from a singular data domain. This paper shifts focus to a more complex and realistic learning environment, characterized by data samples sourced from multiple distinct domains. We tackle this intricate learning challenge by introducing a novel methodology, termed the Multi-Source Dynamic Expansion Model (MSDEM), which leverages various pre-trained models as backbones and progressively establishes new experts based on them to adapt to emerging tasks. Additionally, we propose an innovative dynamic expandable attention mechanism designed to selectively harness knowledge from multiple backbones, thereby accelerating the new task learning. Moreover, we introduce a dynamic graph weight router that strategically reuses all previously acquired parameters and representations for new task learning, maximizing the positive knowledge transfer effect, which further improves generalization performance. We conduct a comprehensive series of experiments, and the empirical findings indicate that our proposed approach achieves state-of-the-art performance.
Reconstructing Three-decade Global Fine-Grained Nighttime Light Observations by a New Super-Resolution Framework
Jul 14, 2023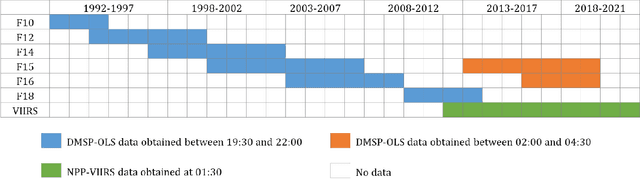
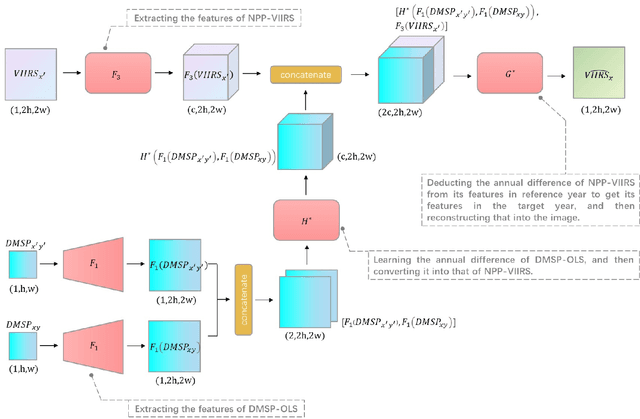
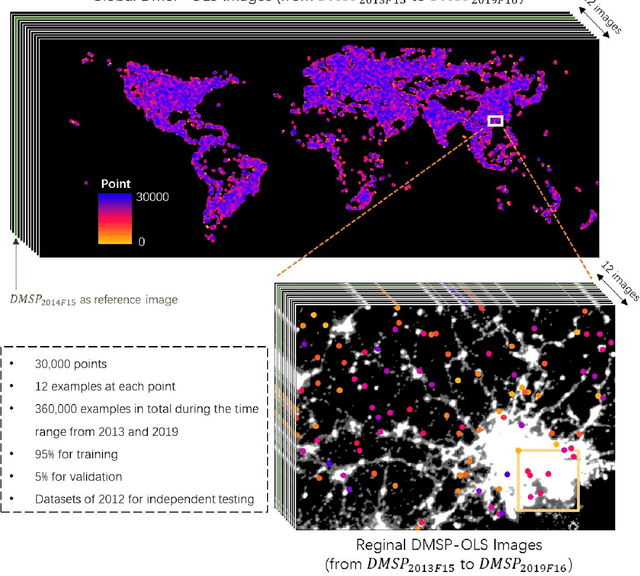
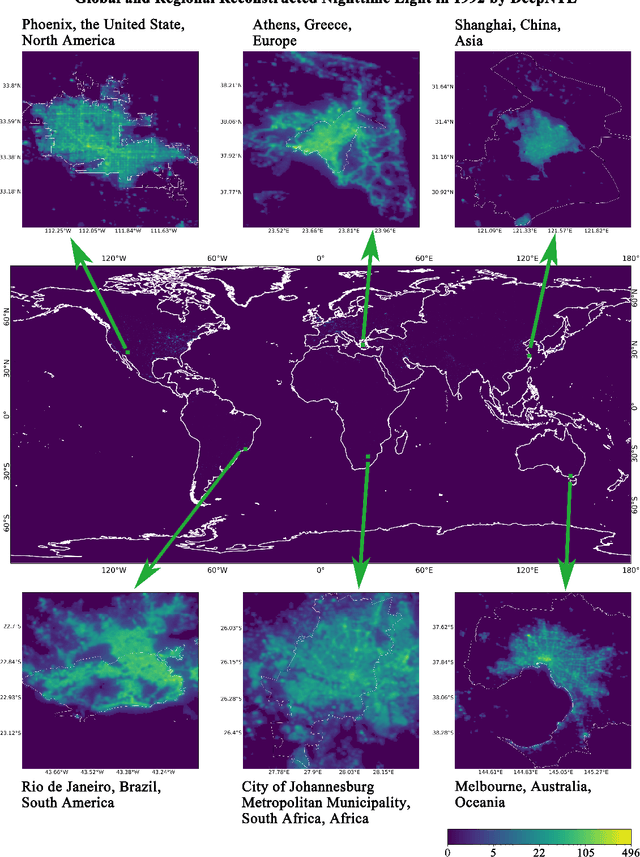
Satellite-collected nighttime light provides a unique perspective on human activities, including urbanization, population growth, and epidemics. Yet, long-term and fine-grained nighttime light observations are lacking, leaving the analysis and applications of decades of light changes in urban facilities undeveloped. To fill this gap, we developed an innovative framework and used it to design a new super-resolution model that reconstructs low-resolution nighttime light data into high resolution. The validation of one billion data points shows that the correlation coefficient of our model at the global scale reaches 0.873, which is significantly higher than that of other existing models (maximum = 0.713). Our model also outperforms existing models at the national and urban scales. Furthermore, through an inspection of airports and roads, only our model's image details can reveal the historical development of these facilities. We provide the long-term and fine-grained nighttime light observations to promote research on human activities. The dataset is available at \url{https://doi.org/10.5281/zenodo.7859205}.
Beyond the Granularity: Multi-Perspective Dialogue Collaborative Selection for Dialogue State Tracking
May 20, 2022
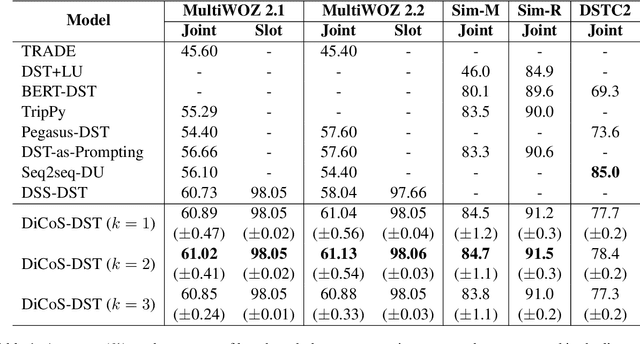
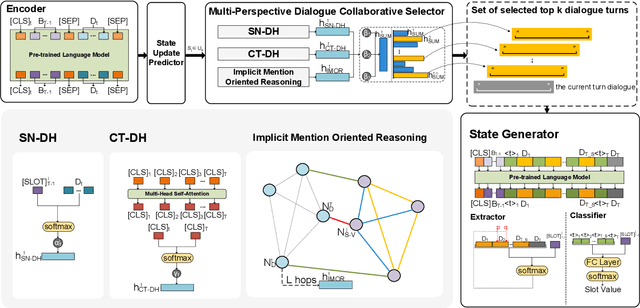
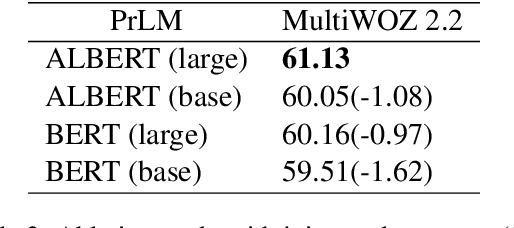
In dialogue state tracking, dialogue history is a crucial material, and its utilization varies between different models. However, no matter how the dialogue history is used, each existing model uses its own consistent dialogue history during the entire state tracking process, regardless of which slot is updated. Apparently, it requires different dialogue history to update different slots in different turns. Therefore, using consistent dialogue contents may lead to insufficient or redundant information for different slots, which affects the overall performance. To address this problem, we devise DiCoS-DST to dynamically select the relevant dialogue contents corresponding to each slot for state updating. Specifically, it first retrieves turn-level utterances of dialogue history and evaluates their relevance to the slot from a combination of three perspectives: (1) its explicit connection to the slot name; (2) its relevance to the current turn dialogue; (3) Implicit Mention Oriented Reasoning. Then these perspectives are combined to yield a decision, and only the selected dialogue contents are fed into State Generator, which explicitly minimizes the distracting information passed to the downstream state prediction. Experimental results show that our approach achieves new state-of-the-art performance on MultiWOZ 2.1 and MultiWOZ 2.2, and achieves superior performance on multiple mainstream benchmark datasets (including Sim-M, Sim-R, and DSTC2).
Dual Slot Selector via Local Reliability Verification for Dialogue State Tracking
Jul 27, 2021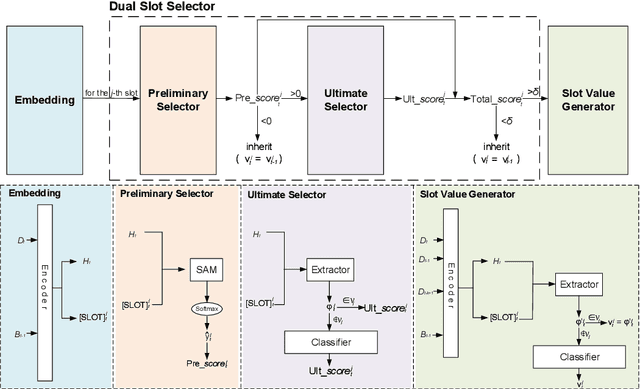


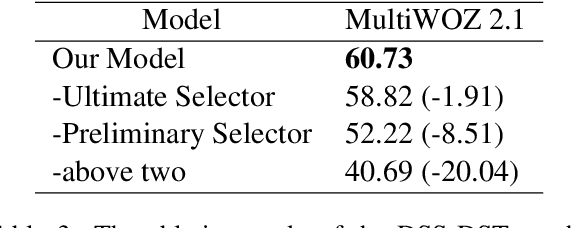
The goal of dialogue state tracking (DST) is to predict the current dialogue state given all previous dialogue contexts. Existing approaches generally predict the dialogue state at every turn from scratch. However, the overwhelming majority of the slots in each turn should simply inherit the slot values from the previous turn. Therefore, the mechanism of treating slots equally in each turn not only is inefficient but also may lead to additional errors because of the redundant slot value generation. To address this problem, we devise the two-stage DSS-DST which consists of the Dual Slot Selector based on the current turn dialogue, and the Slot Value Generator based on the dialogue history. The Dual Slot Selector determines each slot whether to update slot value or to inherit the slot value from the previous turn from two aspects: (1) if there is a strong relationship between it and the current turn dialogue utterances; (2) if a slot value with high reliability can be obtained for it through the current turn dialogue. The slots selected to be updated are permitted to enter the Slot Value Generator to update values by a hybrid method, while the other slots directly inherit the values from the previous turn. Empirical results show that our method achieves 56.93%, 60.73%, and 58.04% joint accuracy on MultiWOZ 2.0, MultiWOZ 2.1, and MultiWOZ 2.2 datasets respectively and achieves a new state-of-the-art performance with significant improvements.