 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMeasuring directional bias amplification in image captions using predictability
Paper and Code
Mar 10, 2025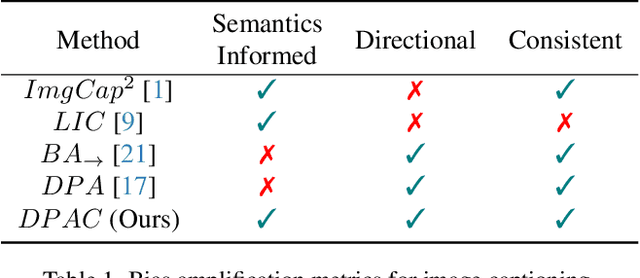
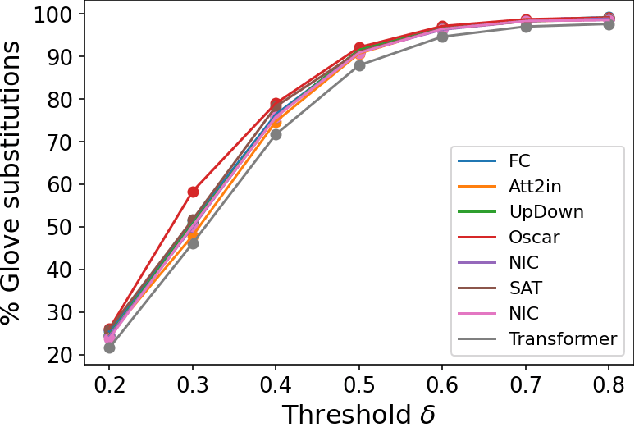
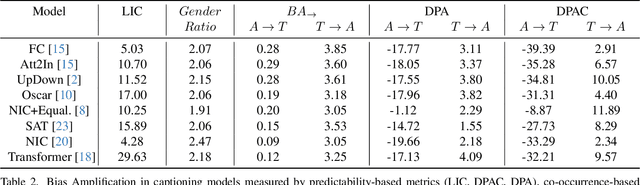
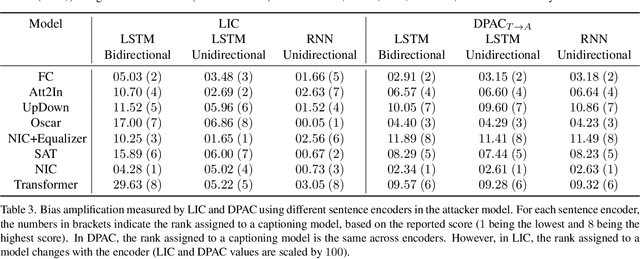
When we train models on biased ML datasets, they not only learn these biases but can inflate them at test time - a phenomenon called bias amplification. To measure bias amplification in ML datasets, many co-occurrence-based metrics have been proposed. Co-occurrence-based metrics are effective in measuring bias amplification in simple problems like image classification. However, these metrics are ineffective for complex problems like image captioning as they cannot capture the semantics of a caption. To measure bias amplification in captions, prior work introduced a predictability-based metric called Leakage in Captioning (LIC). While LIC captures the semantics and context of captions, it has limitations. LIC cannot identify the direction in which bias is amplified, poorly estimates dataset bias due to a weak vocabulary substitution strategy, and is highly sensitive to attacker models (a hyperparameter in predictability-based metrics). To overcome these issues, we propose Directional Predictability Amplification in Captioning (DPAC). DPAC measures directional bias amplification in captions, provides a better estimate of dataset bias using an improved substitution strategy, and is less sensitive to attacker models. Our experiments on the COCO captioning dataset show how DPAC is the most reliable metric to measure bias amplification in captions.