 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeBlack-box Uncertainty Quantification Method for LLM-as-a-Judge
Paper and Code
Oct 15, 2024
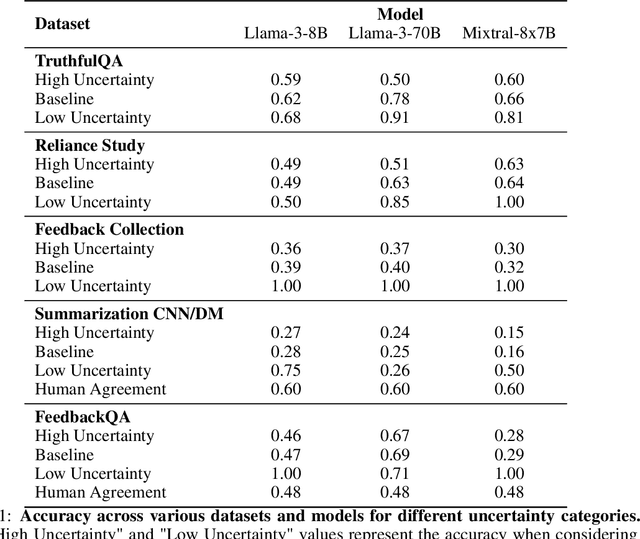
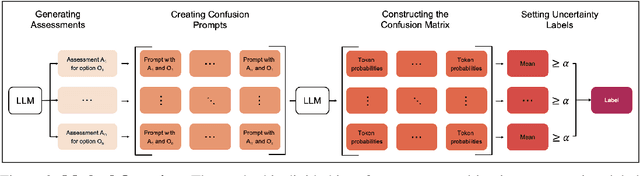

LLM-as-a-Judge is a widely used method for evaluating the performance of Large Language Models (LLMs) across various tasks. We address the challenge of quantifying the uncertainty of LLM-as-a-Judge evaluations. While uncertainty quantification has been well-studied in other domains, applying it effectively to LLMs poses unique challenges due to their complex decision-making capabilities and computational demands. In this paper, we introduce a novel method for quantifying uncertainty designed to enhance the trustworthiness of LLM-as-a-Judge evaluations. The method quantifies uncertainty by analyzing the relationships between generated assessments and possible ratings. By cross-evaluating these relationships and constructing a confusion matrix based on token probabilities, the method derives labels of high or low uncertainty. We evaluate our method across multiple benchmarks, demonstrating a strong correlation between the accuracy of LLM evaluations and the derived uncertainty scores. Our findings suggest that this method can significantly improve the reliability and consistency of LLM-as-a-Judge evaluations.