 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGLM-5: from Vibe Coding to Agentic Engineering
Feb 17, 2026We present GLM-5, a next-generation foundation model designed to transition the paradigm of vibe coding to agentic engineering. Building upon the agentic, reasoning, and coding (ARC) capabilities of its predecessor, GLM-5 adopts DSA to significantly reduce training and inference costs while maintaining long-context fidelity. To advance model alignment and autonomy, we implement a new asynchronous reinforcement learning infrastructure that drastically improves post-training efficiency by decoupling generation from training. Furthermore, we propose novel asynchronous agent RL algorithms that further improve RL quality, enabling the model to learn from complex, long-horizon interactions more effectively. Through these innovations, GLM-5 achieves state-of-the-art performance on major open benchmarks. Most critically, GLM-5 demonstrates unprecedented capability in real-world coding tasks, surpassing previous baselines in handling end-to-end software engineering challenges. Code, models, and more information are available at https://github.com/zai-org/GLM-5.
GLM-4.5: Agentic, Reasoning, and Coding (ARC) Foundation Models
Aug 08, 2025We present GLM-4.5, an open-source Mixture-of-Experts (MoE) large language model with 355B total parameters and 32B activated parameters, featuring a hybrid reasoning method that supports both thinking and direct response modes. Through multi-stage training on 23T tokens and comprehensive post-training with expert model iteration and reinforcement learning, GLM-4.5 achieves strong performance across agentic, reasoning, and coding (ARC) tasks, scoring 70.1% on TAU-Bench, 91.0% on AIME 24, and 64.2% on SWE-bench Verified. With much fewer parameters than several competitors, GLM-4.5 ranks 3rd overall among all evaluated models and 2nd on agentic benchmarks. We release both GLM-4.5 (355B parameters) and a compact version, GLM-4.5-Air (106B parameters), to advance research in reasoning and agentic AI systems. Code, models, and more information are available at https://github.com/zai-org/GLM-4.5.
CCI4.0: A Bilingual Pretraining Dataset for Enhancing Reasoning in Large Language Models
Jun 09, 2025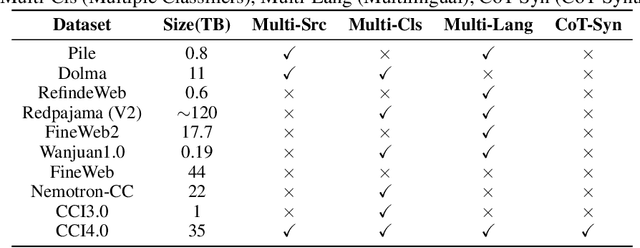
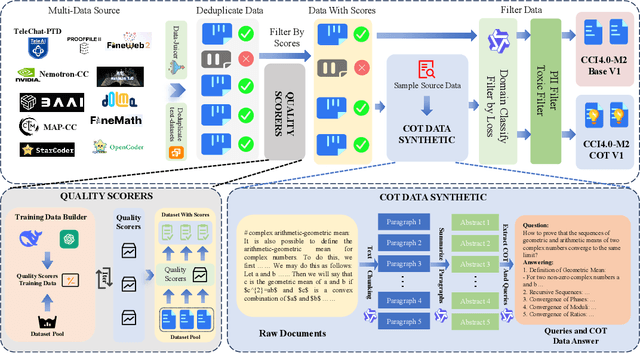
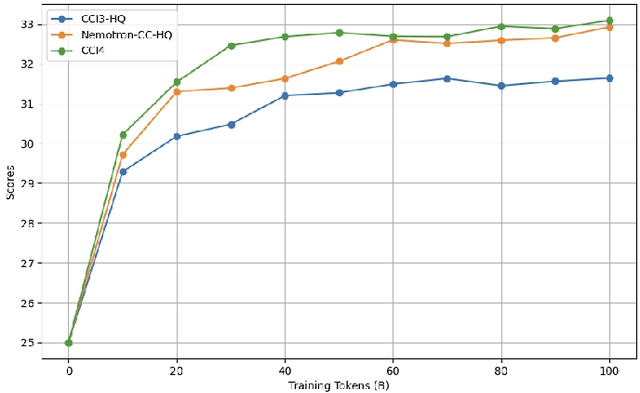
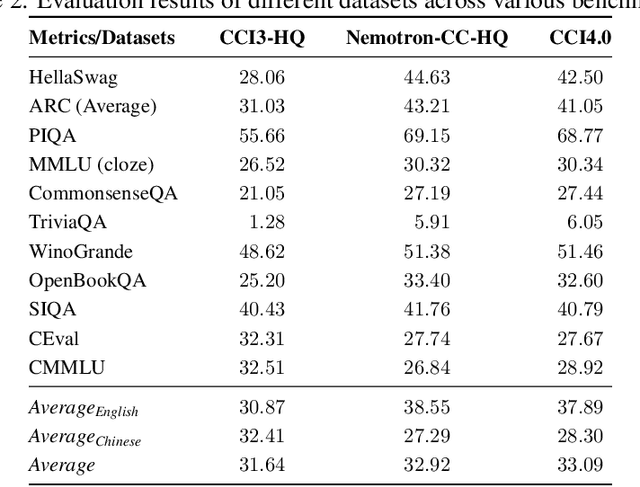
We introduce CCI4.0, a large-scale bilingual pre-training dataset engineered for superior data quality and diverse human-like reasoning trajectory. CCI4.0 occupies roughly $35$ TB of disk space and comprises two sub-datasets: CCI4.0-M2-Base and CCI4.0-M2-CoT. CCI4.0-M2-Base combines a $5.2$ TB carefully curated Chinese web corpus, a $22.5$ TB English subset from Nemotron-CC, and diverse sources from math, wiki, arxiv, and code. Although these data are mostly sourced from well-processed datasets, the quality standards of various domains are dynamic and require extensive expert experience and labor to process. So, we propose a novel pipeline justifying data quality mainly based on models through two-stage deduplication, multiclassifier quality scoring, and domain-aware fluency filtering. We extract $4.5$ billion pieces of CoT(Chain-of-Thought) templates, named CCI4.0-M2-CoT. Differing from the distillation of CoT from larger models, our proposed staged CoT extraction exemplifies diverse reasoning patterns and significantly decreases the possibility of hallucination. Empirical evaluations demonstrate that LLMs pre-trained in CCI4.0 benefit from cleaner, more reliable training signals, yielding consistent improvements in downstream tasks, especially in math and code reflection tasks. Our results underscore the critical role of rigorous data curation and human thinking templates in advancing LLM performance, shedding some light on automatically processing pretraining corpora.
Does Chain-of-Thought Reasoning Really Reduce Harmfulness from Jailbreaking?
May 23, 2025Jailbreak attacks have been observed to largely fail against recent reasoning models enhanced by Chain-of-Thought (CoT) reasoning. However, the underlying mechanism remains underexplored, and relying solely on reasoning capacity may raise security concerns. In this paper, we try to answer the question: Does CoT reasoning really reduce harmfulness from jailbreaking? Through rigorous theoretical analysis, we demonstrate that CoT reasoning has dual effects on jailbreaking harmfulness. Based on the theoretical insights, we propose a novel jailbreak method, FicDetail, whose practical performance validates our theoretical findings.
InCo-DPO: Balancing Distribution Shift and Data Quality for Enhanced Preference Optimization
Mar 20, 2025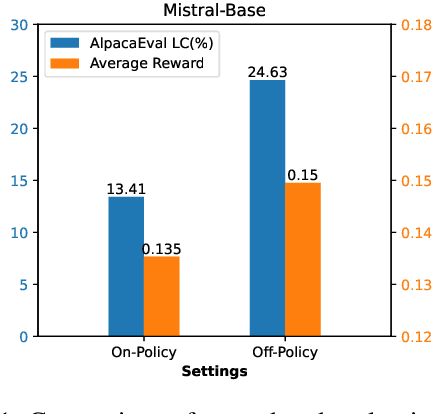
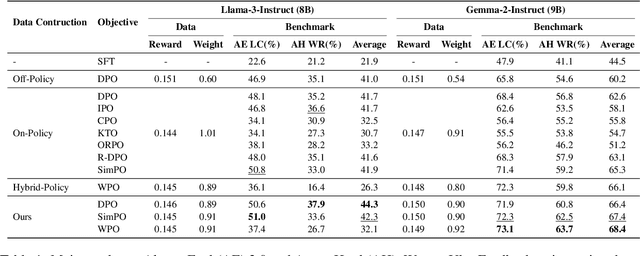
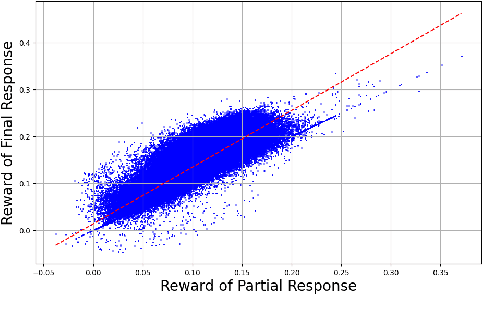
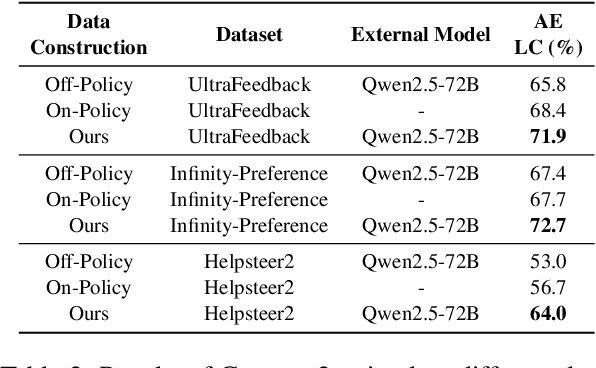
Direct Preference Optimization (DPO) optimizes language models to align with human preferences. Utilizing on-policy samples, generated directly by the policy model, typically results in better performance due to its distribution consistency with the model compared to off-policy samples. This paper identifies the quality of candidate preference samples as another critical factor. While the quality of on-policy data is inherently constrained by the capabilities of the policy model, off-policy data, which can be derived from diverse sources, offers greater potential for quality despite experiencing distribution shifts. However, current research mostly relies on on-policy data and neglects the value of off-policy data in terms of data quality, due to the challenge posed by distribution shift. In this paper, we propose InCo-DPO, an efficient method for synthesizing preference data by integrating on-policy and off-policy data, allowing dynamic adjustments to balance distribution shifts and data quality, thus finding an optimal trade-off. Consequently, InCo-DPO overcomes the limitations of distribution shifts in off-policy data and the quality constraints of on-policy data. We evaluated InCo-DPO with the Alpaca-Eval 2.0 and Arena-Hard benchmarks. Experimental results demonstrate that our approach not only outperforms both on-policy and off-policy data but also achieves a state-of-the-art win rate of 60.8 on Arena-Hard with the vanilla DPO using Gemma-2 model.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024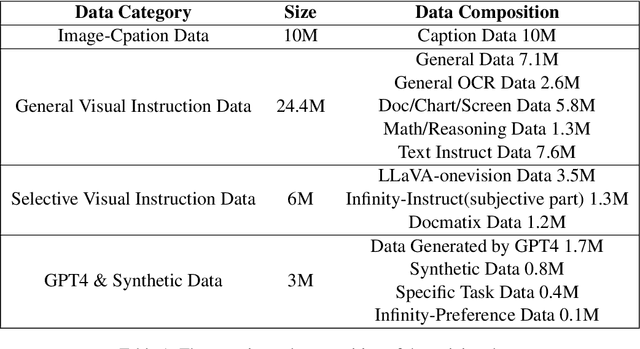
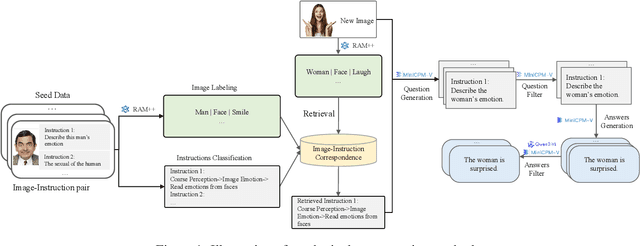
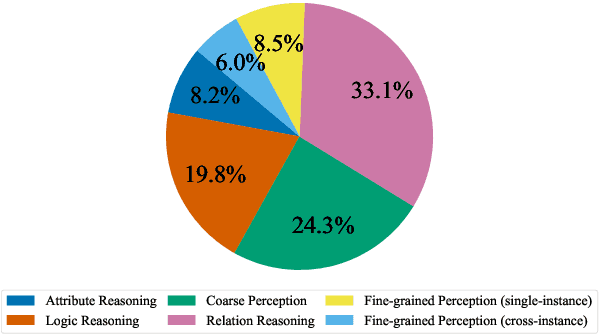
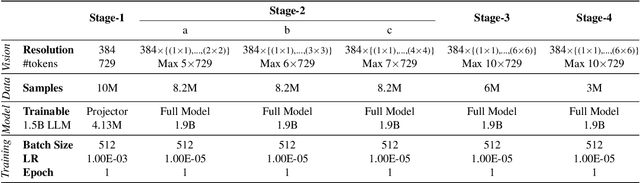
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
CCI3.0-HQ: a large-scale Chinese dataset of high quality designed for pre-training large language models
Oct 24, 2024We present CCI3.0-HQ (https://huggingface.co/datasets/BAAI/CCI3-HQ), a high-quality 500GB subset of the Chinese Corpora Internet 3.0 (CCI3.0)(https://huggingface.co/datasets/BAAI/CCI3-Data), developed using a novel two-stage hybrid filtering pipeline that significantly enhances data quality. To evaluate its effectiveness, we trained a 0.5B parameter model from scratch on 100B tokens across various datasets, achieving superior performance on 10 benchmarks in a zero-shot setting compared to CCI3.0, SkyPile, and WanjuanV1. The high-quality filtering process effectively distills the capabilities of the Qwen2-72B-instruct model into a compact 0.5B model, attaining optimal F1 scores for Chinese web data classification. We believe this open-access dataset will facilitate broader access to high-quality language models.
ReTok: Replacing Tokenizer to Enhance Representation Efficiency in Large Language Model
Oct 06, 2024Tokenizer is an essential component for large language models (LLMs), and a tokenizer with a high compression rate can improve the model's representation and processing efficiency. However, the tokenizer cannot ensure high compression rate in all scenarios, and an increase in the average input and output lengths will increases the training and inference costs of the model. Therefore, it is crucial to find ways to improve the model's efficiency with minimal cost while maintaining the model's performance. In this work, we propose a method to improve model representation and processing efficiency by replacing the tokenizers of LLMs. We propose replacing and reinitializing the parameters of the model's input and output layers with the parameters of the original model, and training these parameters while keeping other parameters fixed. We conducted experiments on different LLMs, and the results show that our method can maintain the performance of the model after replacing the tokenizer, while significantly improving the decoding speed for long texts.
Aquila2 Technical Report
Aug 14, 2024This paper introduces the Aquila2 series, which comprises a wide range of bilingual models with parameter sizes of 7, 34, and 70 billion. These models are trained based on an innovative framework named HeuriMentor (HM), which offers real-time insights into model convergence and enhances the training process and data management. The HM System, comprising the Adaptive Training Engine (ATE), Training State Monitor (TSM), and Data Management Unit (DMU), allows for precise monitoring of the model's training progress and enables efficient optimization of data distribution, thereby enhancing training effectiveness. Extensive evaluations show that the Aquila2 model series performs comparably well on both English and Chinese benchmarks. Specifically, Aquila2-34B demonstrates only a slight decrease in performance when quantized to Int4. Furthermore, we have made our training code (https://github.com/FlagOpen/FlagScale) and model weights (https://github.com/FlagAI-Open/Aquila2) publicly available to support ongoing research and the development of applications.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.