 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeOlmoEarth: Stable Latent Image Modeling for Multimodal Earth Observation
Nov 17, 2025Earth observation data presents a unique challenge: it is spatial like images, sequential like video or text, and highly multimodal. We present OlmoEarth: a multimodal, spatio-temporal foundation model that employs a novel self-supervised learning formulation, masking strategy, and loss all designed for the Earth observation domain. OlmoEarth achieves state-of-the-art performance compared to 12 other foundation models across a variety of research benchmarks and real-world tasks from external partners. When evaluating embeddings OlmoEarth achieves the best performance on 15 out of 24 tasks, and with full fine-tuning it is the best on 19 of 29 tasks. We deploy OlmoEarth as the backbone of an end-to-end platform for data collection, labeling, training, and inference of Earth observation models. The OlmoEarth Platform puts frontier foundation models and powerful data management tools into the hands of non-profits and NGOs working to solve the world's biggest problems. OlmoEarth source code, training data, and pre-trained weights are available at $\href{https://github.com/allenai/olmoearth_pretrain}{\text{https://github.com/allenai/olmoearth_pretrain}}$.
DataS^3: Dataset Subset Selection for Specialization
Apr 22, 2025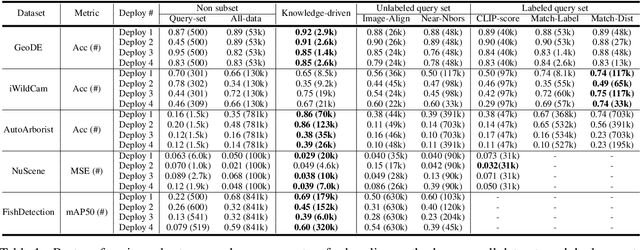
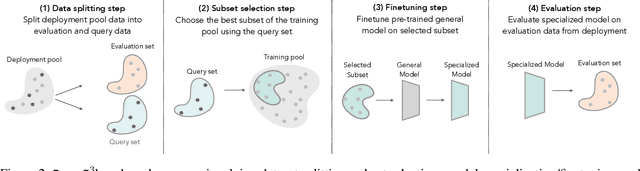
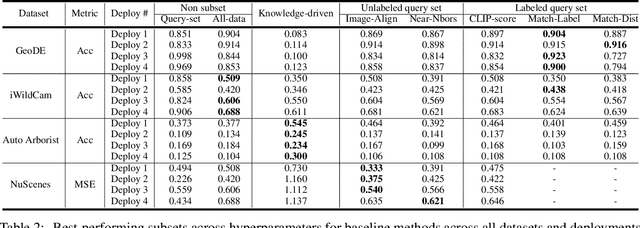
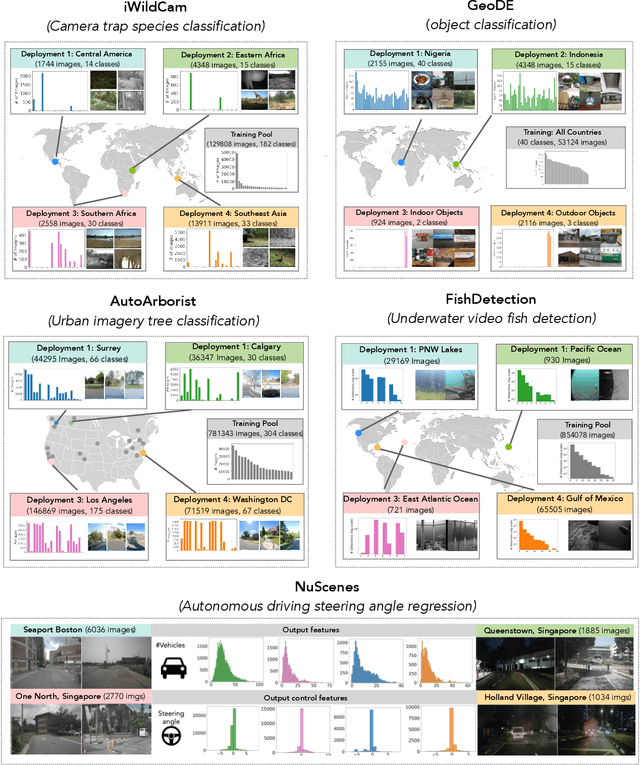
In many real-world machine learning (ML) applications (e.g. detecting broken bones in x-ray images, detecting species in camera traps), in practice models need to perform well on specific deployments (e.g. a specific hospital, a specific national park) rather than the domain broadly. However, deployments often have imbalanced, unique data distributions. Discrepancy between the training distribution and the deployment distribution can lead to suboptimal performance, highlighting the need to select deployment-specialized subsets from the available training data. We formalize dataset subset selection for specialization (DS3): given a training set drawn from a general distribution and a (potentially unlabeled) query set drawn from the desired deployment-specific distribution, the goal is to select a subset of the training data that optimizes deployment performance. We introduce DataS^3; the first dataset and benchmark designed specifically for the DS3 problem. DataS^3 encompasses diverse real-world application domains, each with a set of distinct deployments to specialize in. We conduct a comprehensive study evaluating algorithms from various families--including coresets, data filtering, and data curation--on DataS^3, and find that general-distribution methods consistently fail on deployment-specific tasks. Additionally, we demonstrate the existence of manually curated (deployment-specific) expert subsets that outperform training on all available data with accuracy gains up to 51.3 percent. Our benchmark highlights the critical role of tailored dataset curation in enhancing performance and training efficiency on deployment-specific distributions, which we posit will only become more important as global, public datasets become available across domains and ML models are deployed in the real world.
Galileo: Learning Global and Local Features in Pretrained Remote Sensing Models
Feb 13, 2025From crop mapping to flood detection, machine learning in remote sensing has a wide range of societally beneficial applications. The commonalities between remote sensing data in these applications present an opportunity for pretrained machine learning models tailored to remote sensing to reduce the labeled data and effort required to solve individual tasks. However, such models must be: (i) flexible enough to ingest input data of varying sensor modalities and shapes (i.e., of varying spatial and temporal dimensions), and (ii) able to model Earth surface phenomena of varying scales and types. To solve this gap, we present Galileo, a family of pretrained remote sensing models designed to flexibly process multimodal remote sensing data. We also introduce a novel and highly effective self-supervised learning approach to learn both large- and small-scale features, a challenge not addressed by previous models. Our Galileo models obtain state-of-the-art results across diverse remote sensing tasks.
Classification Drives Geographic Bias in Street Scene Segmentation
Dec 15, 2024



Previous studies showed that image datasets lacking geographic diversity can lead to biased performance in models trained on them. While earlier work studied general-purpose image datasets (e.g., ImageNet) and simple tasks like image recognition, we investigated geo-biases in real-world driving datasets on a more complex task: instance segmentation. We examined if instance segmentation models trained on European driving scenes (Eurocentric models) are geo-biased. Consistent with previous work, we found that Eurocentric models were geo-biased. Interestingly, we found that geo-biases came from classification errors rather than localization errors, with classification errors alone contributing 10-90% of the geo-biases in segmentation and 19-88% of the geo-biases in detection. This showed that while classification is geo-biased, localization (including detection and segmentation) is geographically robust. Our findings show that in region-specific models (e.g., Eurocentric models), geo-biases from classification errors can be significantly mitigated by using coarser classes (e.g., grouping car, bus, and truck as 4-wheeler).
How accurate are existing land cover maps for agriculture in Sub-Saharan Africa?
Jul 05, 2023Satellite Earth observations (EO) can provide affordable and timely information for assessing crop conditions and food production. Such monitoring systems are essential in Africa, where there is high food insecurity and sparse agricultural statistics. EO-based monitoring systems require accurate cropland maps to provide information about croplands, but there is a lack of data to determine which of the many available land cover maps most accurately identify cropland in African countries. This study provides a quantitative evaluation and intercomparison of 11 publicly available land cover maps to assess their suitability for cropland classification and EO-based agriculture monitoring in Africa using statistically rigorous reference datasets from 8 countries. We hope the results of this study will help users determine the most suitable map for their needs and encourage future work to focus on resolving inconsistencies between maps and improving accuracy in low-accuracy regions.
Lightweight, Pre-trained Transformers for Remote Sensing Timeseries
Apr 27, 2023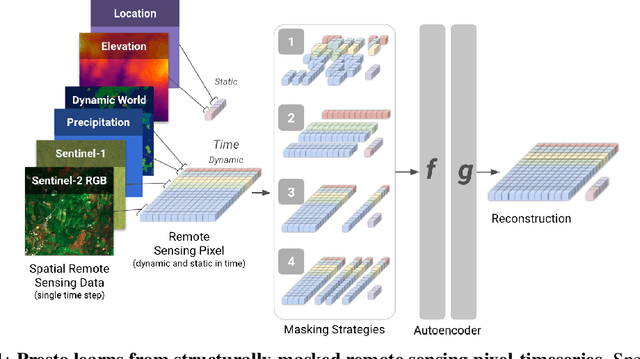
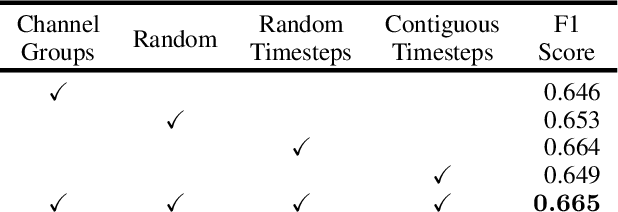

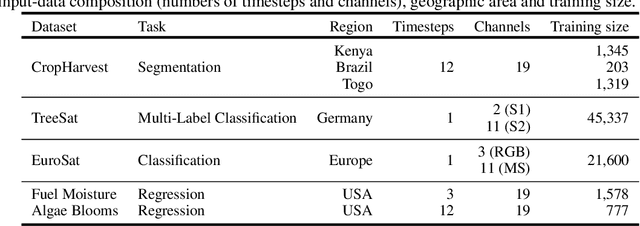
Machine learning algorithms for parsing remote sensing data have a wide range of societally relevant applications, but labels used to train these algorithms can be difficult or impossible to acquire. This challenge has spurred research into self-supervised learning for remote sensing data aiming to unlock the use of machine learning in geographies or application domains where labelled datasets are small. Current self-supervised learning approaches for remote sensing data draw significant inspiration from techniques applied to natural images. However, remote sensing data has important differences from natural images -- for example, the temporal dimension is critical for many tasks and data is collected from many complementary sensors. We show that designing models and self-supervised training techniques specifically for remote sensing data results in both smaller and more performant models. We introduce the Pretrained Remote Sensing Transformer (Presto), a transformer-based model pre-trained on remote sensing pixel-timeseries data. Presto excels at a wide variety of globally distributed remote sensing tasks and outperforms much larger models. Presto can be used for transfer learning or as a feature extractor for simple models, enabling efficient deployment at scale.
TIML: Task-Informed Meta-Learning for Agriculture
Feb 04, 2022
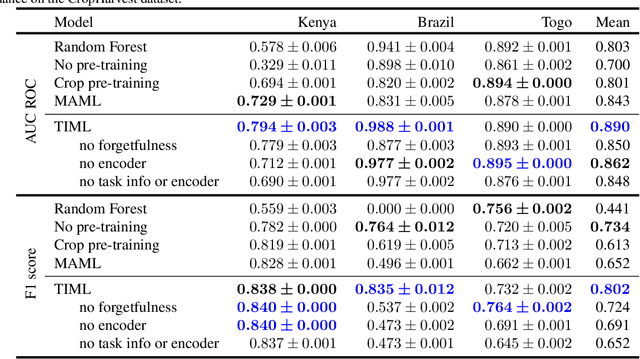

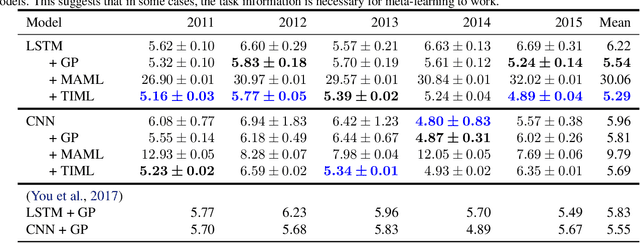
Labeled datasets for agriculture are extremely spatially imbalanced. When developing algorithms for data-sparse regions, a natural approach is to use transfer learning from data-rich regions. While standard transfer learning approaches typically leverage only direct inputs and outputs, geospatial imagery and agricultural data are rich in metadata that can inform transfer learning algorithms, such as the spatial coordinates of data-points or the class of task being learned. We build on previous work exploring the use of meta-learning for agricultural contexts in data-sparse regions and introduce task-informed meta-learning (TIML), an augmentation to model-agnostic meta-learning which takes advantage of task-specific metadata. We apply TIML to crop type classification and yield estimation, and find that TIML significantly improves performance compared to a range of benchmarks in both contexts, across a diversity of model architectures. While we focus on tasks from agriculture, TIML could offer benefits to any meta-learning setup with task-specific metadata, such as classification of geo-tagged images and species distribution modelling.
Rapid Response Crop Maps in Data Sparse Regions
Jun 23, 2020


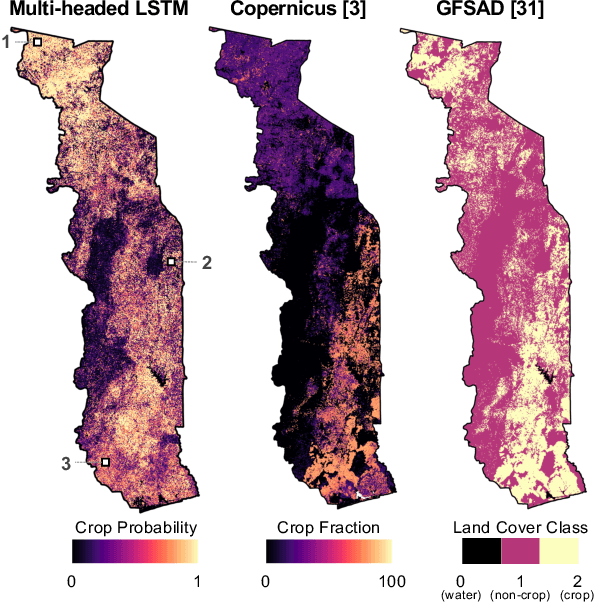
Spatial information on cropland distribution, often called cropland or crop maps, are critical inputs for a wide range of agriculture and food security analyses and decisions. However, high-resolution cropland maps are not readily available for most countries, especially in regions dominated by smallholder farming (e.g., sub-Saharan Africa). These maps are especially critical in times of crisis when decision makers need to rapidly design and enact agriculture-related policies and mitigation strategies, including providing humanitarian assistance, dispersing targeted aid, or boosting productivity for farmers. A major challenge for developing crop maps is that many regions do not have readily accessible ground truth data on croplands necessary for training and validating predictive models, and field campaigns are not feasible for collecting labels for rapid response. We present a method for rapid mapping of croplands in regions where little to no ground data is available. We present results for this method in Togo, where we delivered a high-resolution (10 m) cropland map in under 10 days to facilitate rapid response to the COVID-19 pandemic by the Togolese government. This demonstrated a successful transition of machine learning applications research to operational rapid response in a real humanitarian crisis. All maps, data, and code are publicly available to enable future research and operational systems in data-sparse regions.