 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeInCo-DPO: Balancing Distribution Shift and Data Quality for Enhanced Preference Optimization
Mar 20, 2025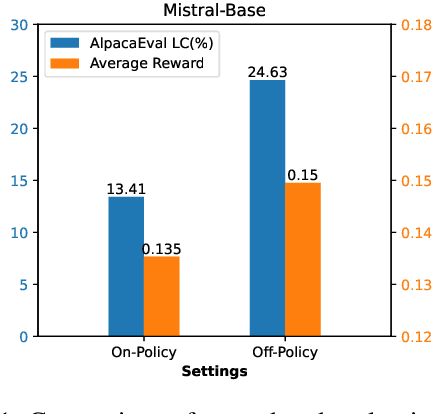
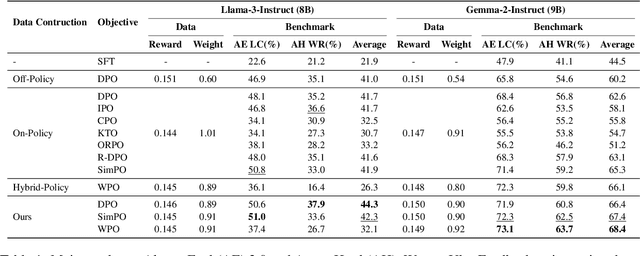
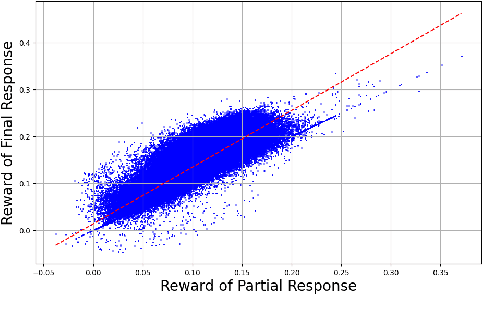
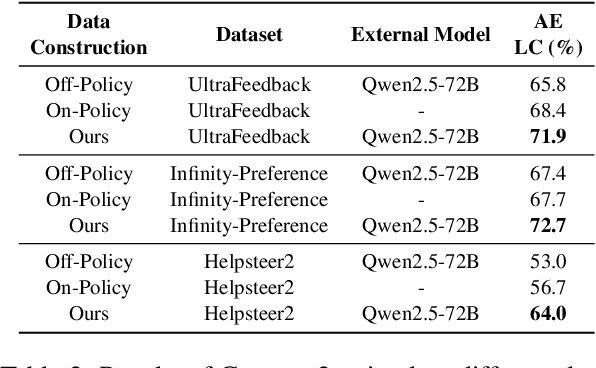
Direct Preference Optimization (DPO) optimizes language models to align with human preferences. Utilizing on-policy samples, generated directly by the policy model, typically results in better performance due to its distribution consistency with the model compared to off-policy samples. This paper identifies the quality of candidate preference samples as another critical factor. While the quality of on-policy data is inherently constrained by the capabilities of the policy model, off-policy data, which can be derived from diverse sources, offers greater potential for quality despite experiencing distribution shifts. However, current research mostly relies on on-policy data and neglects the value of off-policy data in terms of data quality, due to the challenge posed by distribution shift. In this paper, we propose InCo-DPO, an efficient method for synthesizing preference data by integrating on-policy and off-policy data, allowing dynamic adjustments to balance distribution shifts and data quality, thus finding an optimal trade-off. Consequently, InCo-DPO overcomes the limitations of distribution shifts in off-policy data and the quality constraints of on-policy data. We evaluated InCo-DPO with the Alpaca-Eval 2.0 and Arena-Hard benchmarks. Experimental results demonstrate that our approach not only outperforms both on-policy and off-policy data but also achieves a state-of-the-art win rate of 60.8 on Arena-Hard with the vanilla DPO using Gemma-2 model.
LabelCoRank: Revolutionizing Long Tail Multi-Label Classification with Co-Occurrence Reranking
Mar 11, 2025Motivation: Despite recent advancements in semantic representation driven by pre-trained and large-scale language models, addressing long tail challenges in multi-label text classification remains a significant issue. Long tail challenges have persistently posed difficulties in accurately classifying less frequent labels. Current approaches often focus on improving text semantics while neglecting the crucial role of label relationships. Results: This paper introduces LabelCoRank, a novel approach inspired by ranking principles. LabelCoRank leverages label co-occurrence relationships to refine initial label classifications through a dual-stage reranking process. The first stage uses initial classification results to form a preliminary ranking. In the second stage, a label co-occurrence matrix is utilized to rerank the preliminary results, enhancing the accuracy and relevance of the final classifications. By integrating the reranked label representations as additional text features, LabelCoRank effectively mitigates long tail issues in multi-labeltext classification. Experimental evaluations on popular datasets including MAG-CS, PubMed, and AAPD demonstrate the effectiveness and robustness of LabelCoRank.
ChinaTravel: A Real-World Benchmark for Language Agents in Chinese Travel Planning
Dec 18, 2024



Recent advances in LLMs, particularly in language reasoning and tool integration, have rapidly sparked the real-world development of Language Agents. Among these, travel planning represents a prominent domain, combining academic challenges with practical value due to its complexity and market demand. However, existing benchmarks fail to reflect the diverse, real-world requirements crucial for deployment. To address this gap, we introduce ChinaTravel, a benchmark specifically designed for authentic Chinese travel planning scenarios. We collect the travel requirements from questionnaires and propose a compositionally generalizable domain-specific language that enables a scalable evaluation process, covering feasibility, constraint satisfaction, and preference comparison. Empirical studies reveal the potential of neuro-symbolic agents in travel planning, achieving a constraint satisfaction rate of 27.9%, significantly surpassing purely neural models at 2.6%. Moreover, we identify key challenges in real-world travel planning deployments, including open language reasoning and unseen concept composition. These findings highlight the significance of ChinaTravel as a pivotal milestone for advancing language agents in complex, real-world planning scenarios.
Predictable Emergent Abilities of LLMs: Proxy Tasks Are All You Need
Dec 10, 2024



While scaling laws optimize training configurations for large language models (LLMs) through experiments on smaller or early-stage models, they fail to predict emergent abilities due to the absence of such capabilities in these models. To address this, we propose a method that predicts emergent abilities by leveraging proxy tasks. We begin by establishing relevance metrics between the target task and candidate tasks based on performance differences across multiple models. These candidate tasks are then validated for robustness with small model ensembles, leading to the selection of the most appropriate proxy tasks. The predicted performance on the target task is then derived by integrating the evaluation results of these proxies. In a case study on tool utilization capabilities, our method demonstrated a strong correlation between predicted and actual performance, confirming its effectiveness.
CCI3.0-HQ: a large-scale Chinese dataset of high quality designed for pre-training large language models
Oct 24, 2024We present CCI3.0-HQ (https://huggingface.co/datasets/BAAI/CCI3-HQ), a high-quality 500GB subset of the Chinese Corpora Internet 3.0 (CCI3.0)(https://huggingface.co/datasets/BAAI/CCI3-Data), developed using a novel two-stage hybrid filtering pipeline that significantly enhances data quality. To evaluate its effectiveness, we trained a 0.5B parameter model from scratch on 100B tokens across various datasets, achieving superior performance on 10 benchmarks in a zero-shot setting compared to CCI3.0, SkyPile, and WanjuanV1. The high-quality filtering process effectively distills the capabilities of the Qwen2-72B-instruct model into a compact 0.5B model, attaining optimal F1 scores for Chinese web data classification. We believe this open-access dataset will facilitate broader access to high-quality language models.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024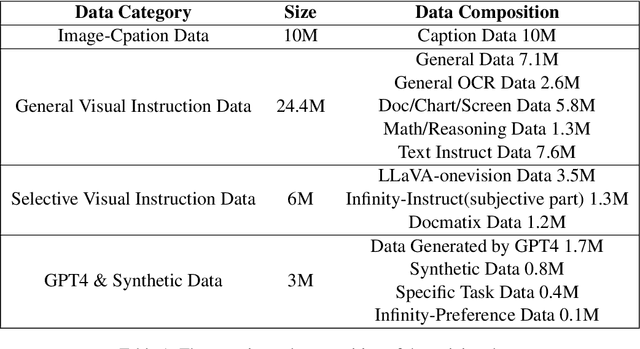
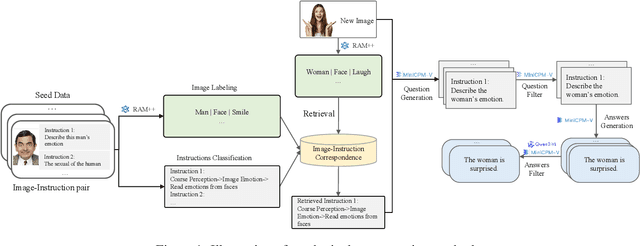
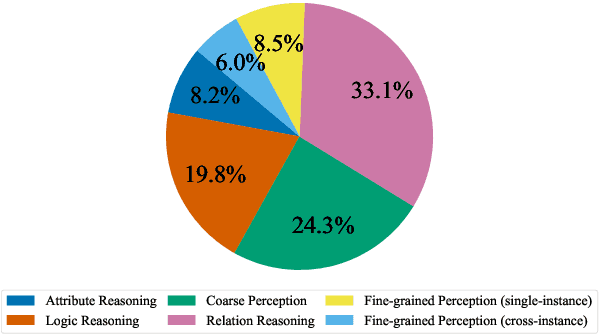
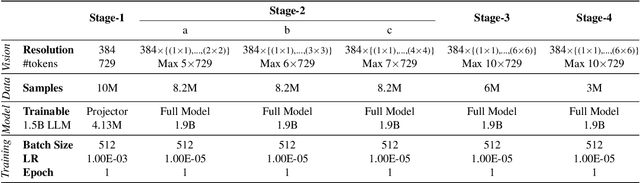
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
Aquila2 Technical Report
Aug 14, 2024This paper introduces the Aquila2 series, which comprises a wide range of bilingual models with parameter sizes of 7, 34, and 70 billion. These models are trained based on an innovative framework named HeuriMentor (HM), which offers real-time insights into model convergence and enhances the training process and data management. The HM System, comprising the Adaptive Training Engine (ATE), Training State Monitor (TSM), and Data Management Unit (DMU), allows for precise monitoring of the model's training progress and enables efficient optimization of data distribution, thereby enhancing training effectiveness. Extensive evaluations show that the Aquila2 model series performs comparably well on both English and Chinese benchmarks. Specifically, Aquila2-34B demonstrates only a slight decrease in performance when quantized to Int4. Furthermore, we have made our training code (https://github.com/FlagOpen/FlagScale) and model weights (https://github.com/FlagAI-Open/Aquila2) publicly available to support ongoing research and the development of applications.
AquilaMoE: Efficient Training for MoE Models with Scale-Up and Scale-Out Strategies
Aug 13, 2024In recent years, with the rapid application of large language models across various fields, the scale of these models has gradually increased, and the resources required for their pre-training have grown exponentially. Training an LLM from scratch will cost a lot of computation resources while scaling up from a smaller model is a more efficient approach and has thus attracted significant attention. In this paper, we present AquilaMoE, a cutting-edge bilingual 8*16B Mixture of Experts (MoE) language model that has 8 experts with 16 billion parameters each and is developed using an innovative training methodology called EfficientScale. This approach optimizes performance while minimizing data requirements through a two-stage process. The first stage, termed Scale-Up, initializes the larger model with weights from a pre-trained smaller model, enabling substantial knowledge transfer and continuous pretraining with significantly less data. The second stage, Scale-Out, uses a pre-trained dense model to initialize the MoE experts, further enhancing knowledge transfer and performance. Extensive validation experiments on 1.8B and 7B models compared various initialization schemes, achieving models that maintain and reduce loss during continuous pretraining. Utilizing the optimal scheme, we successfully trained a 16B model and subsequently the 8*16B AquilaMoE model, demonstrating significant improvements in performance and training efficiency.
InfinityMATH: A Scalable Instruction Tuning Dataset in Programmatic Mathematical Reasoning
Aug 09, 2024Recent advancements in Chain-of-Thoughts (CoT) and Program-of-Thoughts (PoT) methods have greatly enhanced language models' mathematical reasoning capabilities, facilitating their integration into instruction tuning datasets with LLMs. However, existing methods for large-scale dataset creation require substantial seed data and high computational costs for data synthesis, posing significant challenges for scalability. We introduce InfinityMATH, a scalable instruction tuning dataset for programmatic mathematical reasoning. The construction pipeline emphasizes decoupling numbers from mathematical problems to synthesize number-independent programs, enabling efficient and flexible scaling while minimizing dependency on specific numerical values. Fine-tuning experiments with open-source language and code models, such as Llama2 and CodeLlama, demonstrate the practical benefits of InfinityMATH. These fine-tuned models, showed significant relative improvements on both in-domain and out-of-domain benchmarks, ranging from 184.7% to 514.3% on average. Additionally, these models exhibited high robustness on the GSM8K+ and MATH+ benchmarks, which are enhanced version of test sets with simply the number variations. InfinityMATH ensures that models are more versatile and effective across a broader range of mathematical problems. The data is available at https://huggingface.co/datasets/flagopen/InfinityMATH.
TACO: Topics in Algorithmic COde generation dataset
Dec 27, 2023
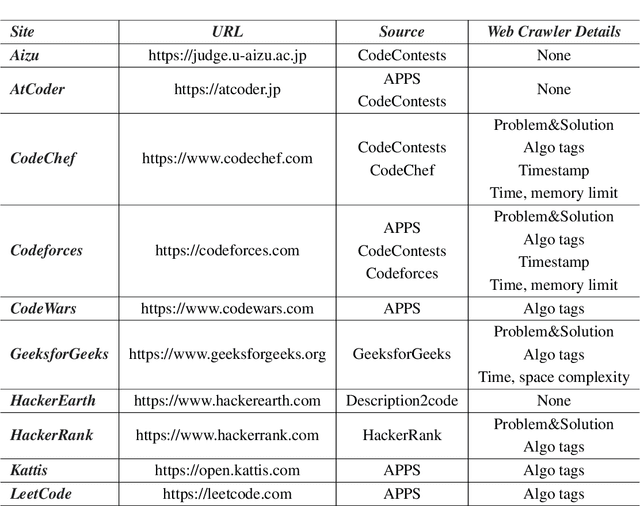

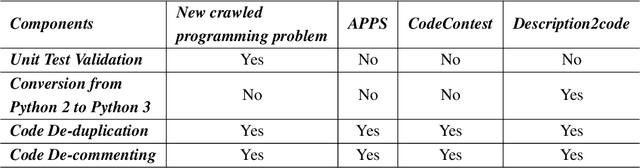
We introduce TACO, an open-source, large-scale code generation dataset, with a focus on the optics of algorithms, designed to provide a more challenging training dataset and evaluation benchmark in the field of code generation models. TACO includes competition-level programming questions that are more challenging, to enhance or evaluate problem understanding and reasoning abilities in real-world programming scenarios. There are 25433 and 1000 coding problems in training and test set, as well as up to 1.55 million diverse solution answers. Moreover, each TACO problem includes several fine-grained labels such as task topics, algorithms, programming skills, and difficulty levels, providing a more precise reference for the training and evaluation of code generation models. The dataset and evaluation scripts are available on Hugging Face Hub (https://huggingface.co/datasets/BAAI/TACO) and Github (https://github.com/FlagOpen/TACO).