 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeChain-of-Descriptions: Improving Code LLMs for VHDL Code Generation and Summarization
Jul 16, 2025Large Language Models (LLMs) have become widely used across diverse NLP tasks and domains, demonstrating their adaptability and effectiveness. In the realm of Electronic Design Automation (EDA), LLMs show promise for tasks like Register-Transfer Level (RTL) code generation and summarization. However, despite the proliferation of LLMs for general code-related tasks, there's a dearth of research focused on evaluating and refining these models for hardware description languages (HDLs), notably VHDL. In this study, we evaluate the performance of existing code LLMs for VHDL code generation and summarization using various metrics and two datasets -- VHDL-Eval and VHDL-Xform. The latter, an in-house dataset, aims to gauge LLMs' understanding of functionally equivalent code. Our findings reveal consistent underperformance of these models across different metrics, underscoring a significant gap in their suitability for this domain. To address this challenge, we propose Chain-of-Descriptions (CoDes), a novel approach to enhance the performance of LLMs for VHDL code generation and summarization tasks. CoDes involves generating a series of intermediate descriptive steps based on: (i) the problem statement for code generation, and (ii) the VHDL code for summarization. These steps are then integrated with the original input prompt (problem statement or code) and provided as input to the LLMs to generate the final output. Our experiments demonstrate that the CoDes approach significantly surpasses the standard prompting strategy across various metrics on both datasets. This method not only improves the quality of VHDL code generation and summarization but also serves as a framework for future research aimed at enhancing code LLMs for VHDL.
Revisiting Group Relative Policy Optimization: Insights into On-Policy and Off-Policy Training
May 28, 2025We revisit Group Relative Policy Optimization (GRPO) in both on-policy and off-policy optimization regimes. Our motivation comes from recent work on off-policy Proximal Policy Optimization (PPO), which improves training stability, sampling efficiency, and memory usage. In addition, a recent analysis of GRPO suggests that estimating the advantage function with off-policy samples could be beneficial. Building on these observations, we adapt GRPO to the off-policy setting. We show that both on-policy and off-policy GRPO objectives yield an improvement in the reward. This result motivates the use of clipped surrogate objectives in the off-policy version of GRPO. We then compare the empirical performance of reinforcement learning with verifiable rewards in post-training using both GRPO variants. Our results show that off-policy GRPO either significantly outperforms or performs on par with its on-policy counterpart.
Multivariate Stochastic Dominance via Optimal Transport and Applications to Models Benchmarking
Jun 10, 2024Stochastic dominance is an important concept in probability theory, econometrics and social choice theory for robustly modeling agents' preferences between random outcomes. While many works have been dedicated to the univariate case, little has been done in the multivariate scenario, wherein an agent has to decide between different multivariate outcomes. By exploiting a characterization of multivariate first stochastic dominance in terms of couplings, we introduce a statistic that assesses multivariate almost stochastic dominance under the framework of Optimal Transport with a smooth cost. Further, we introduce an entropic regularization of this statistic, and establish a central limit theorem (CLT) and consistency of the bootstrap procedure for the empirical statistic. Armed with this CLT, we propose a hypothesis testing framework as well as an efficient implementation using the Sinkhorn algorithm. We showcase our method in comparing and benchmarking Large Language Models that are evaluated on multiple metrics. Our multivariate stochastic dominance test allows us to capture the dependencies between the metrics in order to make an informed and statistically significant decision on the relative performance of the models.
Distributional Preference Alignment of LLMs via Optimal Transport
Jun 09, 2024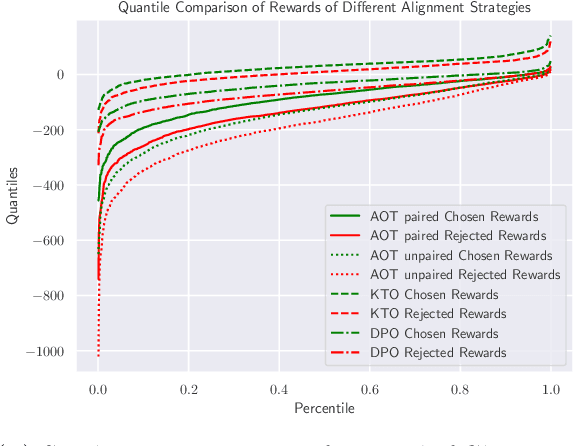
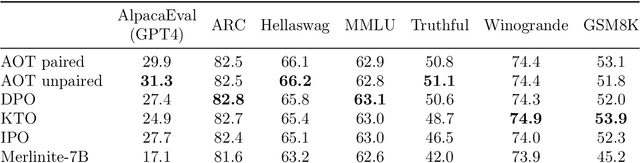
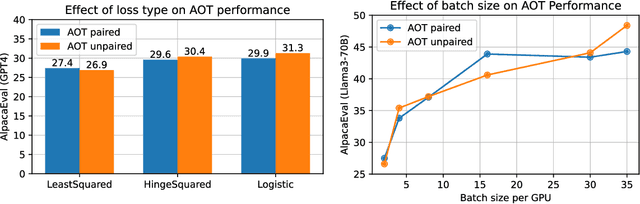

Current LLM alignment techniques use pairwise human preferences at a sample level, and as such, they do not imply an alignment on the distributional level. We propose in this paper Alignment via Optimal Transport (AOT), a novel method for distributional preference alignment of LLMs. AOT aligns LLMs on unpaired preference data by making the reward distribution of the positive samples stochastically dominant in the first order on the distribution of negative samples. We introduce a convex relaxation of this first-order stochastic dominance and cast it as an optimal transport problem with a smooth and convex cost. Thanks to the one-dimensional nature of the resulting optimal transport problem and the convexity of the cost, it has a closed-form solution via sorting on empirical measures. We fine-tune LLMs with this AOT objective, which enables alignment by penalizing the violation of the stochastic dominance of the reward distribution of the positive samples on the reward distribution of the negative samples. We analyze the sample complexity of AOT by considering the dual of the OT problem and show that it converges at the parametric rate. Empirically, we show on a diverse set of alignment datasets and LLMs that AOT leads to state-of-the-art models in the 7B family of models when evaluated with Open LLM Benchmarks and AlpacaEval.
VHDL-Eval: A Framework for Evaluating Large Language Models in VHDL Code Generation
Jun 06, 2024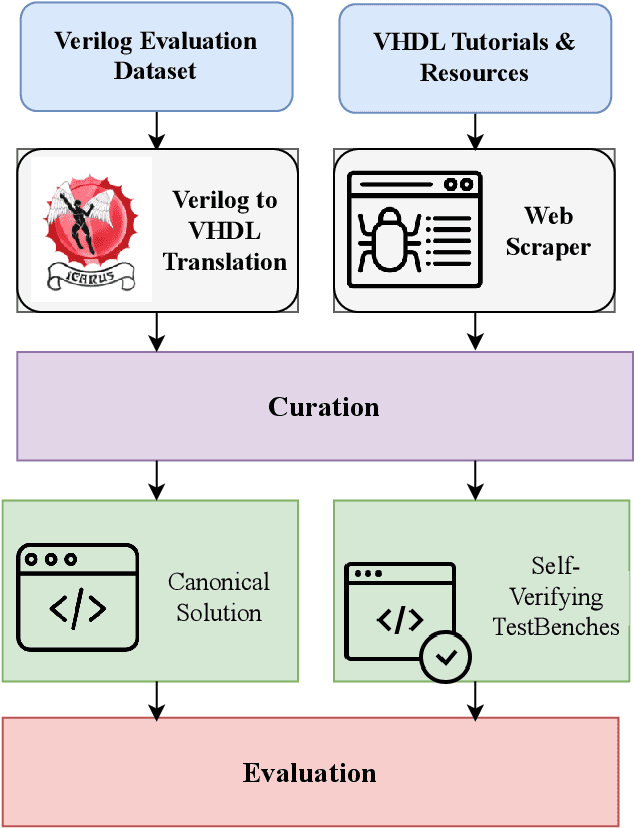


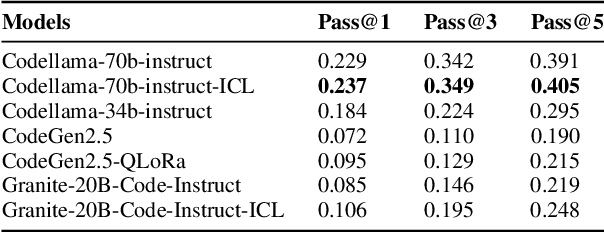
With the unprecedented advancements in Large Language Models (LLMs), their application domains have expanded to include code generation tasks across various programming languages. While significant progress has been made in enhancing LLMs for popular programming languages, there exists a notable gap in comprehensive evaluation frameworks tailored for Hardware Description Languages (HDLs), particularly VHDL. This paper addresses this gap by introducing a comprehensive evaluation framework designed specifically for assessing LLM performance in VHDL code generation task. We construct a dataset for evaluating LLMs on VHDL code generation task. This dataset is constructed by translating a collection of Verilog evaluation problems to VHDL and aggregating publicly available VHDL problems, resulting in a total of 202 problems. To assess the functional correctness of the generated VHDL code, we utilize a curated set of self-verifying testbenches specifically designed for those aggregated VHDL problem set. We conduct an initial evaluation of different LLMs and their variants, including zero-shot code generation, in-context learning (ICL), and Parameter-efficient fine-tuning (PEFT) methods. Our findings underscore the considerable challenges faced by existing LLMs in VHDL code generation, revealing significant scope for improvement. This study emphasizes the necessity of supervised fine-tuning code generation models specifically for VHDL, offering potential benefits to VHDL designers seeking efficient code generation solutions.
Risk Assessment and Statistical Significance in the Age of Foundation Models
Oct 11, 2023



We propose a distributional framework for assessing socio-technical risks of foundation models with quantified statistical significance. Our approach hinges on a new statistical relative testing based on first and second order stochastic dominance of real random variables. We show that the second order statistics in this test are linked to mean-risk models commonly used in econometrics and mathematical finance to balance risk and utility when choosing between alternatives. Using this framework, we formally develop a risk-aware approach for foundation model selection given guardrails quantified by specified metrics. Inspired by portfolio optimization and selection theory in mathematical finance, we define a \emph{metrics portfolio} for each model as a means to aggregate a collection of metrics, and perform model selection based on the stochastic dominance of these portfolios. The statistical significance of our tests is backed theoretically by an asymptotic analysis via central limit theorems instantiated in practice via a bootstrap variance estimate. We use our framework to compare various large language models regarding risks related to drifting from instructions and outputting toxic content.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023



Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
A Scalable Space-efficient In-database Interpretability Framework for Embedding-based Semantic SQL Queries
Mar 01, 2023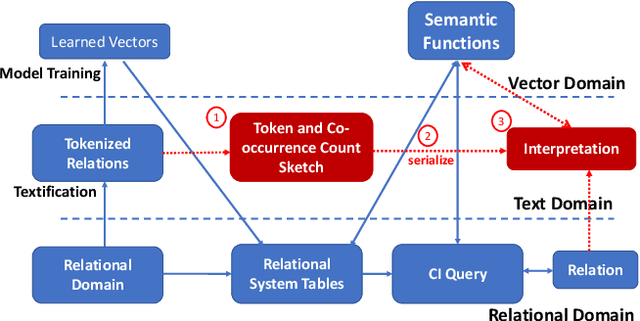
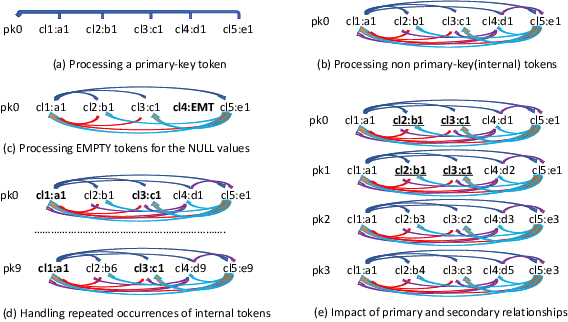
AI-Powered database (AI-DB) is a novel relational database system that uses a self-supervised neural network, database embedding, to enable semantic SQL queries on relational tables. In this paper, we describe an architecture and implementation of in-database interpretability infrastructure designed to provide simple, transparent, and relatable insights into ranked results of semantic SQL queries supported by AI-DB. We introduce a new co-occurrence based interpretability approach to capture relationships between relational entities and describe a space-efficient probabilistic Sketch implementation to store and process co-occurrence counts. Our approach provides both query-agnostic (global) and query-specific (local) interpretabilities. Experimental evaluation demonstrate that our in-database probabilistic approach provides the same interpretability quality as the precise space-inefficient approach, while providing scalable and space efficient runtime behavior (up to 8X space savings), without any user intervention.
Unlocking New York City Crime Insights using Relational Database Embeddings
May 20, 2020
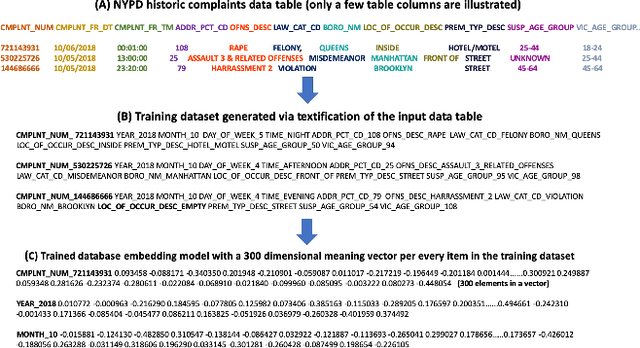


This paper demonstrates the use of the AI-Powered Database (AI-DB) in identifying non-obvious patterns in crime data that could serve as an aid to predictive policing measures. AI-DB uses an unsupervised neural network, db2Vec, to capture inter and intra-column semantic relationships from a relational table and allows users to exploit such relationships using novel semantic SQL queries. Using the publicly available New York Police Department (NYPD) Crime Complaint Dataset as an example, the paper illustrates how AI-DB can be used to interpret the data and generate useful insights. We demonstrate that AI-DB's database embedding model and semantic queries enable users to identify criminal complaint patterns that are not possible to extract using current crime analysis tools, including NYPD's state-of-the-art Patternizr system. We show that the AI-DB system can generate new insights with reduced pre-processing and execution costs (e.g., no labeling, reduced feature engineering, and use of standard SQL queries) with reasonable training performance (i.e., processing and training the 6.5 Million crime complaints in the NYPD Crime Complaint Dataset took less than 4 hours). The SQL-based implementation can be incorporated into any data science pipeline to provide visual representation of the results.