 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeGranite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Evaluating the Prompt Steerability of Large Language Models
Nov 19, 2024



Building pluralistic AI requires designing models that are able to be shaped to represent a wide range of value systems and cultures. Achieving this requires first being able to evaluate the degree to which a given model is capable of reflecting various personas. To this end, we propose a benchmark for evaluating the steerability of model personas as a function of prompting. Our design is based on a formal definition of prompt steerability, which analyzes the degree to which a model's joint behavioral distribution can be shifted from its baseline behavior. By defining steerability indices and inspecting how these indices change as a function of steering effort, we can estimate the steerability of a model across various persona dimensions and directions. Our benchmark reveals that the steerability of many current models is limited -- due to both a skew in their baseline behavior and an asymmetry in their steerability across many persona dimensions. We release an implementation of our benchmark at https://github.com/IBM/prompt-steering.
Black-box Uncertainty Quantification Method for LLM-as-a-Judge
Oct 15, 2024
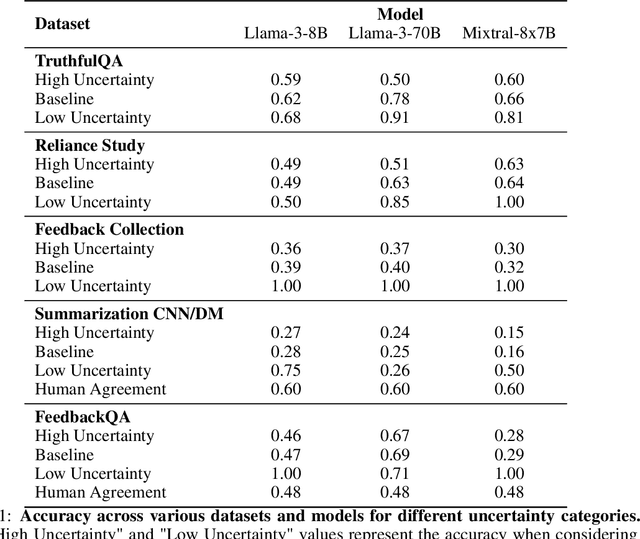
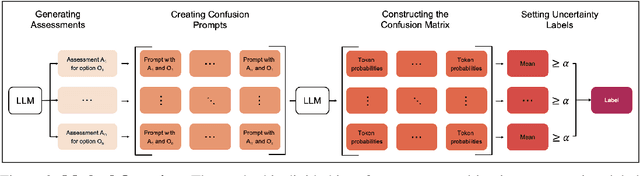

LLM-as-a-Judge is a widely used method for evaluating the performance of Large Language Models (LLMs) across various tasks. We address the challenge of quantifying the uncertainty of LLM-as-a-Judge evaluations. While uncertainty quantification has been well-studied in other domains, applying it effectively to LLMs poses unique challenges due to their complex decision-making capabilities and computational demands. In this paper, we introduce a novel method for quantifying uncertainty designed to enhance the trustworthiness of LLM-as-a-Judge evaluations. The method quantifies uncertainty by analyzing the relationships between generated assessments and possible ratings. By cross-evaluating these relationships and constructing a confusion matrix based on token probabilities, the method derives labels of high or low uncertainty. We evaluate our method across multiple benchmarks, demonstrating a strong correlation between the accuracy of LLM evaluations and the derived uncertainty scores. Our findings suggest that this method can significantly improve the reliability and consistency of LLM-as-a-Judge evaluations.
Exploring Prompt Engineering Practices in the Enterprise
Mar 13, 2024


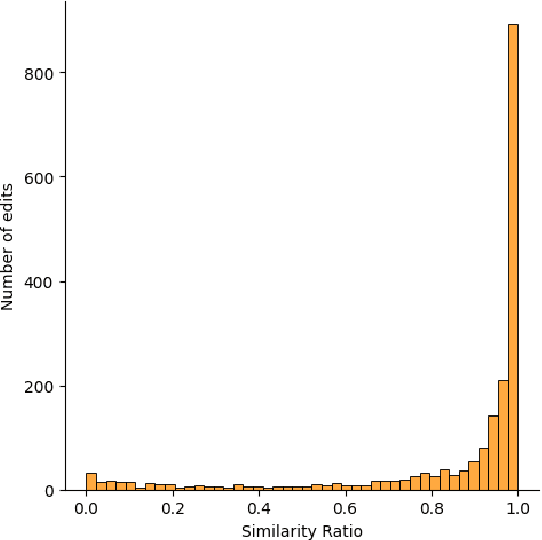
Interaction with Large Language Models (LLMs) is primarily carried out via prompting. A prompt is a natural language instruction designed to elicit certain behaviour or output from a model. In theory, natural language prompts enable non-experts to interact with and leverage LLMs. However, for complex tasks and tasks with specific requirements, prompt design is not trivial. Creating effective prompts requires skill and knowledge, as well as significant iteration in order to determine model behavior, and guide the model to accomplish a particular goal. We hypothesize that the way in which users iterate on their prompts can provide insight into how they think prompting and models work, as well as the kinds of support needed for more efficient prompt engineering. To better understand prompt engineering practices, we analyzed sessions of prompt editing behavior, categorizing the parts of prompts users iterated on and the types of changes they made. We discuss design implications and future directions based on these prompt engineering practices.
A No-Code Low-Code Paradigm for Authoring Business Automations Using Natural Language
Jul 15, 2022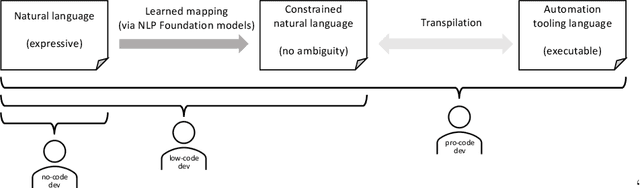
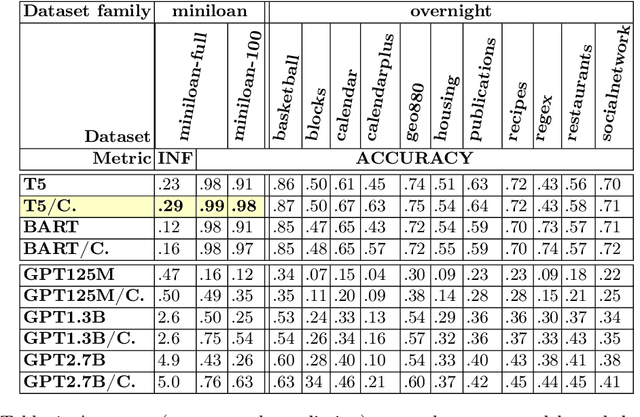

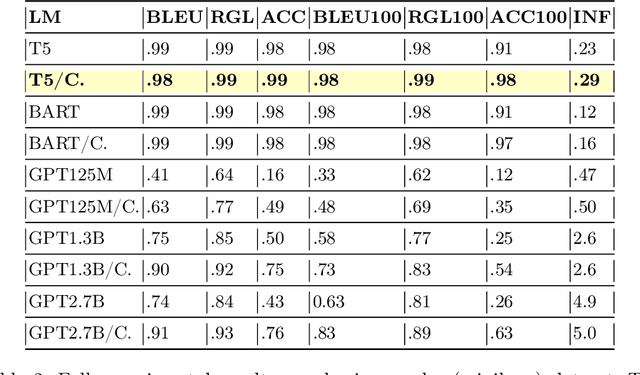
Most business process automation is still developed using traditional automation technologies such as workflow engines. These systems provide domain specific languages that require both business knowledge and programming skills to effectively use. As such, business users often lack adequate programming skills to fully leverage these code oriented environments. We propose a paradigm for the construction of business automations using natural language. The approach applies a large language model to translate business rules and automations described in natural language, into a domain specific language interpretable by a business rule engine. We compare the performance of various language model configurations, across various target domains, and explore the use of constrained decoding to ensure syntactically correct generation of output.
Towards Automating the AI Operations Lifecycle
Mar 28, 2020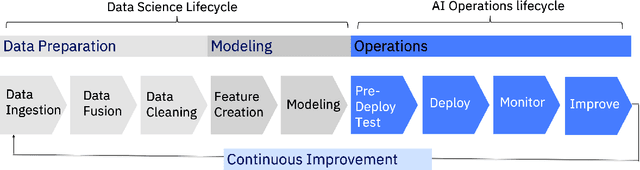
Today's AI deployments often require significant human involvement and skill in the operational stages of the model lifecycle, including pre-release testing, monitoring, problem diagnosis and model improvements. We present a set of enabling technologies that can be used to increase the level of automation in AI operations, thus lowering the human effort required. Since a common source of human involvement is the need to assess the performance of deployed models, we focus on technologies for performance prediction and KPI analysis and show how they can be used to improve automation in the key stages of a typical AI operations pipeline.