 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTowards Automated Kernel Generation in the Era of LLMs
Jan 26, 2026The performance of modern AI systems is fundamentally constrained by the quality of their underlying kernels, which translate high-level algorithmic semantics into low-level hardware operations. Achieving near-optimal kernels requires expert-level understanding of hardware architectures and programming models, making kernel engineering a critical but notoriously time-consuming and non-scalable process. Recent advances in large language models (LLMs) and LLM-based agents have opened new possibilities for automating kernel generation and optimization. LLMs are well-suited to compress expert-level kernel knowledge that is difficult to formalize, while agentic systems further enable scalable optimization by casting kernel development as an iterative, feedback-driven loop. Rapid progress has been made in this area. However, the field remains fragmented, lacking a systematic perspective for LLM-driven kernel generation. This survey addresses this gap by providing a structured overview of existing approaches, spanning LLM-based approaches and agentic optimization workflows, and systematically compiling the datasets and benchmarks that underpin learning and evaluation in this domain. Moreover, key open challenges and future research directions are further outlined, aiming to establish a comprehensive reference for the next generation of automated kernel optimization. To keep track of this field, we maintain an open-source GitHub repository at https://github.com/flagos-ai/awesome-LLM-driven-kernel-generation.
Saying the Unsaid: Revealing the Hidden Language of Multimodal Systems Through Telephone Games
Nov 12, 2025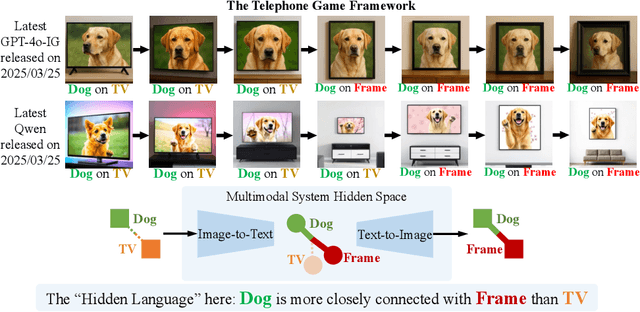
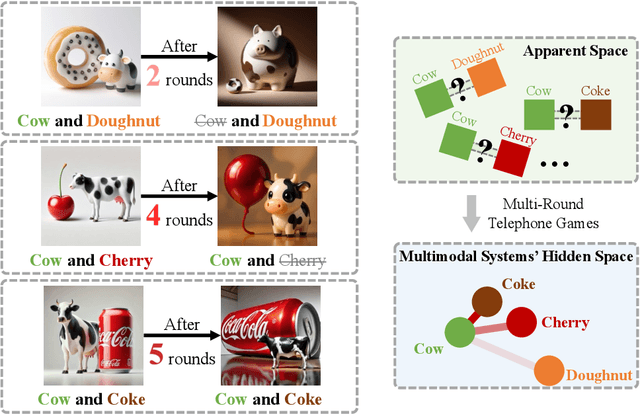
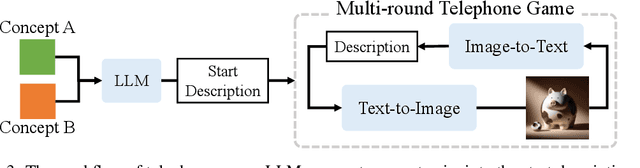

Recent closed-source multimodal systems have made great advances, but their hidden language for understanding the world remains opaque because of their black-box architectures. In this paper, we use the systems' preference bias to study their hidden language: During the process of compressing the input images (typically containing multiple concepts) into texts and then reconstructing them into images, the systems' inherent preference bias introduces specific shifts in the outputs, disrupting the original input concept co-occurrence. We employ the multi-round "telephone game" to strategically leverage this bias. By observing the co-occurrence frequencies of concepts in telephone games, we quantitatively investigate the concept connection strength in the understanding of multimodal systems, i.e., "hidden language." We also contribute Telescope, a dataset of 10,000+ concept pairs, as the database of our telephone game framework. Our telephone game is test-time scalable: By iteratively running telephone games, we can construct a global map of concept connections in multimodal systems' understanding. Here we can identify preference bias inherited from training, assess generalization capability advancement, and discover more stable pathways for fragile concept connections. Furthermore, we use Reasoning-LLMs to uncover unexpected concept relationships that transcend textual and visual similarities, inferring how multimodal systems understand and simulate the world. This study offers a new perspective on the hidden language of multimodal systems and lays the foundation for future research on the interpretability and controllability of multimodal systems.
Infinity-MM: Scaling Multimodal Performance with Large-Scale and High-Quality Instruction Data
Oct 24, 2024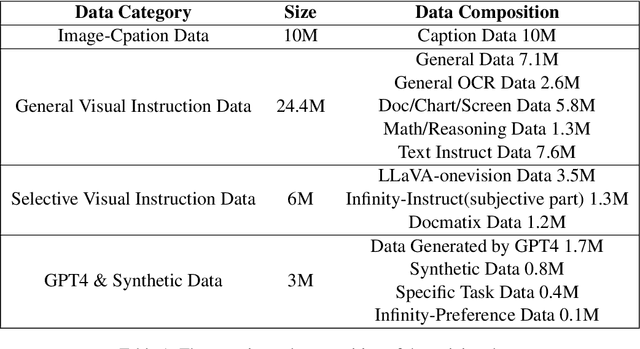
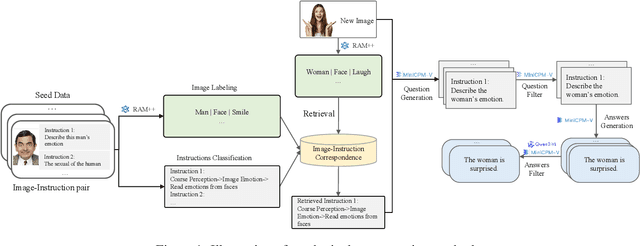
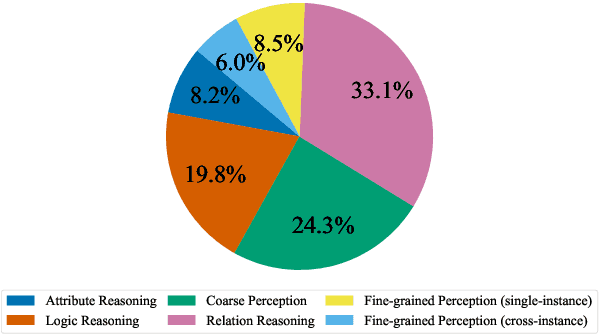
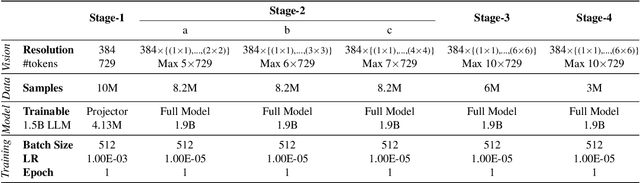
Vision-Language Models (VLMs) have recently made significant progress, but the limited scale and quality of open-source instruction data hinder their performance compared to closed-source models. In this work, we address this limitation by introducing Infinity-MM, a large-scale multimodal instruction dataset with 40 million samples, enhanced through rigorous quality filtering and deduplication. We also propose a synthetic instruction generation method based on open-source VLMs, using detailed image annotations and diverse question generation. Using this data, we trained a 2-billion-parameter VLM, Aquila-VL-2B, achieving state-of-the-art (SOTA) performance for models of similar scale. This demonstrates that expanding instruction data and generating synthetic data can significantly improve the performance of open-source models.
Back to the Source: Diffusion-Driven Test-Time Adaptation
Jul 07, 2022

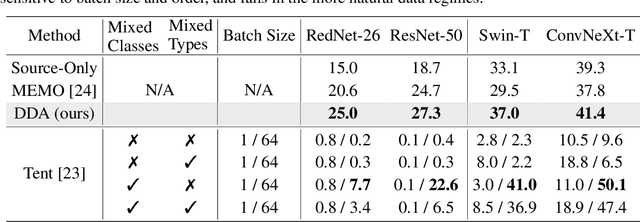

Test-time adaptation harnesses test inputs to improve the accuracy of a model trained on source data when tested on shifted target data. Existing methods update the source model by (re-)training on each target domain. While effective, re-training is sensitive to the amount and order of the data and the hyperparameters for optimization. We instead update the target data, by projecting all test inputs toward the source domain with a generative diffusion model. Our diffusion-driven adaptation method, DDA, shares its models for classification and generation across all domains. Both models are trained on the source domain, then fixed during testing. We augment diffusion with image guidance and self-ensembling to automatically decide how much to adapt. Input adaptation by DDA is more robust than prior model adaptation approaches across a variety of corruptions, architectures, and data regimes on the ImageNet-C benchmark. With its input-wise updates, DDA succeeds where model adaptation degrades on too little data in small batches, dependent data in non-uniform order, or mixed data with multiple corruptions.