 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeQuantum Verifiable Rewards for Post-Training Qiskit Code Assistant
Aug 28, 2025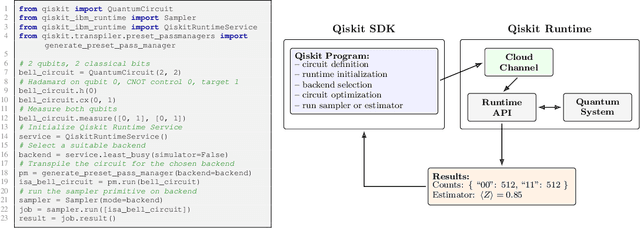

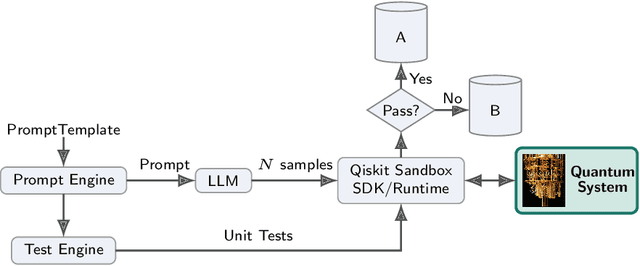

Qiskit is an open-source quantum computing framework that allows users to design, simulate, and run quantum circuits on real quantum hardware. We explore post-training techniques for LLMs to assist in writing Qiskit code. We introduce quantum verification as an effective method for ensuring code quality and executability on quantum hardware. To support this, we developed a synthetic data pipeline that generates quantum problem-unit test pairs and used it to create preference data for aligning LLMs with DPO. Additionally, we trained models using GRPO, leveraging quantum-verifiable rewards provided by the quantum hardware. Our best-performing model, combining DPO and GRPO, surpasses the strongest open-source baselines on the challenging Qiskit-HumanEval-hard benchmark.
Revisiting Group Relative Policy Optimization: Insights into On-Policy and Off-Policy Training
May 28, 2025We revisit Group Relative Policy Optimization (GRPO) in both on-policy and off-policy optimization regimes. Our motivation comes from recent work on off-policy Proximal Policy Optimization (PPO), which improves training stability, sampling efficiency, and memory usage. In addition, a recent analysis of GRPO suggests that estimating the advantage function with off-policy samples could be beneficial. Building on these observations, we adapt GRPO to the off-policy setting. We show that both on-policy and off-policy GRPO objectives yield an improvement in the reward. This result motivates the use of clipped surrogate objectives in the off-policy version of GRPO. We then compare the empirical performance of reinforcement learning with verifiable rewards in post-training using both GRPO variants. Our results show that off-policy GRPO either significantly outperforms or performs on par with its on-policy counterpart.
Customizing a Large Language Model for VHDL Design of High-Performance Microprocessors
May 14, 2025The use of Large Language Models (LLMs) in hardware design has taken off in recent years, principally through its incorporation in tools that increase chip designer productivity. There has been considerable discussion about the use of LLMs in RTL specifications of chip designs, for which the two most popular languages are Verilog and VHDL. LLMs and their use in Verilog design has received significant attention due to the higher popularity of the language, but little attention so far has been given to VHDL despite its continued popularity in the industry. There has also been little discussion about the unique needs of organizations that engage in high-performance processor design, and techniques to deploy AI solutions in these settings. In this paper, we describe our journey in developing a Large Language Model (LLM) specifically for the purpose of explaining VHDL code, a task that has particular importance in an organization with decades of experience and assets in high-performance processor design. We show how we developed test sets specific to our needs and used them for evaluating models as we performed extended pretraining (EPT) of a base LLM. Expert evaluation of the code explanations produced by the EPT model increased to 69% compared to a base model rating of 43%. We further show how we developed an LLM-as-a-judge to gauge models similar to expert evaluators. This led us to deriving and evaluating a host of new models, including an instruction-tuned version of the EPT model with an expected expert evaluator rating of 71%. Our experiments also indicate that with the potential use of newer base models, this rating can be pushed to 85% and beyond. We conclude with a discussion on further improving the quality of hardware design LLMs using exciting new developments in the Generative AI world.
Qiskit HumanEval: An Evaluation Benchmark For Quantum Code Generative Models
Jun 20, 2024Quantum programs are typically developed using quantum Software Development Kits (SDKs). The rapid advancement of quantum computing necessitates new tools to streamline this development process, and one such tool could be Generative Artificial intelligence (GenAI). In this study, we introduce and use the Qiskit HumanEval dataset, a hand-curated collection of tasks designed to benchmark the ability of Large Language Models (LLMs) to produce quantum code using Qiskit - a quantum SDK. This dataset consists of more than 100 quantum computing tasks, each accompanied by a prompt, a canonical solution, a comprehensive test case, and a difficulty scale to evaluate the correctness of the generated solutions. We systematically assess the performance of a set of LLMs against the Qiskit HumanEval dataset's tasks and focus on the models ability in producing executable quantum code. Our findings not only demonstrate the feasibility of using LLMs for generating quantum code but also establish a new benchmark for ongoing advancements in the field and encourage further exploration and development of GenAI-driven tools for quantum code generation.
Qiskit Code Assistant: Training LLMs for generating Quantum Computing Code
May 29, 2024
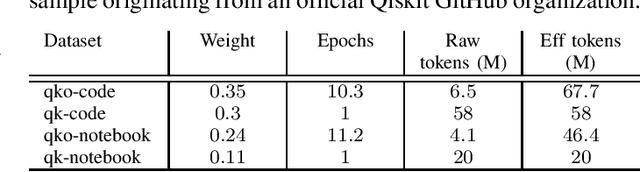
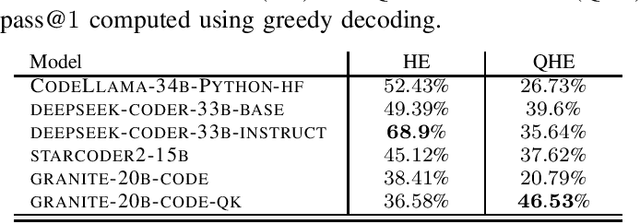
Code Large Language Models (Code LLMs) have emerged as powerful tools, revolutionizing the software development landscape by automating the coding process and reducing time and effort required to build applications. This paper focuses on training Code LLMs to specialize in the field of quantum computing. We begin by discussing the unique needs of quantum computing programming, which differ significantly from classical programming approaches or languages. A Code LLM specializing in quantum computing requires a foundational understanding of quantum computing and quantum information theory. However, the scarcity of available quantum code examples and the rapidly evolving field, which necessitates continuous dataset updates, present significant challenges. Moreover, we discuss our work on training Code LLMs to produce high-quality quantum code using the Qiskit library. This work includes an examination of the various aspects of the LLMs used for training and the specific training conditions, as well as the results obtained with our current models. To evaluate our models, we have developed a custom benchmark, similar to HumanEval, which includes a set of tests specifically designed for the field of quantum computing programming using Qiskit. Our findings indicate that our model outperforms existing state-of-the-art models in quantum computing tasks. We also provide examples of code suggestions, comparing our model to other relevant code LLMs. Finally, we introduce a discussion on the potential benefits of Code LLMs for quantum computing computational scientists, researchers, and practitioners. We also explore various features and future work that could be relevant in this context.
Automated Code generation for Information Technology Tasks in YAML through Large Language Models
May 05, 2023



The recent improvement in code generation capabilities due to the use of large language models has mainly benefited general purpose programming languages. Domain specific languages, such as the ones used for IT Automation, have received far less attention, despite involving many active developers and being an essential component of modern cloud platforms. This work focuses on the generation of Ansible-YAML, a widely used markup language for IT Automation. We present Ansible Wisdom, a natural-language to Ansible-YAML code generation tool, aimed at improving IT automation productivity. Ansible Wisdom is a transformer-based model, extended by training with a new dataset containing Ansible-YAML. We also develop two novel performance metrics for YAML and Ansible to capture the specific characteristics of this domain. Results show that Ansible Wisdom can accurately generate Ansible script from natural language prompts with performance comparable or better than existing state of the art code generation models.