 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeRevisiting Group Relative Policy Optimization: Insights into On-Policy and Off-Policy Training
May 28, 2025We revisit Group Relative Policy Optimization (GRPO) in both on-policy and off-policy optimization regimes. Our motivation comes from recent work on off-policy Proximal Policy Optimization (PPO), which improves training stability, sampling efficiency, and memory usage. In addition, a recent analysis of GRPO suggests that estimating the advantage function with off-policy samples could be beneficial. Building on these observations, we adapt GRPO to the off-policy setting. We show that both on-policy and off-policy GRPO objectives yield an improvement in the reward. This result motivates the use of clipped surrogate objectives in the off-policy version of GRPO. We then compare the empirical performance of reinforcement learning with verifiable rewards in post-training using both GRPO variants. Our results show that off-policy GRPO either significantly outperforms or performs on par with its on-policy counterpart.
Causal AI-based Root Cause Identification: Research to Practice at Scale
Feb 25, 2025



Modern applications are built as large, distributed systems spanning numerous modules, teams, and data centers. Despite robust engineering and recovery strategies, failures and performance issues remain inevitable, risking significant disruptions and affecting end users. Rapid and accurate root cause identification is therefore vital to ensure system reliability and maintain key service metrics. We have developed a novel causality-based Root Cause Identification (RCI) algorithm that emphasizes causation over correlation. This algorithm has been integrated into IBM Instana-bridging research to practice at scale-and is now in production use by enterprise customers. By leveraging "causal AI," Instana stands apart from typical Application Performance Management (APM) tools, pinpointing issues in near real-time. This paper highlights Instana's advanced failure diagnosis capabilities, discussing both the theoretical underpinnings and practical implementations of the RCI algorithm. Real-world examples illustrate how our causality-based approach enhances reliability and performance in today's complex system landscapes.
Sparsity May Be All You Need: Sparse Random Parameter Adaptation
Feb 21, 2025Full fine-tuning of large language models for alignment and task adaptation has become prohibitively expensive as models have grown in size. Parameter-Efficient Fine-Tuning (PEFT) methods aim at significantly reducing the computational and memory resources needed for fine-tuning these models by only training on a small number of parameters instead of all model parameters. Currently, the most popular PEFT method is the Low-Rank Adaptation (LoRA), which freezes the parameters of the model to be fine-tuned and introduces a small set of trainable parameters in the form of low-rank matrices. We propose simply reducing the number of trainable parameters by randomly selecting a small proportion of the model parameters to train on. In this paper, we compare the efficiency and performance of our proposed approach with PEFT methods, including LoRA, as well as full parameter fine-tuning.
Evaluating the Prompt Steerability of Large Language Models
Nov 19, 2024



Building pluralistic AI requires designing models that are able to be shaped to represent a wide range of value systems and cultures. Achieving this requires first being able to evaluate the degree to which a given model is capable of reflecting various personas. To this end, we propose a benchmark for evaluating the steerability of model personas as a function of prompting. Our design is based on a formal definition of prompt steerability, which analyzes the degree to which a model's joint behavioral distribution can be shifted from its baseline behavior. By defining steerability indices and inspecting how these indices change as a function of steering effort, we can estimate the steerability of a model across various persona dimensions and directions. Our benchmark reveals that the steerability of many current models is limited -- due to both a skew in their baseline behavior and an asymmetry in their steerability across many persona dimensions. We release an implementation of our benchmark at https://github.com/IBM/prompt-steering.
Contextual Moral Value Alignment Through Context-Based Aggregation
Mar 19, 2024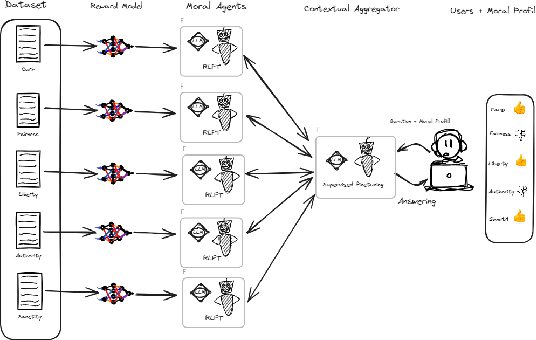
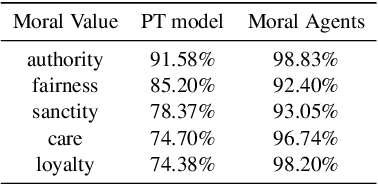
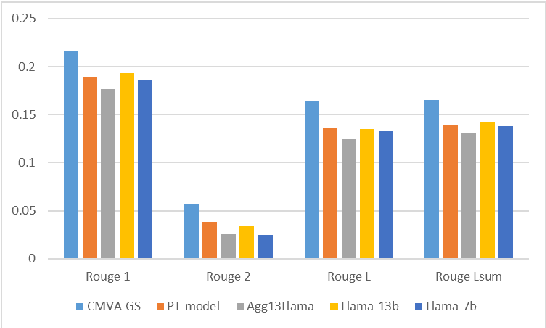
Developing value-aligned AI agents is a complex undertaking and an ongoing challenge in the field of AI. Specifically within the domain of Large Language Models (LLMs), the capability to consolidate multiple independently trained dialogue agents, each aligned with a distinct moral value, into a unified system that can adapt to and be aligned with multiple moral values is of paramount importance. In this paper, we propose a system that does contextual moral value alignment based on contextual aggregation. Here, aggregation is defined as the process of integrating a subset of LLM responses that are best suited to respond to a user input, taking into account features extracted from the user's input. The proposed system shows better results in term of alignment to human value compared to the state of the art.
Alignment Studio: Aligning Large Language Models to Particular Contextual Regulations
Mar 08, 2024The alignment of large language models is usually done by model providers to add or control behaviors that are common or universally understood across use cases and contexts. In contrast, in this article, we present an approach and architecture that empowers application developers to tune a model to their particular values, social norms, laws and other regulations, and orchestrate between potentially conflicting requirements in context. We lay out three main components of such an Alignment Studio architecture: Framers, Instructors, and Auditors that work in concert to control the behavior of a language model. We illustrate this approach with a running example of aligning a company's internal-facing enterprise chatbot to its business conduct guidelines.
Fourier Representations for Black-Box Optimization over Categorical Variables
Feb 08, 2022
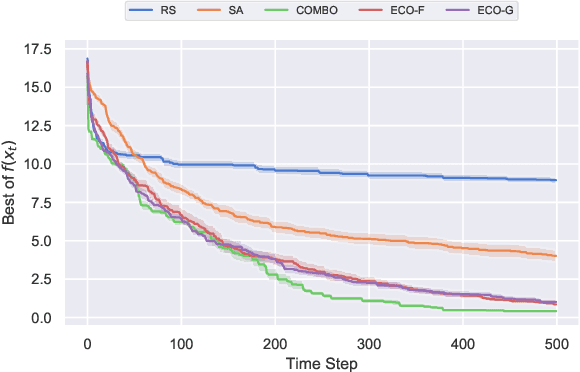
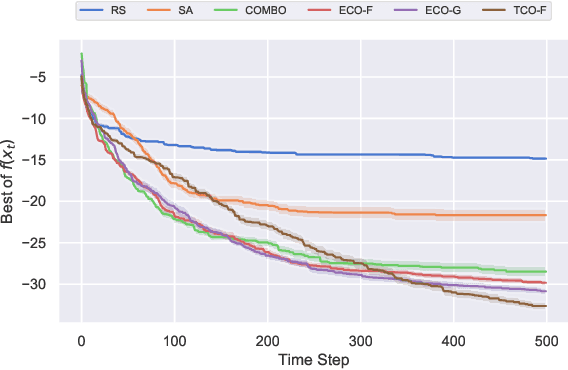
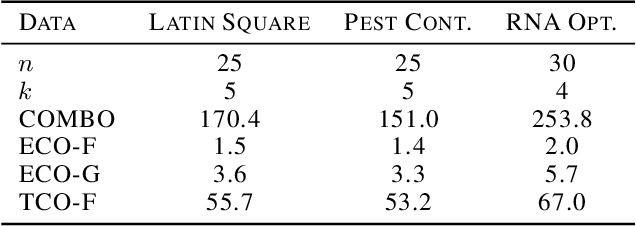
Optimization of real-world black-box functions defined over purely categorical variables is an active area of research. In particular, optimization and design of biological sequences with specific functional or structural properties have a profound impact in medicine, materials science, and biotechnology. Standalone search algorithms, such as simulated annealing (SA) and Monte Carlo tree search (MCTS), are typically used for such optimization problems. In order to improve the performance and sample efficiency of such algorithms, we propose to use existing methods in conjunction with a surrogate model for the black-box evaluations over purely categorical variables. To this end, we present two different representations, a group-theoretic Fourier expansion and an abridged one-hot encoded Boolean Fourier expansion. To learn such representations, we consider two different settings to update our surrogate model. First, we utilize an adversarial online regression setting where Fourier characters of each representation are considered as experts and their respective coefficients are updated via an exponential weight update rule each time the black box is evaluated. Second, we consider a Bayesian setting where queries are selected via Thompson sampling and the posterior is updated via a sparse Bayesian regression model (over our proposed representation) with a regularized horseshoe prior. Numerical experiments over synthetic benchmarks as well as real-world RNA sequence optimization and design problems demonstrate the representational power of the proposed methods, which achieve competitive or superior performance compared to state-of-the-art counterparts, while improving the computation cost and/or sample efficiency, substantially.
Combinatorial Black-Box Optimization with Expert Advice
Jun 06, 2020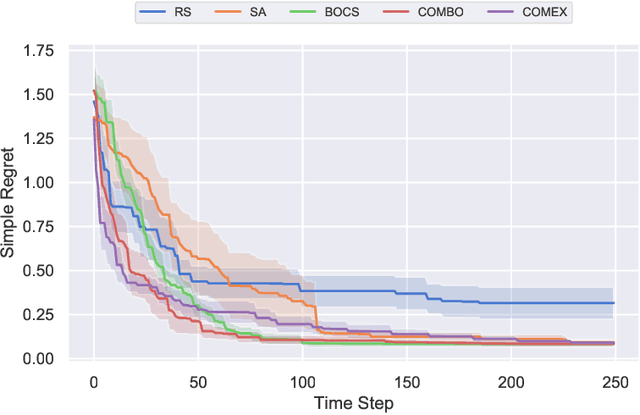
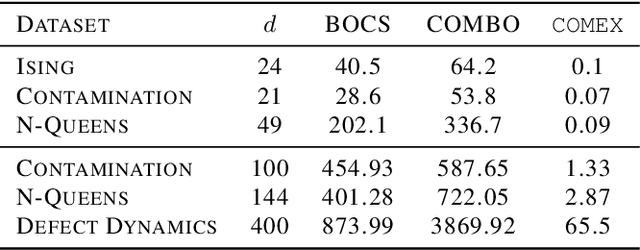
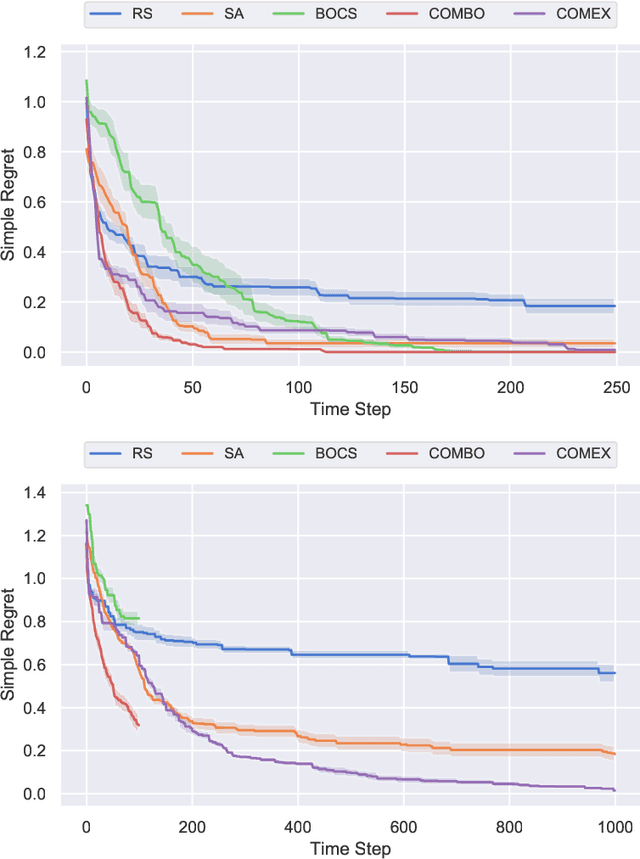
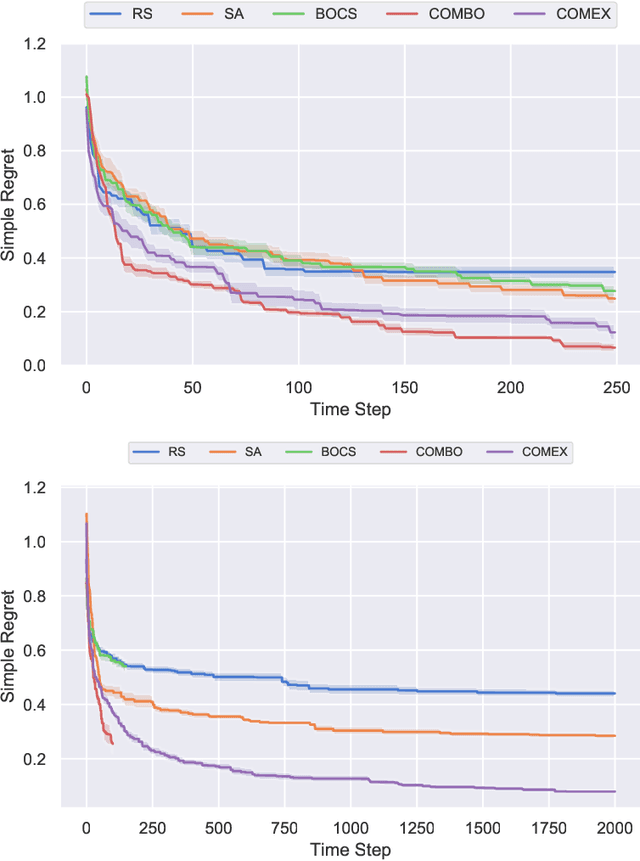
We consider the problem of black-box function optimization over the boolean hypercube. Despite the vast literature on black-box function optimization over continuous domains, not much attention has been paid to learning models for optimization over combinatorial domains until recently. However, the computational complexity of the recently devised algorithms are prohibitive even for moderate numbers of variables; drawing one sample using the existing algorithms is more expensive than a function evaluation for many black-box functions of interest. To address this problem, we propose a computationally efficient model learning algorithm based on multilinear polynomials and exponential weight updates. In the proposed algorithm, we alternate between simulated annealing with respect to the current polynomial representation and updating the weights using monomial experts' advice. Numerical experiments on various datasets in both unconstrained and sum-constrained boolean optimization indicate the competitive performance of the proposed algorithm, while improving the computational time up to several orders of magnitude compared to state-of-the-art algorithms in the literature.
Accelerating Physics-Based Simulations Using Neural Network Proxies: An Application in Oil Reservoir Modeling
May 23, 2019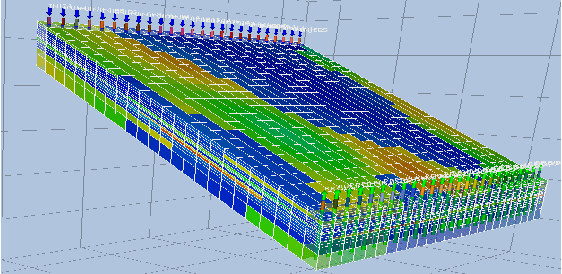
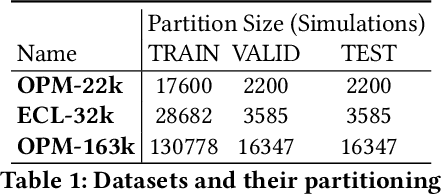
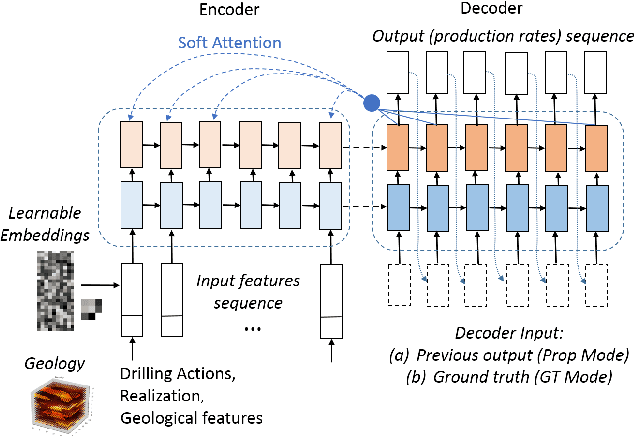
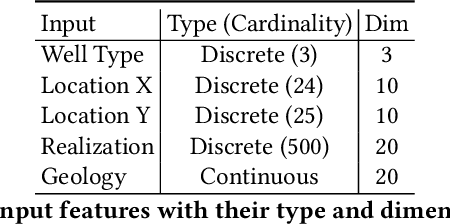
We develop a proxy model based on deep learning methods to accelerate the simulations of oil reservoirs--by three orders of magnitude--compared to industry-strength physics-based PDE solvers. This paper describes a new architectural approach to this task, accompanied by a thorough experimental evaluation on a publicly available reservoir model. We demonstrate that in a practical setting a speedup of more than 2000X can be achieved with an average sequence error of about 10\% relative to the oil-field simulator. The proxy model is contrasted with a high-quality physics-based acceleration baseline and is shown to outperform it by several orders of magnitude. We believe the outcomes presented here are extremely promising and offer a valuable benchmark for continuing research in oil field development optimization. Due to its domain-agnostic architecture, the presented approach can be extended to many applications beyond the field of oil and gas exploration.