 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSelf-Soupervision: Cooking Model Soups without Labels
Feb 02, 2026Model soups are strange and strangely effective combinations of parameters. They take a model (the stock), fine-tune it into multiple models (the ingredients), and then mix their parameters back into one model (the soup) to improve predictions. While all known soups require supervised learning, and optimize the same loss on labeled data, our recipes for Self-\emph{Soup}ervision generalize soups to self-supervised learning (SSL). Our Self-Souping lets us flavor ingredients on new data sources, e.g. from unlabeled data from a task for transfer or from a shift for robustness. We show that Self-Souping on corrupted test data, then fine-tuning back on uncorrupted train data, boosts robustness by +3.5\% (ImageNet-C) and +7\% (LAION-C). Self-\emph{Soup}ervision also unlocks countless SSL algorithms to cook the diverse ingredients needed for more robust soups. We show for the first time that ingredients can differ in their SSL hyperparameters -- and more surprisingly, in their SSL algorithms. We cook soups of MAE, MoCoV3, and MMCR ingredients that are more accurate than any one single SSL ingredient.
LookWhere? Efficient Visual Recognition by Learning Where to Look and What to See from Self-Supervision
May 23, 2025Vision transformers are ever larger, more accurate, and more expensive to compute. The expense is even more extreme at high resolution as the number of tokens grows quadratically with the image size. We turn to adaptive computation to cope with this cost by learning to predict where to compute. Our LookWhere method divides the computation between a low-resolution selector and a high-resolution extractor without ever processing the full high-resolution input. We jointly pretrain the selector and extractor without task supervision by distillation from a self-supervised teacher, in effect, learning where and what to compute simultaneously. Unlike prior token reduction methods, which pay to save by pruning already-computed tokens, and prior token selection methods, which require complex and expensive per-task optimization, LookWhere economically and accurately selects and extracts transferrable representations of images. We show that LookWhere excels at sparse recognition on high-resolution inputs (Traffic Signs), maintaining accuracy while reducing FLOPs by up to 34x and time by 6x. It also excels at standard recognition tasks that are global (ImageNet classification) or local (ADE20K segmentation), improving accuracy while reducing time by 1.36x.
Simpler Fast Vision Transformers with a Jumbo CLS Token
Feb 20, 2025We introduce a simple enhancement to the global processing of vision transformers (ViTs) to improve accuracy while maintaining throughput. Our approach, Jumbo, creates a wider CLS token, which is split to match the patch token width before attention, processed with self-attention, and reassembled. After attention, Jumbo applies a dedicated, wider FFN to this token. Jumbo significantly improves over ViT+Registers on ImageNet-1K at high speeds (by 3.2% for ViT-tiny and 13.5% for ViT-nano); these Jumbo models even outperform specialized compute-efficient models while preserving the architectural advantages of plain ViTs. Although Jumbo sees no gains for ViT-small on ImageNet-1K, it gains 3.4% on ImageNet-21K over ViT+Registers. Both findings indicate that Jumbo is most helpful when the ViT is otherwise too narrow for the task. Finally, we show that Jumbo can be easily adapted to excel on data beyond images, e.g., time series.
Galileo: Learning Global and Local Features in Pretrained Remote Sensing Models
Feb 13, 2025From crop mapping to flood detection, machine learning in remote sensing has a wide range of societally beneficial applications. The commonalities between remote sensing data in these applications present an opportunity for pretrained machine learning models tailored to remote sensing to reduce the labeled data and effort required to solve individual tasks. However, such models must be: (i) flexible enough to ingest input data of varying sensor modalities and shapes (i.e., of varying spatial and temporal dimensions), and (ii) able to model Earth surface phenomena of varying scales and types. To solve this gap, we present Galileo, a family of pretrained remote sensing models designed to flexibly process multimodal remote sensing data. We also introduce a novel and highly effective self-supervised learning approach to learn both large- and small-scale features, a challenge not addressed by previous models. Our Galileo models obtain state-of-the-art results across diverse remote sensing tasks.
LookHere: Vision Transformers with Directed Attention Generalize and Extrapolate
May 22, 2024High-resolution images offer more information about scenes that can improve model accuracy. However, the dominant model architecture in computer vision, the vision transformer (ViT), cannot effectively leverage larger images without finetuning -- ViTs poorly extrapolate to more patches at test time, although transformers offer sequence length flexibility. We attribute this shortcoming to the current patch position encoding methods, which create a distribution shift when extrapolating. We propose a drop-in replacement for the position encoding of plain ViTs that restricts attention heads to fixed fields of view, pointed in different directions, using 2D attention masks. Our novel method, called LookHere, provides translation-equivariance, ensures attention head diversity, and limits the distribution shift that attention heads face when extrapolating. We demonstrate that LookHere improves performance on classification (avg. 1.6%), against adversarial attack (avg. 5.4%), and decreases calibration error (avg. 1.5%) -- on ImageNet without extrapolation. With extrapolation, LookHere outperforms the current SoTA position encoding method, 2D-RoPE, by 21.7% on ImageNet when trained at $224^2$ px and tested at $1024^2$ px. Additionally, we release a high-resolution test set to improve the evaluation of high-resolution image classifiers, called ImageNet-HR.
CROMA: Remote Sensing Representations with Contrastive Radar-Optical Masked Autoencoders
Nov 01, 2023A vital and rapidly growing application, remote sensing offers vast yet sparsely labeled, spatially aligned multimodal data; this makes self-supervised learning algorithms invaluable. We present CROMA: a framework that combines contrastive and reconstruction self-supervised objectives to learn rich unimodal and multimodal representations. Our method separately encodes masked-out multispectral optical and synthetic aperture radar samples -- aligned in space and time -- and performs cross-modal contrastive learning. Another encoder fuses these sensors, producing joint multimodal encodings that are used to predict the masked patches via a lightweight decoder. We show that these objectives are complementary when leveraged on spatially aligned multimodal data. We also introduce X- and 2D-ALiBi, which spatially biases our cross- and self-attention matrices. These strategies improve representations and allow our models to effectively extrapolate to images up to 17.6x larger at test-time. CROMA outperforms the current SoTA multispectral model, evaluated on: four classification benchmarks -- finetuning (avg. 1.8%), linear (avg. 2.4%) and nonlinear (avg. 1.4%) probing, kNN classification (avg. 3.5%), and K-means clustering (avg. 8.4%); and three segmentation benchmarks (avg. 6.4%). CROMA's rich, optionally multimodal representations can be widely leveraged across remote sensing applications.
Under the Cover Infant Pose Estimation using Multimodal Data
Oct 03, 2022



Infant pose monitoring during sleep has multiple applications in both healthcare and home settings. In a healthcare setting, pose detection can be used for region of interest detection and movement detection for noncontact based monitoring systems. In a home setting, pose detection can be used to detect sleep positions which has shown to have a strong influence on multiple health factors. However, pose monitoring during sleep is challenging due to heavy occlusions from blanket coverings and low lighting. To address this, we present a novel dataset, Simultaneously-collected multimodal Mannequin Lying pose (SMaL) dataset, for under the cover infant pose estimation. We collect depth and pressure imagery of an infant mannequin in different poses under various cover conditions. We successfully infer full body pose under the cover by training state-of-art pose estimation methods and leveraging existing multimodal adult pose datasets for transfer learning. We demonstrate a hierarchical pretraining strategy for transformer-based models to significantly improve performance on our dataset. Our best performing model was able to detect joints under the cover within 25mm 86% of the time with an overall mean error of 16.9mm. Data, code and models publicly available at https://github.com/DanielKyr/SMaL
Transfer Learning with Pretrained Remote Sensing Transformers
Sep 28, 2022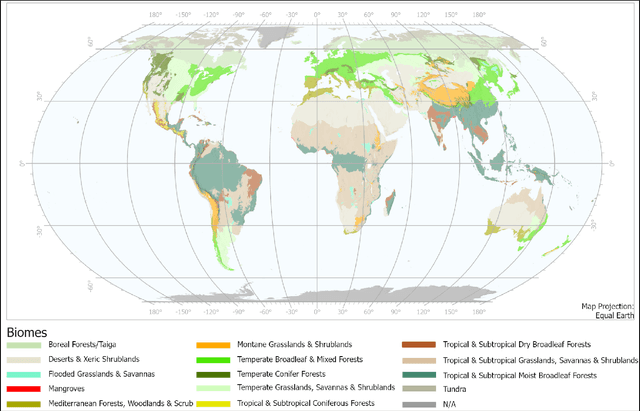
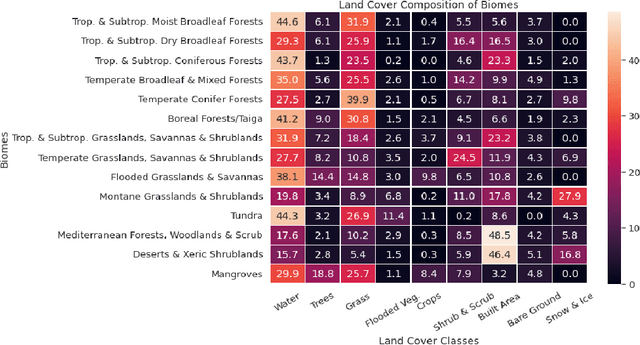
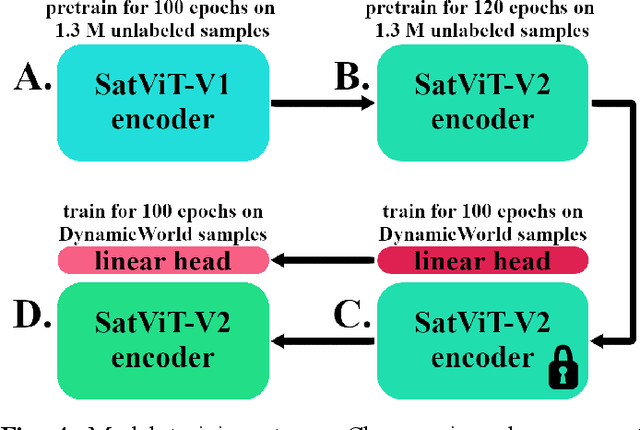
Although the remote sensing (RS) community has begun to pretrain transformers (intended to be fine-tuned on RS tasks), it is unclear how these models perform under distribution shifts. Here, we pretrain a new RS transformer--called SatViT-V2--on 1.3 million satellite-derived RS images, then fine-tune it (along with five other models) to investigate how it performs on distributions not seen during training. We split an expertly labeled land cover dataset into 14 datasets based on source biome. We train each model on each biome separately and test them on all other biomes. In all, this amounts to 1638 biome transfer experiments. After fine-tuning, we find that SatViT-V2 outperforms SatViT-V1 by 3.1% on in-distribution (matching biomes) and 2.8% on out-of-distribution (mismatching biomes) data. Additionally, we find that initializing fine-tuning from the linear probed solution (i.e., leveraging LPFT [1]) improves SatViT-V2's performance by another 1.2% on in-distribution and 2.4% on out-of-distribution data. Next, we find that pretrained RS transformers are better calibrated under distribution shifts than non-pretrained models and leveraging LPFT results in further improvements in model calibration. Lastly, we find that five measures of distribution shift are moderately correlated with biome transfer performance. We share code and pretrained model weights. (https://github.com/antofuller/SatViT)
Audiogram Digitization Tool for Audiological Reports
Aug 31, 2022
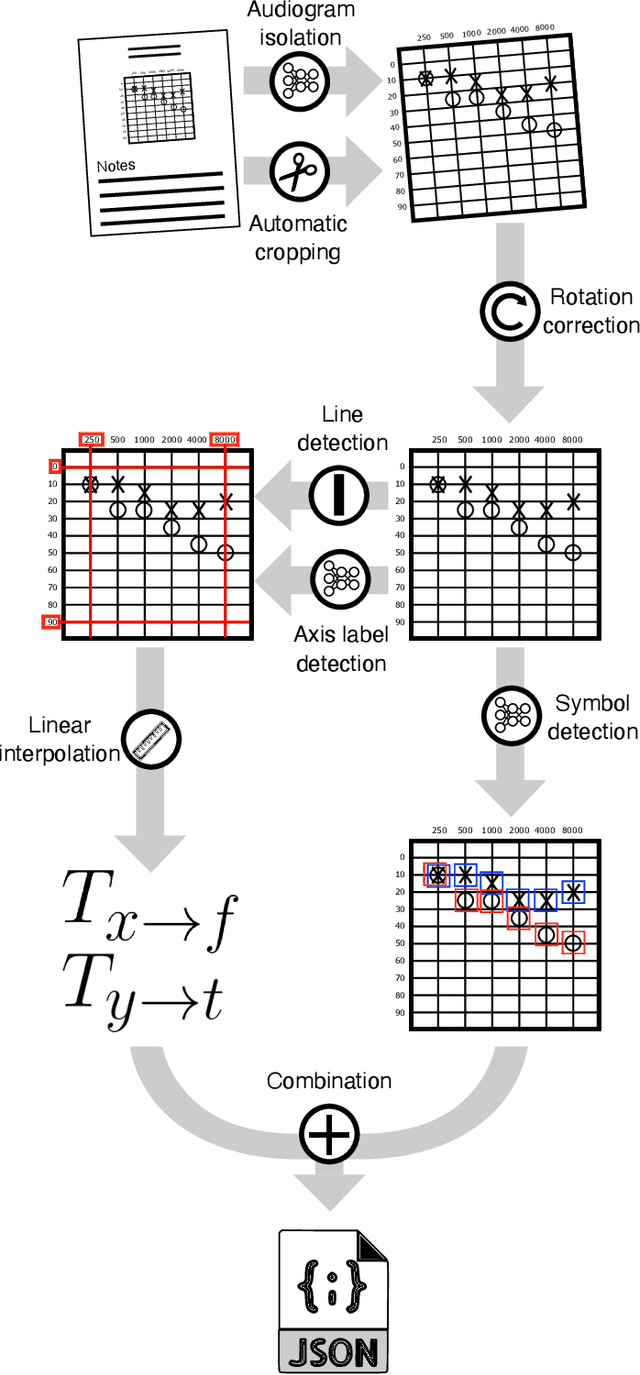


A number of private and public insurers compensate workers whose hearing loss can be directly attributed to excessive exposure to noise in the workplace. The claim assessment process is typically lengthy and requires significant effort from human adjudicators who must interpret hand-recorded audiograms, often sent via fax or equivalent. In this work, we present a solution developed in partnership with the Workplace Safety Insurance Board of Ontario to streamline the adjudication process. In particular, we present the first audiogram digitization algorithm capable of automatically extracting the hearing thresholds from a scanned or faxed audiology report as a proof-of-concept. The algorithm extracts most thresholds within 5 dB accuracy, allowing to substantially lessen the time required to convert an audiogram into digital format in a semi-supervised fashion, and is a first step towards the automation of the adjudication process. The source code for the digitization algorithm and a desktop-based implementation of our NIHL annotation portal is publicly available on GitHub (https://github.com/GreenCUBIC/AudiogramDigitization).