 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMOMO: Mars Orbital Model Foundation Model for Mars Orbital Applications
Apr 03, 2026We introduce MOMO, the first multi-sensor foundation model for Mars remote sensing. MOMO uses model merge to integrate representations learned independently from three key Martian sensors (HiRISE, CTX, and THEMIS), spanning resolutions from 0.25 m/pixel to 100 m/pixel. Central to our method is our novel Equal Validation Loss (EVL) strategy, which aligns checkpoints across sensors based on validation loss similarity before fusion via task arithmetic. This ensures models are merged at compatible convergence stages, leading to improved stability and generalization. We train MOMO on a large-scale, high-quality corpus of $\sim 12$ million samples curated from Mars orbital data and evaluate it on 9 downstream tasks from Mars-Bench. MOMO achieves better overall performance compared to ImageNet pre-trained, earth observation foundation model, sensor-specific pre-training, and fully-supervised baselines. Particularly on segmentation tasks, MOMO shows consistent and significant performance improvement. Our results demonstrate that model merging through an optimal checkpoint selection strategy provides an effective approach for building foundation models for multi-resolution data. The model weights, pretraining code, pretraining data, and evaluation code are available at: https://github.com/kerner-lab/MOMO.
Measuring directional bias amplification in image captions using predictability
Mar 10, 2025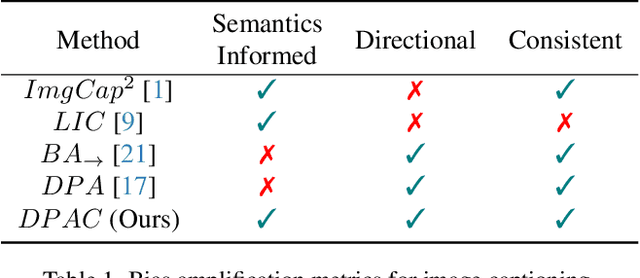
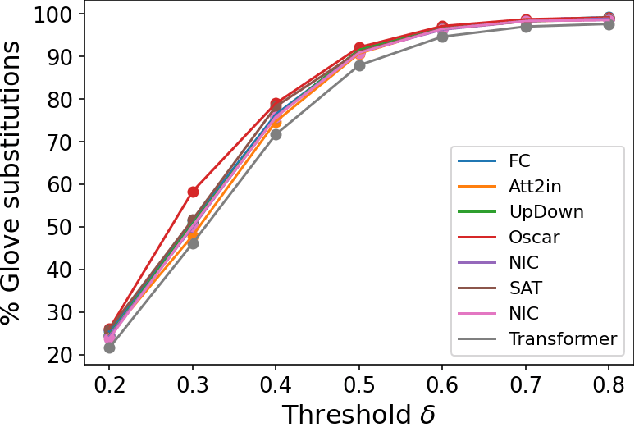
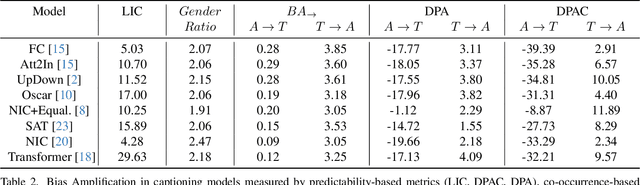
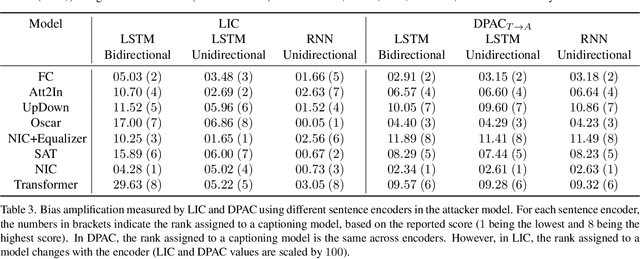
When we train models on biased ML datasets, they not only learn these biases but can inflate them at test time - a phenomenon called bias amplification. To measure bias amplification in ML datasets, many co-occurrence-based metrics have been proposed. Co-occurrence-based metrics are effective in measuring bias amplification in simple problems like image classification. However, these metrics are ineffective for complex problems like image captioning as they cannot capture the semantics of a caption. To measure bias amplification in captions, prior work introduced a predictability-based metric called Leakage in Captioning (LIC). While LIC captures the semantics and context of captions, it has limitations. LIC cannot identify the direction in which bias is amplified, poorly estimates dataset bias due to a weak vocabulary substitution strategy, and is highly sensitive to attacker models (a hyperparameter in predictability-based metrics). To overcome these issues, we propose Directional Predictability Amplification in Captioning (DPAC). DPAC measures directional bias amplification in captions, provides a better estimate of dataset bias using an improved substitution strategy, and is less sensitive to attacker models. Our experiments on the COCO captioning dataset show how DPAC is the most reliable metric to measure bias amplification in captions.
Classification Drives Geographic Bias in Street Scene Segmentation
Dec 15, 2024



Previous studies showed that image datasets lacking geographic diversity can lead to biased performance in models trained on them. While earlier work studied general-purpose image datasets (e.g., ImageNet) and simple tasks like image recognition, we investigated geo-biases in real-world driving datasets on a more complex task: instance segmentation. We examined if instance segmentation models trained on European driving scenes (Eurocentric models) are geo-biased. Consistent with previous work, we found that Eurocentric models were geo-biased. Interestingly, we found that geo-biases came from classification errors rather than localization errors, with classification errors alone contributing 10-90% of the geo-biases in segmentation and 19-88% of the geo-biases in detection. This showed that while classification is geo-biased, localization (including detection and segmentation) is geographically robust. Our findings show that in region-specific models (e.g., Eurocentric models), geo-biases from classification errors can be significantly mitigated by using coarser classes (e.g., grouping car, bus, and truck as 4-wheeler).
Making Bias Amplification in Balanced Datasets Directional and Interpretable
Dec 15, 2024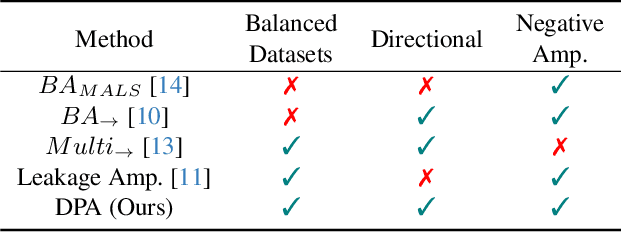
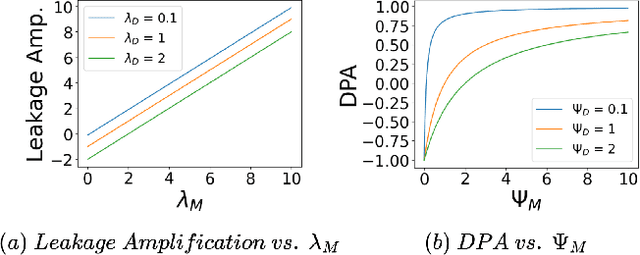

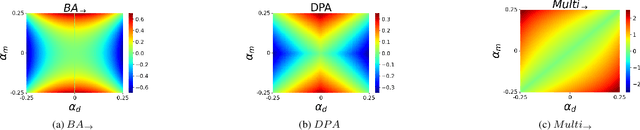
Most of the ML datasets we use today are biased. When we train models on these biased datasets, they often not only learn dataset biases but can also amplify them -- a phenomenon known as bias amplification. Several co-occurrence-based metrics have been proposed to measure bias amplification between a protected attribute A (e.g., gender) and a task T (e.g., cooking). However, these metrics fail to measure biases when A is balanced with T. To measure bias amplification in balanced datasets, recent work proposed a predictability-based metric called leakage amplification. However, leakage amplification cannot identify the direction in which biases are amplified. In this work, we propose a new predictability-based metric called directional predictability amplification (DPA). DPA measures directional bias amplification, even for balanced datasets. Unlike leakage amplification, DPA is easier to interpret and less sensitive to attacker models (a hyperparameter in predictability-based metrics). Our experiments on tabular and image datasets show that DPA is an effective metric for measuring directional bias amplification. The code will be available soon.