 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmoEarth v1.1: A more efficient family of OlmoEarth models
May 20, 2026We present a set of improvements to the OlmoEarth family. These improvements allow us to cut compute costs during training ($1.7 \times$ reduction in GPU hours required to train our Base models) and inference ($2.9\times$ reductions in MACs on Sentinel-2 tasks), while maintaining the models' overall performance. All training code is available at github.com/allenai/olmoearth_pretrain.
OlmoEarth: Stable Latent Image Modeling for Multimodal Earth Observation
Nov 17, 2025Earth observation data presents a unique challenge: it is spatial like images, sequential like video or text, and highly multimodal. We present OlmoEarth: a multimodal, spatio-temporal foundation model that employs a novel self-supervised learning formulation, masking strategy, and loss all designed for the Earth observation domain. OlmoEarth achieves state-of-the-art performance compared to 12 other foundation models across a variety of research benchmarks and real-world tasks from external partners. When evaluating embeddings OlmoEarth achieves the best performance on 15 out of 24 tasks, and with full fine-tuning it is the best on 19 of 29 tasks. We deploy OlmoEarth as the backbone of an end-to-end platform for data collection, labeling, training, and inference of Earth observation models. The OlmoEarth Platform puts frontier foundation models and powerful data management tools into the hands of non-profits and NGOs working to solve the world's biggest problems. OlmoEarth source code, training data, and pre-trained weights are available at $\href{https://github.com/allenai/olmoearth_pretrain}{\text{https://github.com/allenai/olmoearth_pretrain}}$.
LIGHTHOUSE: Fast and precise distance to shoreline calculations from anywhere on earth
Jun 23, 2025We introduce a new dataset and algorithm for fast and efficient coastal distance calculations from Anywhere on Earth (AoE). Existing global coastal datasets are only available at coarse resolution (e.g. 1-4 km) which limits their utility. Publicly available satellite imagery combined with computer vision enable much higher precision. We provide a global coastline dataset at 10 meter resolution, a 100+ fold improvement in precision over existing data. To handle the computational challenge of querying at such an increased scale, we introduce a new library: Layered Iterative Geospatial Hierarchical Terrain-Oriented Unified Search Engine (Lighthouse). Lighthouse is both exceptionally fast and resource-efficient, requiring only 1 CPU and 2 GB of RAM to achieve millisecond online inference, making it well suited for real-time applications in resource-constrained environments.
Galileo: Learning Global and Local Features in Pretrained Remote Sensing Models
Feb 13, 2025From crop mapping to flood detection, machine learning in remote sensing has a wide range of societally beneficial applications. The commonalities between remote sensing data in these applications present an opportunity for pretrained machine learning models tailored to remote sensing to reduce the labeled data and effort required to solve individual tasks. However, such models must be: (i) flexible enough to ingest input data of varying sensor modalities and shapes (i.e., of varying spatial and temporal dimensions), and (ii) able to model Earth surface phenomena of varying scales and types. To solve this gap, we present Galileo, a family of pretrained remote sensing models designed to flexibly process multimodal remote sensing data. We also introduce a novel and highly effective self-supervised learning approach to learn both large- and small-scale features, a challenge not addressed by previous models. Our Galileo models obtain state-of-the-art results across diverse remote sensing tasks.
Molmo and PixMo: Open Weights and Open Data for State-of-the-Art Multimodal Models
Sep 25, 2024



Today's most advanced multimodal models remain proprietary. The strongest open-weight models rely heavily on synthetic data from proprietary VLMs to achieve good performance, effectively distilling these closed models into open ones. As a result, the community is still missing foundational knowledge about how to build performant VLMs from scratch. We present Molmo, a new family of VLMs that are state-of-the-art in their class of openness. Our key innovation is a novel, highly detailed image caption dataset collected entirely from human annotators using speech-based descriptions. To enable a wide array of user interactions, we also introduce a diverse dataset mixture for fine-tuning that includes in-the-wild Q&A and innovative 2D pointing data. The success of our approach relies on careful choices for the model architecture details, a well-tuned training pipeline, and, most critically, the quality of our newly collected datasets, all of which will be released. The best-in-class 72B model within the Molmo family not only outperforms others in the class of open weight and data models but also compares favorably against proprietary systems like GPT-4o, Claude 3.5, and Gemini 1.5 on both academic benchmarks and human evaluation. We will be releasing all of our model weights, captioning and fine-tuning data, and source code in the near future. Select model weights, inference code, and demo are available at https://molmo.allenai.org.
On the Generalizability of Foundation Models for Crop Type Mapping
Sep 14, 2024Foundation models pre-trained using self-supervised and weakly-supervised learning have shown powerful transfer learning capabilities on various downstream tasks, including language understanding, text generation, and image recognition. Recently, the Earth observation (EO) field has produced several foundation models pre-trained directly on multispectral satellite imagery (e.g., Sentinel-2) for applications like precision agriculture, wildfire and drought monitoring, and natural disaster response. However, few studies have investigated the ability of these models to generalize to new geographic locations, and potential concerns of geospatial bias -- models trained on data-rich developed countries not transferring well to data-scarce developing countries -- remain. We investigate the ability of popular EO foundation models to transfer to new geographic regions in the agricultural domain, where differences in farming practices and class imbalance make transfer learning particularly challenging. We first select six crop classification datasets across five continents, normalizing for dataset size and harmonizing classes to focus on four major cereal grains: maize, soybean, rice, and wheat. We then compare three popular foundation models, pre-trained on SSL4EO-S12, SatlasPretrain, and ImageNet, using in-distribution (ID) and out-of-distribution (OOD) evaluation. Experiments show that pre-trained weights designed explicitly for Sentinel-2, such as SSL4EO-S12, outperform general pre-trained weights like ImageNet. Furthermore, the benefits of pre-training on OOD data are the most significant when only 10--100 ID training samples are used. Transfer learning and pre-training with OOD and limited ID data show promising applications, as many developing regions have scarce crop type labels. All harmonized datasets and experimental code are open-source and available for download.
Satellite Imagery and AI: A New Era in Ocean Conservation, from Research to Deployment and Impact
Dec 06, 2023Illegal, unreported, and unregulated (IUU) fishing poses a global threat to ocean habitats. Publicly available satellite data offered by NASA and the European Space Agency (ESA) provide an opportunity to actively monitor this activity. Effectively leveraging satellite data for maritime conservation requires highly reliable machine learning models operating globally with minimal latency. This paper introduces three specialized computer vision models designed for synthetic aperture radar (Sentinel-1), optical imagery (Sentinel-2), and nighttime lights (Suomi-NPP/NOAA-20). It also presents best practices for developing and delivering real-time computer vision services for conservation. These models have been deployed in Skylight, a real time maritime monitoring platform, which is provided at no cost to users worldwide.
Zooming Out on Zooming In: Advancing Super-Resolution for Remote Sensing
Nov 29, 2023



Super-Resolution for remote sensing has the potential for huge impact on planet monitoring by producing accurate and realistic high resolution imagery on a frequent basis and a global scale. Despite a lot of attention, several inconsistencies and challenges have prevented it from being deployed in practice. These include the lack of effective metrics, fragmented and relatively small-scale datasets for training, insufficient comparisons across a suite of methods, and unclear evidence for the use of super-resolution outputs for machine consumption. This work presents a new metric for super-resolution, CLIPScore, that corresponds far better with human judgments than previous metrics on an extensive study. We use CLIPScore to evaluate four standard methods on a new large-scale dataset, S2-NAIP, and three existing benchmark datasets, and find that generative adversarial networks easily outperform more traditional L2 loss-based models and are more semantically accurate than modern diffusion models. We also find that using CLIPScore as an auxiliary loss can speed up the training of GANs by 18x and lead to improved outputs, resulting in an effective model in diverse geographies across the world which we will release publicly. The dataset, pre-trained model weights, and code are available at https://github.com/allenai/satlas-super-resolution/.
Satlas: A Large-Scale, Multi-Task Dataset for Remote Sensing Image Understanding
Nov 28, 2022



Remote sensing images are useful for a wide variety of environmental and earth monitoring tasks, including tracking deforestation, illegal fishing, urban expansion, and natural disasters. The earth is extremely diverse -- the amount of potential tasks in remote sensing images is massive, and the sizes of features range from several kilometers to just tens of centimeters. However, creating generalizable computer vision methods is a challenge in part due to the lack of a large-scale dataset that captures these diverse features for many tasks. In this paper, we present Satlas, a remote sensing dataset and benchmark that is large in both breadth, featuring all of the aforementioned applications and more, as well as scale, comprising 290M labels under 137 categories and seven label modalities. We evaluate eight baselines and a proposed method on Satlas, and find that there is substantial room for improvement in addressing research challenges specific to remote sensing, including processing image time series that consist of images from very different types of sensors, and taking advantage of long-range spatial context. We also find that pre-training on Satlas substantially improves performance on downstream tasks with few labeled examples, increasing average accuracy by 16% over ImageNet and 5% over the next best baseline.
Self-Supervised Multi-Object Tracking with Cross-Input Consistency
Nov 10, 2021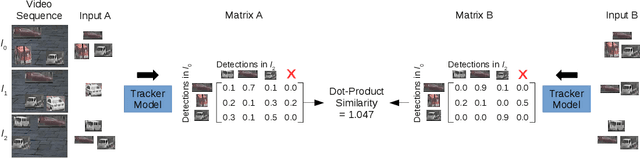
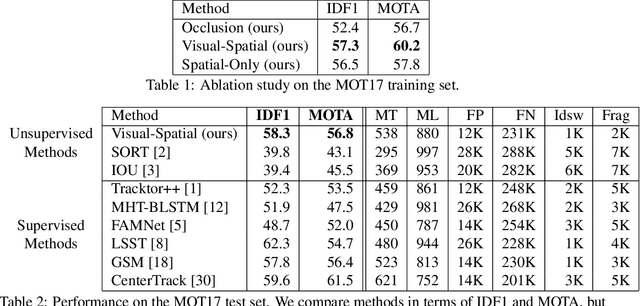
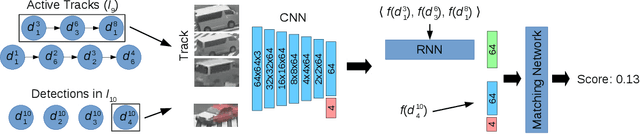
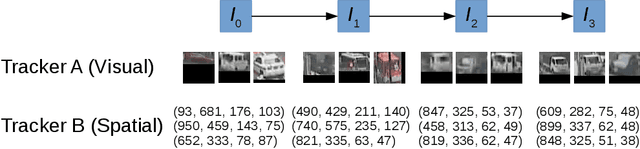
In this paper, we propose a self-supervised learning procedure for training a robust multi-object tracking (MOT) model given only unlabeled video. While several self-supervisory learning signals have been proposed in prior work on single-object tracking, such as color propagation and cycle-consistency, these signals cannot be directly applied for training RNN models, which are needed to achieve accurate MOT: they yield degenerate models that, for instance, always match new detections to tracks with the closest initial detections. We propose a novel self-supervisory signal that we call cross-input consistency: we construct two distinct inputs for the same sequence of video, by hiding different information about the sequence in each input. We then compute tracks in that sequence by applying an RNN model independently on each input, and train the model to produce consistent tracks across the two inputs. We evaluate our unsupervised method on MOT17 and KITTI -- remarkably, we find that, despite training only on unlabeled video, our unsupervised approach outperforms four supervised methods published in the last 1--2 years, including Tracktor++, FAMNet, GSM, and mmMOT.