 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Distillation of Hidden Layers for Self-Supervised Representation Learning
Mar 16, 2026The landscape of self-supervised learning (SSL) is currently dominated by generative approaches (e.g., MAE) that reconstruct raw low-level data, and predictive approaches (e.g., I-JEPA) that predict high-level abstract embeddings. While generative methods provide strong grounding, they are computationally inefficient for high-redundancy modalities like imagery, and their training objective does not prioritize learning high-level, conceptual features. Conversely, predictive methods often suffer from training instability due to their reliance on the non-stationary targets of final-layer self-distillation. We introduce Bootleg, a method that bridges this divide by tasking the model with predicting latent representations from multiple hidden layers of a teacher network. This hierarchical objective forces the model to capture features at varying levels of abstraction simultaneously. We demonstrate that Bootleg significantly outperforms comparable baselines (+10% over I-JEPA) on classification of ImageNet-1K and iNaturalist-21, and semantic segmentation of ADE20K and Cityscapes.
Self-Soupervision: Cooking Model Soups without Labels
Feb 02, 2026Model soups are strange and strangely effective combinations of parameters. They take a model (the stock), fine-tune it into multiple models (the ingredients), and then mix their parameters back into one model (the soup) to improve predictions. While all known soups require supervised learning, and optimize the same loss on labeled data, our recipes for Self-\emph{Soup}ervision generalize soups to self-supervised learning (SSL). Our Self-Souping lets us flavor ingredients on new data sources, e.g. from unlabeled data from a task for transfer or from a shift for robustness. We show that Self-Souping on corrupted test data, then fine-tuning back on uncorrupted train data, boosts robustness by +3.5\% (ImageNet-C) and +7\% (LAION-C). Self-\emph{Soup}ervision also unlocks countless SSL algorithms to cook the diverse ingredients needed for more robust soups. We show for the first time that ingredients can differ in their SSL hyperparameters -- and more surprisingly, in their SSL algorithms. We cook soups of MAE, MoCoV3, and MMCR ingredients that are more accurate than any one single SSL ingredient.
OlmoEarth: Stable Latent Image Modeling for Multimodal Earth Observation
Nov 17, 2025Earth observation data presents a unique challenge: it is spatial like images, sequential like video or text, and highly multimodal. We present OlmoEarth: a multimodal, spatio-temporal foundation model that employs a novel self-supervised learning formulation, masking strategy, and loss all designed for the Earth observation domain. OlmoEarth achieves state-of-the-art performance compared to 12 other foundation models across a variety of research benchmarks and real-world tasks from external partners. When evaluating embeddings OlmoEarth achieves the best performance on 15 out of 24 tasks, and with full fine-tuning it is the best on 19 of 29 tasks. We deploy OlmoEarth as the backbone of an end-to-end platform for data collection, labeling, training, and inference of Earth observation models. The OlmoEarth Platform puts frontier foundation models and powerful data management tools into the hands of non-profits and NGOs working to solve the world's biggest problems. OlmoEarth source code, training data, and pre-trained weights are available at $\href{https://github.com/allenai/olmoearth_pretrain}{\text{https://github.com/allenai/olmoearth_pretrain}}$.
AlphaEarth Foundations: An embedding field model for accurate and efficient global mapping from sparse label data
Jul 29, 2025Unprecedented volumes of Earth observation data are continually collected around the world, but high-quality labels remain scarce given the effort required to make physical measurements and observations. This has led to considerable investment in bespoke modeling efforts translating sparse labels into maps. Here we introduce AlphaEarth Foundations, an embedding field model yielding a highly general, geospatial representation that assimilates spatial, temporal, and measurement contexts across multiple sources, enabling accurate and efficient production of maps and monitoring systems from local to global scales. The embeddings generated by AlphaEarth Foundations are the only to consistently outperform all previous featurization approaches tested on a diverse set of mapping evaluations without re-training. We will release a dataset of global, annual, analysis-ready embedding field layers from 2017 through 2024.
Asymmetric Duos: Sidekicks Improve Uncertainty
May 24, 2025The go-to strategy to apply deep networks in settings where uncertainty informs decisions--ensembling multiple training runs with random initializations--is ill-suited for the extremely large-scale models and practical fine-tuning workflows of today. We introduce a new cost-effective strategy for improving the uncertainty quantification and downstream decisions of a large model (e.g. a fine-tuned ViT-B): coupling it with a less accurate but much smaller "sidekick" (e.g. a fine-tuned ResNet-34) with a fraction of the computational cost. We propose aggregating the predictions of this \emph{Asymmetric Duo} by simple learned weighted averaging. Surprisingly, despite their inherent asymmetry, the sidekick model almost never harms the performance of the larger model. In fact, across five image classification benchmarks and a variety of model architectures and training schemes (including soups), Asymmetric Duos significantly improve accuracy, uncertainty quantification, and selective classification metrics with only ${\sim}10-20\%$ more computation.
LookWhere? Efficient Visual Recognition by Learning Where to Look and What to See from Self-Supervision
May 23, 2025Vision transformers are ever larger, more accurate, and more expensive to compute. The expense is even more extreme at high resolution as the number of tokens grows quadratically with the image size. We turn to adaptive computation to cope with this cost by learning to predict where to compute. Our LookWhere method divides the computation between a low-resolution selector and a high-resolution extractor without ever processing the full high-resolution input. We jointly pretrain the selector and extractor without task supervision by distillation from a self-supervised teacher, in effect, learning where and what to compute simultaneously. Unlike prior token reduction methods, which pay to save by pruning already-computed tokens, and prior token selection methods, which require complex and expensive per-task optimization, LookWhere economically and accurately selects and extracts transferrable representations of images. We show that LookWhere excels at sparse recognition on high-resolution inputs (Traffic Signs), maintaining accuracy while reducing FLOPs by up to 34x and time by 6x. It also excels at standard recognition tasks that are global (ImageNet classification) or local (ADE20K segmentation), improving accuracy while reducing time by 1.36x.
ReservoirTTA: Prolonged Test-time Adaptation for Evolving and Recurring Domains
May 20, 2025This paper introduces ReservoirTTA, a novel plug-in framework designed for prolonged test-time adaptation (TTA) in scenarios where the test domain continuously shifts over time, including cases where domains recur or evolve gradually. At its core, ReservoirTTA maintains a reservoir of domain-specialized models -- an adaptive test-time model ensemble -- that both detects new domains via online clustering over style features of incoming samples and routes each sample to the appropriate specialized model, and thereby enables domain-specific adaptation. This multi-model strategy overcomes key limitations of single model adaptation, such as catastrophic forgetting, inter-domain interference, and error accumulation, ensuring robust and stable performance on sustained non-stationary test distributions. Our theoretical analysis reveals key components that bound parameter variance and prevent model collapse, while our plug-in TTA module mitigates catastrophic forgetting of previously encountered domains. Extensive experiments on the classification corruption benchmarks, including ImageNet-C and CIFAR-10/100-C, as well as the Cityscapes$\rightarrow$ACDC semantic segmentation task, covering recurring and continuously evolving domain shifts, demonstrate that ReservoirTTA significantly improves adaptation accuracy and maintains stable performance across prolonged, recurring shifts, outperforming state-of-the-art methods.
Simpler Fast Vision Transformers with a Jumbo CLS Token
Feb 20, 2025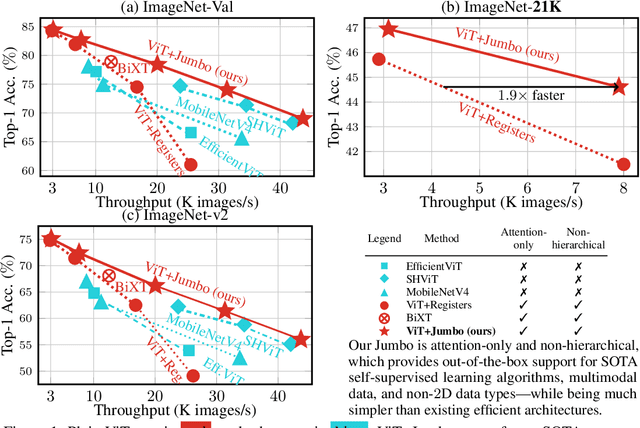
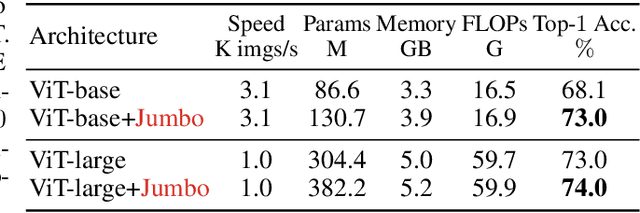
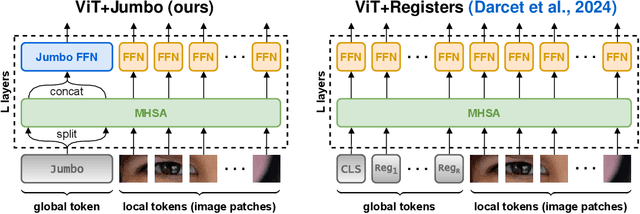

We introduce a simple enhancement to the global processing of vision transformers (ViTs) to improve accuracy while maintaining throughput. Our approach, Jumbo, creates a wider CLS token, which is split to match the patch token width before attention, processed with self-attention, and reassembled. After attention, Jumbo applies a dedicated, wider FFN to this token. Jumbo significantly improves over ViT+Registers on ImageNet-1K at high speeds (by 3.2% for ViT-tiny and 13.5% for ViT-nano); these Jumbo models even outperform specialized compute-efficient models while preserving the architectural advantages of plain ViTs. Although Jumbo sees no gains for ViT-small on ImageNet-1K, it gains 3.4% on ImageNet-21K over ViT+Registers. Both findings indicate that Jumbo is most helpful when the ViT is otherwise too narrow for the task. Finally, we show that Jumbo can be easily adapted to excel on data beyond images, e.g., time series.
Galileo: Learning Global and Local Features in Pretrained Remote Sensing Models
Feb 13, 2025From crop mapping to flood detection, machine learning in remote sensing has a wide range of societally beneficial applications. The commonalities between remote sensing data in these applications present an opportunity for pretrained machine learning models tailored to remote sensing to reduce the labeled data and effort required to solve individual tasks. However, such models must be: (i) flexible enough to ingest input data of varying sensor modalities and shapes (i.e., of varying spatial and temporal dimensions), and (ii) able to model Earth surface phenomena of varying scales and types. To solve this gap, we present Galileo, a family of pretrained remote sensing models designed to flexibly process multimodal remote sensing data. We also introduce a novel and highly effective self-supervised learning approach to learn both large- and small-scale features, a challenge not addressed by previous models. Our Galileo models obtain state-of-the-art results across diverse remote sensing tasks.
Adaptive Randomized Smoothing: Certifying Multi-Step Defences against Adversarial Examples
Jun 14, 2024



We propose Adaptive Randomized Smoothing (ARS) to certify the predictions of our test-time adaptive models against adversarial examples. ARS extends the analysis of randomized smoothing using f-Differential Privacy to certify the adaptive composition of multiple steps. For the first time, our theory covers the sound adaptive composition of general and high-dimensional functions of noisy input. We instantiate ARS on deep image classification to certify predictions against adversarial examples of bounded $L_{\infty}$ norm. In the $L_{\infty}$ threat model, our flexibility enables adaptation through high-dimensional input-dependent masking. We design adaptivity benchmarks, based on CIFAR-10 and CelebA, and show that ARS improves accuracy by $2$ to $5\%$ points. On ImageNet, ARS improves accuracy by $1$ to $3\%$ points over standard RS without adaptivity.