 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeCoFrGeNet: Continued Fraction Architectures for Language Generation
Jan 29, 2026Transformers are arguably the preferred architecture for language generation. In this paper, inspired by continued fractions, we introduce a new function class for generative modeling. The architecture family implementing this function class is named CoFrGeNets - Continued Fraction Generative Networks. We design novel architectural components based on this function class that can replace Multi-head Attention and Feed-Forward Networks in Transformer blocks while requiring much fewer parameters. We derive custom gradient formulations to optimize the proposed components more accurately and efficiently than using standard PyTorch-based gradients. Our components are a plug-in replacement requiring little change in training or inference procedures that have already been put in place for Transformer-based models thus making our approach easy to incorporate in large industrial workflows. We experiment on two very different transformer architectures GPT2-xl (1.5B) and Llama3 (3.2B), where the former we pre-train on OpenWebText and GneissWeb, while the latter we pre-train on the docling data mix which consists of nine different datasets. Results show that the performance on downstream classification, Q\& A, reasoning and text understanding tasks of our models is competitive and sometimes even superior to the original models with $\frac{2}{3}$ to $\frac{1}{2}$ the parameters and shorter pre-training time. We believe that future implementations customized to hardware will further bring out the true potential of our architectures.
Humble AI in the real-world: the case of algorithmic hiring
May 27, 2025Humble AI (Knowles et al., 2023) argues for cautiousness in AI development and deployments through scepticism (accounting for limitations of statistical learning), curiosity (accounting for unexpected outcomes), and commitment (accounting for multifaceted values beyond performance). We present a real-world case study for humble AI in the domain of algorithmic hiring. Specifically, we evaluate virtual screening algorithms in a widely used hiring platform that matches candidates to job openings. There are several challenges in misrecognition and stereotyping in such contexts that are difficult to assess through standard fairness and trust frameworks; e.g., someone with a non-traditional background is less likely to rank highly. We demonstrate technical feasibility of how humble AI principles can be translated to practice through uncertainty quantification of ranks, entropy estimates, and a user experience that highlights algorithmic unknowns. We describe preliminary discussions with focus groups made up of recruiters. Future user studies seek to evaluate whether the higher cognitive load of a humble AI system fosters a climate of trust in its outcomes.
Paying Alignment Tax with Contrastive Learning
May 25, 2025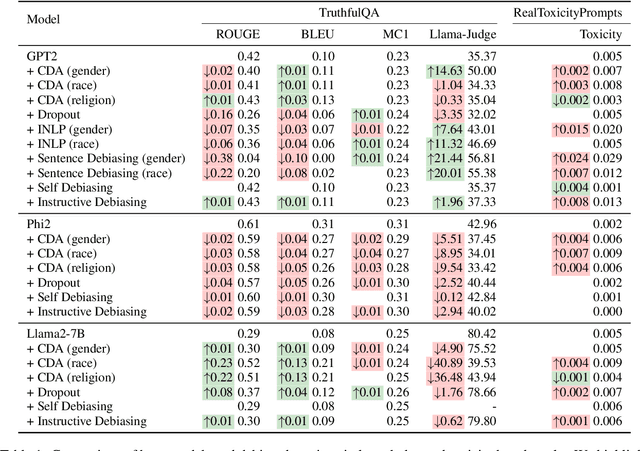
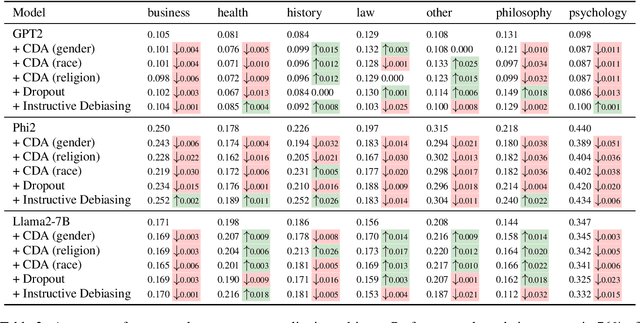

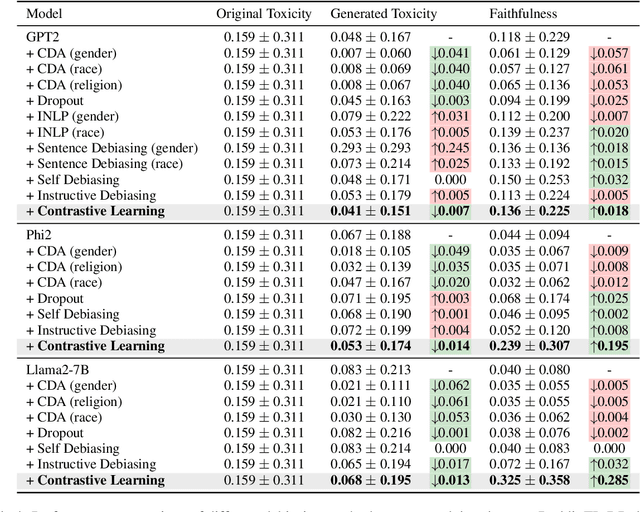
Current debiasing approaches often result a degradation in model capabilities such as factual accuracy and knowledge retention. Through systematic evaluation across multiple benchmarks, we demonstrate that existing debiasing methods face fundamental trade-offs, particularly in smaller models, leading to reduced truthfulness, knowledge loss, or unintelligible outputs. To address these limitations, we propose a contrastive learning framework that learns through carefully constructed positive and negative examples. Our approach introduces contrast computation and dynamic loss scaling to balance bias mitigation with faithfulness preservation. Experimental results across multiple model scales demonstrate that our method achieves substantial improvements in both toxicity reduction and faithfulness preservation. Most importantly, we show that our framework is the first to consistently improve both metrics simultaneously, avoiding the capability degradation characteristic of existing approaches. These results suggest that explicit modeling of both positive and negative examples through contrastive learning could be a promising direction for reducing the alignment tax in language model debiasing.
Measuring directional bias amplification in image captions using predictability
Mar 10, 2025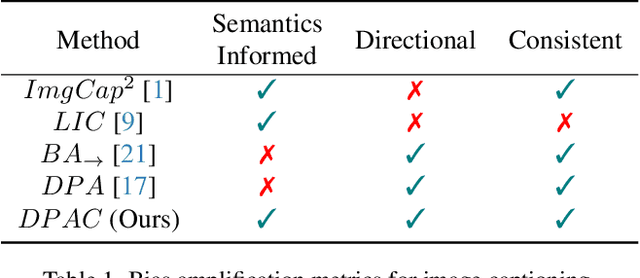
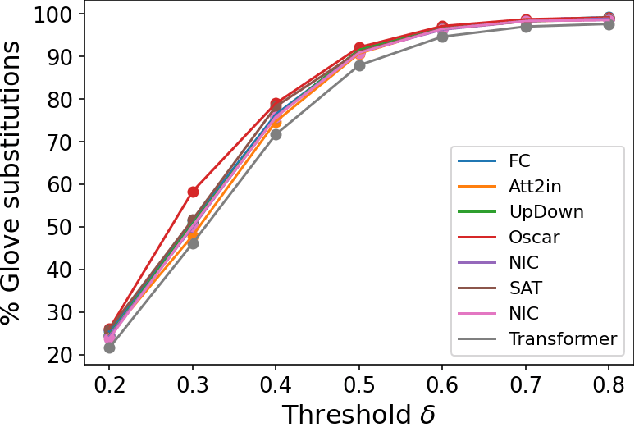
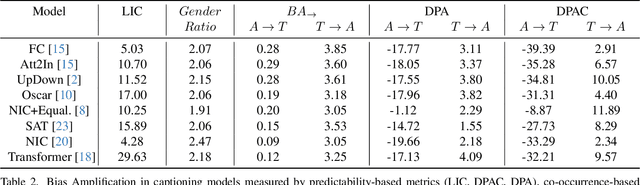
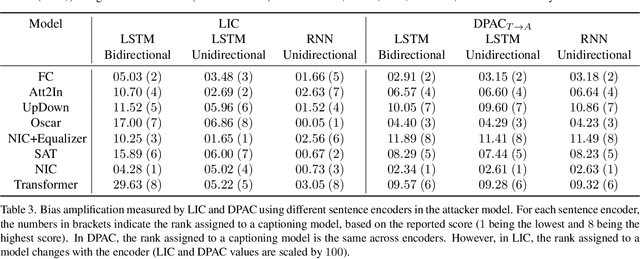
When we train models on biased ML datasets, they not only learn these biases but can inflate them at test time - a phenomenon called bias amplification. To measure bias amplification in ML datasets, many co-occurrence-based metrics have been proposed. Co-occurrence-based metrics are effective in measuring bias amplification in simple problems like image classification. However, these metrics are ineffective for complex problems like image captioning as they cannot capture the semantics of a caption. To measure bias amplification in captions, prior work introduced a predictability-based metric called Leakage in Captioning (LIC). While LIC captures the semantics and context of captions, it has limitations. LIC cannot identify the direction in which bias is amplified, poorly estimates dataset bias due to a weak vocabulary substitution strategy, and is highly sensitive to attacker models (a hyperparameter in predictability-based metrics). To overcome these issues, we propose Directional Predictability Amplification in Captioning (DPAC). DPAC measures directional bias amplification in captions, provides a better estimate of dataset bias using an improved substitution strategy, and is less sensitive to attacker models. Our experiments on the COCO captioning dataset show how DPAC is the most reliable metric to measure bias amplification in captions.
Foundation Models at Work: Fine-Tuning for Fairness in Algorithmic Hiring
Jan 13, 2025Foundation models require fine-tuning to ensure their generative outputs align with intended results for specific tasks. Automating this fine-tuning process is challenging, as it typically needs human feedback that can be expensive to acquire. We present AutoRefine, a method that leverages reinforcement learning for targeted fine-tuning, utilizing direct feedback from measurable performance improvements in specific downstream tasks. We demonstrate the method for a problem arising in algorithmic hiring platforms where linguistic biases influence a recommendation system. In this setting, a generative model seeks to rewrite given job specifications to receive more diverse candidate matches from a recommendation engine which matches jobs to candidates. Our model detects and regulates biases in job descriptions to meet diversity and fairness criteria. The experiments on a public hiring dataset and a real-world hiring platform showcase how large language models can assist in identifying and mitigation biases in the real world.
Making Bias Amplification in Balanced Datasets Directional and Interpretable
Dec 15, 2024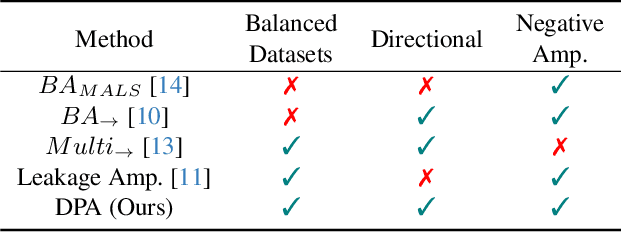
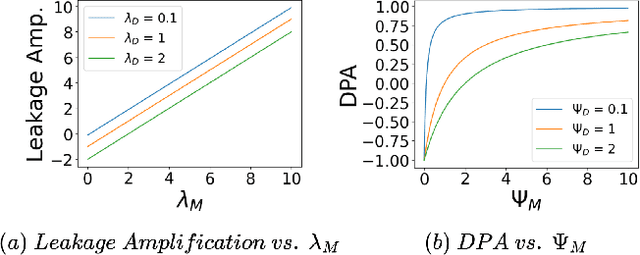

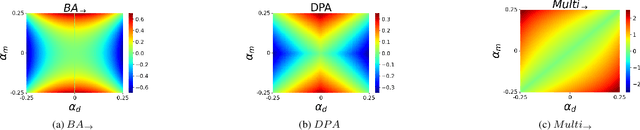
Most of the ML datasets we use today are biased. When we train models on these biased datasets, they often not only learn dataset biases but can also amplify them -- a phenomenon known as bias amplification. Several co-occurrence-based metrics have been proposed to measure bias amplification between a protected attribute A (e.g., gender) and a task T (e.g., cooking). However, these metrics fail to measure biases when A is balanced with T. To measure bias amplification in balanced datasets, recent work proposed a predictability-based metric called leakage amplification. However, leakage amplification cannot identify the direction in which biases are amplified. In this work, we propose a new predictability-based metric called directional predictability amplification (DPA). DPA measures directional bias amplification, even for balanced datasets. Unlike leakage amplification, DPA is easier to interpret and less sensitive to attacker models (a hyperparameter in predictability-based metrics). Our experiments on tabular and image datasets show that DPA is an effective metric for measuring directional bias amplification. The code will be available soon.
Classification Drives Geographic Bias in Street Scene Segmentation
Dec 15, 2024



Previous studies showed that image datasets lacking geographic diversity can lead to biased performance in models trained on them. While earlier work studied general-purpose image datasets (e.g., ImageNet) and simple tasks like image recognition, we investigated geo-biases in real-world driving datasets on a more complex task: instance segmentation. We examined if instance segmentation models trained on European driving scenes (Eurocentric models) are geo-biased. Consistent with previous work, we found that Eurocentric models were geo-biased. Interestingly, we found that geo-biases came from classification errors rather than localization errors, with classification errors alone contributing 10-90% of the geo-biases in segmentation and 19-88% of the geo-biases in detection. This showed that while classification is geo-biased, localization (including detection and segmentation) is geographically robust. Our findings show that in region-specific models (e.g., Eurocentric models), geo-biases from classification errors can be significantly mitigated by using coarser classes (e.g., grouping car, bus, and truck as 4-wheeler).
Black-box Uncertainty Quantification Method for LLM-as-a-Judge
Oct 15, 2024
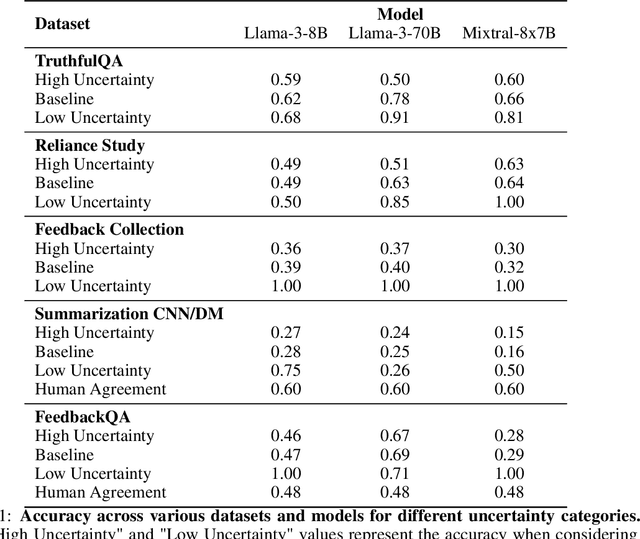
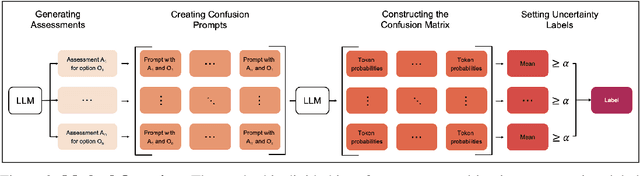

LLM-as-a-Judge is a widely used method for evaluating the performance of Large Language Models (LLMs) across various tasks. We address the challenge of quantifying the uncertainty of LLM-as-a-Judge evaluations. While uncertainty quantification has been well-studied in other domains, applying it effectively to LLMs poses unique challenges due to their complex decision-making capabilities and computational demands. In this paper, we introduce a novel method for quantifying uncertainty designed to enhance the trustworthiness of LLM-as-a-Judge evaluations. The method quantifies uncertainty by analyzing the relationships between generated assessments and possible ratings. By cross-evaluating these relationships and constructing a confusion matrix based on token probabilities, the method derives labels of high or low uncertainty. We evaluate our method across multiple benchmarks, demonstrating a strong correlation between the accuracy of LLM evaluations and the derived uncertainty scores. Our findings suggest that this method can significantly improve the reliability and consistency of LLM-as-a-Judge evaluations.
On Efficient and Statistical Quality Estimation for Data Annotation
May 20, 2024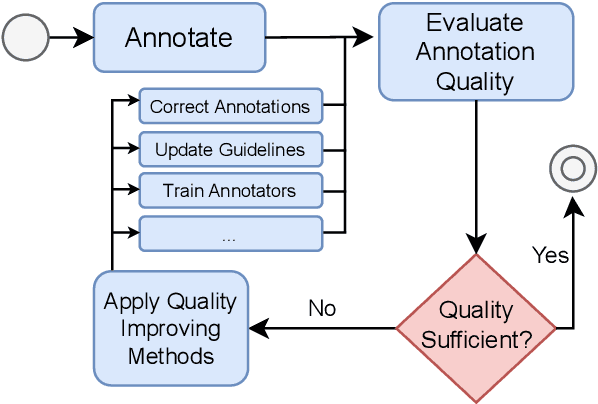
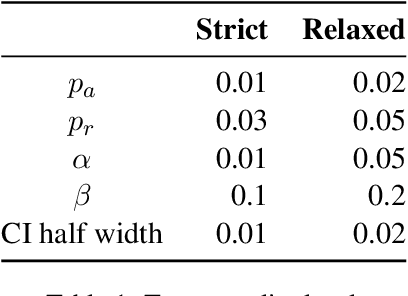
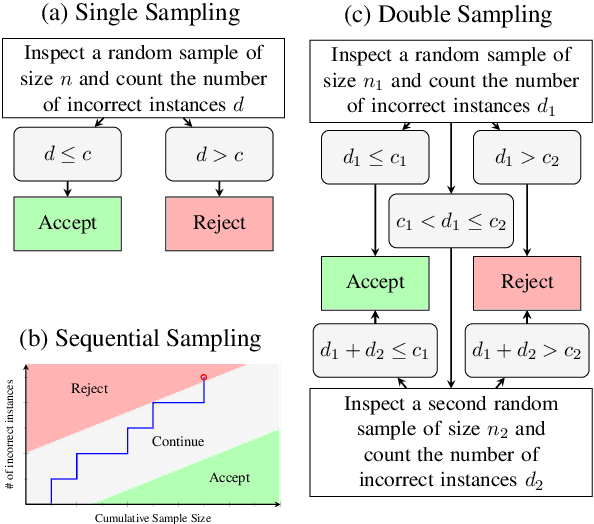
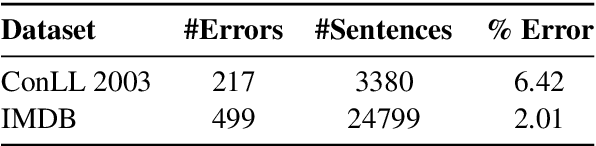
Annotated datasets are an essential ingredient to train, evaluate, compare and productionalize supervised machine learning models. It is therefore imperative that annotations are of high quality. For their creation, good quality management and thereby reliable quality estimates are needed. Then, if quality is insufficient during the annotation process, rectifying measures can be taken to improve it. Quality estimation is often performed by having experts manually label instances as correct or incorrect. But checking all annotated instances tends to be expensive. Therefore, in practice, usually only subsets are inspected; sizes are chosen mostly without justification or regard to statistical power and more often than not, are relatively small. Basing estimates on small sample sizes, however, can lead to imprecise values for the error rate. Using unnecessarily large sample sizes costs money that could be better spent, for instance on more annotations. Therefore, we first describe in detail how to use confidence intervals for finding the minimal sample size needed to estimate the annotation error rate. Then, we propose applying acceptance sampling as an alternative to error rate estimation We show that acceptance sampling can reduce the required sample sizes up to 50% while providing the same statistical guarantees.
Ranking Large Language Models without Ground Truth
Feb 21, 2024



Evaluation and ranking of large language models (LLMs) has become an important problem with the proliferation of these models and their impact. Evaluation methods either require human responses which are expensive to acquire or use pairs of LLMs to evaluate each other which can be unreliable. In this paper, we provide a novel perspective where, given a dataset of prompts (viz. questions, instructions, etc.) and a set of LLMs, we rank them without access to any ground truth or reference responses. Inspired by real life where both an expert and a knowledgeable person can identify a novice our main idea is to consider triplets of models, where each one of them evaluates the other two, correctly identifying the worst model in the triplet with high probability. We also analyze our idea and provide sufficient conditions for it to succeed. Applying this idea repeatedly, we propose two methods to rank LLMs. In experiments on different generative tasks (summarization, multiple-choice, and dialog), our methods reliably recover close to true rankings without reference data. This points to a viable low-resource mechanism for practical use.