 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeDARE: Towards Robust Text Explanations in Biomedical and Healthcare Applications
Jul 05, 2023
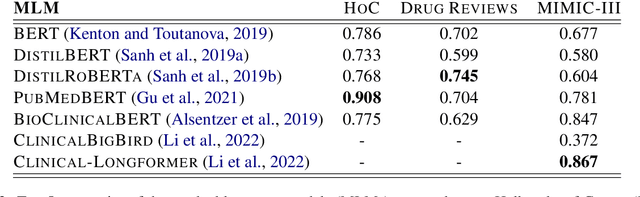
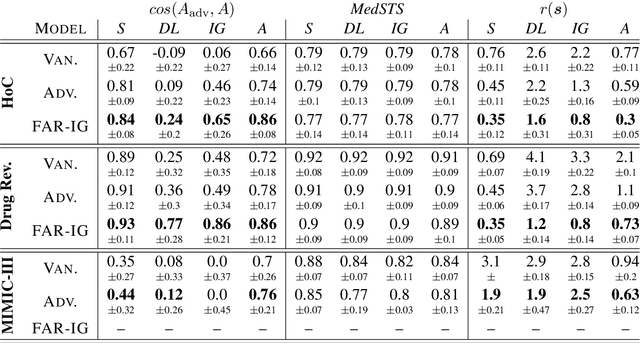

Along with the successful deployment of deep neural networks in several application domains, the need to unravel the black-box nature of these networks has seen a significant increase recently. Several methods have been introduced to provide insight into the inference process of deep neural networks. However, most of these explainability methods have been shown to be brittle in the face of adversarial perturbations of their inputs in the image and generic textual domain. In this work we show that this phenomenon extends to specific and important high stakes domains like biomedical datasets. In particular, we observe that the robustness of explanations should be characterized in terms of the accuracy of the explanation in linking a model's inputs and its decisions - faithfulness - and its relevance from the perspective of domain experts - plausibility. This is crucial to prevent explanations that are inaccurate but still look convincing in the context of the domain at hand. To this end, we show how to adapt current attribution robustness estimation methods to a given domain, so as to take into account domain-specific plausibility. This results in our DomainAdaptiveAREstimator (DARE) attribution robustness estimator, allowing us to properly characterize the domain-specific robustness of faithful explanations. Next, we provide two methods, adversarial training and FAR training, to mitigate the brittleness characterized by DARE, allowing us to train networks that display robust attributions. Finally, we empirically validate our methods with extensive experiments on three established biomedical benchmarks.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023



Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
Estimating the Adversarial Robustness of Attributions in Text with Transformers
Dec 18, 2022



Explanations are crucial parts of deep neural network (DNN) classifiers. In high stakes applications, faithful and robust explanations are important to understand and gain trust in DNN classifiers. However, recent work has shown that state-of-the-art attribution methods in text classifiers are susceptible to imperceptible adversarial perturbations that alter explanations significantly while maintaining the correct prediction outcome. If undetected, this can critically mislead the users of DNNs. Thus, it is crucial to understand the influence of such adversarial perturbations on the networks' explanations and their perceptibility. In this work, we establish a novel definition of attribution robustness (AR) in text classification, based on Lipschitz continuity. Crucially, it reflects both attribution change induced by adversarial input alterations and perceptibility of such alterations. Moreover, we introduce a wide set of text similarity measures to effectively capture locality between two text samples and imperceptibility of adversarial perturbations in text. We then propose our novel TransformerExplanationAttack (TEA), a strong adversary that provides a tight estimation for attribution robustness in text classification. TEA uses state-of-the-art language models to extract word substitutions that result in fluent, contextual adversarial samples. Finally, with experiments on several text classification architectures, we show that TEA consistently outperforms current state-of-the-art AR estimators, yielding perturbations that alter explanations to a greater extent while being more fluent and less perceptible.
Fooling Explanations in Text Classifiers
Jun 07, 2022


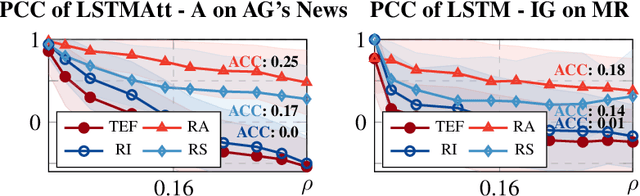
State-of-the-art text classification models are becoming increasingly reliant on deep neural networks (DNNs). Due to their black-box nature, faithful and robust explanation methods need to accompany classifiers for deployment in real-life scenarios. However, it has been shown in vision applications that explanation methods are susceptible to local, imperceptible perturbations that can significantly alter the explanations without changing the predicted classes. We show here that the existence of such perturbations extends to text classifiers as well. Specifically, we introduceTextExplanationFooler (TEF), a novel explanation attack algorithm that alters text input samples imperceptibly so that the outcome of widely-used explanation methods changes considerably while leaving classifier predictions unchanged. We evaluate the performance of the attribution robustness estimation performance in TEF on five sequence classification datasets, utilizing three DNN architectures and three transformer architectures for each dataset. TEF can significantly decrease the correlation between unchanged and perturbed input attributions, which shows that all models and explanation methods are susceptible to TEF perturbations. Moreover, we evaluate how the perturbations transfer to other model architectures and attribution methods, and show that TEF perturbations are also effective in scenarios where the target model and explanation method are unknown. Finally, we introduce a semi-universal attack that is able to compute fast, computationally light perturbations with no knowledge of the attacked classifier nor explanation method. Overall, our work shows that explanations in text classifiers are very fragile and users need to carefully address their robustness before relying on them in critical applications.
Artificial Intelligence Decision Support for Medical Triage
Nov 09, 2020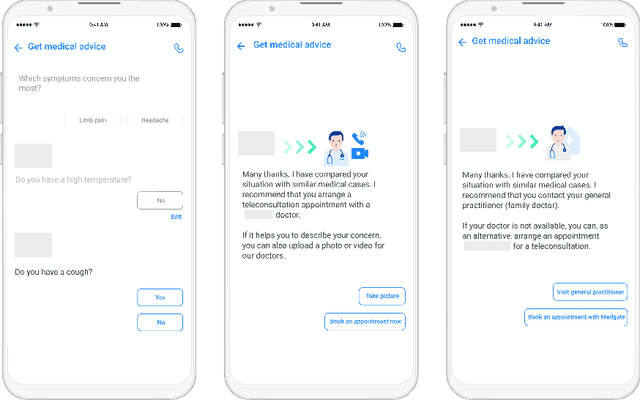
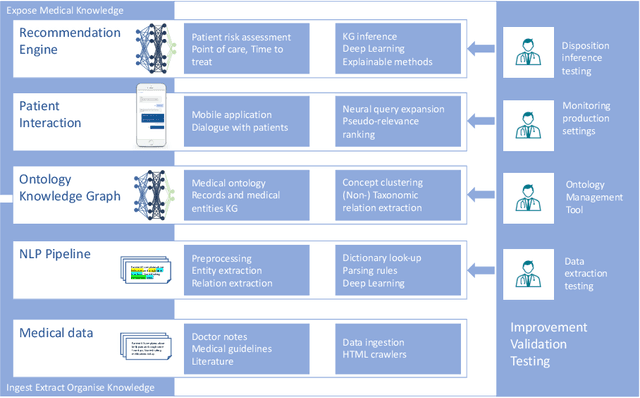
Applying state-of-the-art machine learning and natural language processing on approximately one million of teleconsultation records, we developed a triage system, now certified and in use at the largest European telemedicine provider. The system evaluates care alternatives through interactions with patients via a mobile application. Reasoning on an initial set of provided symptoms, the triage application generates AI-powered, personalized questions to better characterize the problem and recommends the most appropriate point of care and time frame for a consultation. The underlying technology was developed to meet the needs for performance, transparency, user acceptance and ease of use, central aspects to the adoption of AI-based decision support systems. Providing such remote guidance at the beginning of the chain of care has significant potential for improving cost efficiency, patient experience and outcomes. Being remote, always available and highly scalable, this service is fundamental in high demand situations, such as the current COVID-19 outbreak.
FAR: A General Framework for Attributional Robustness
Oct 14, 2020
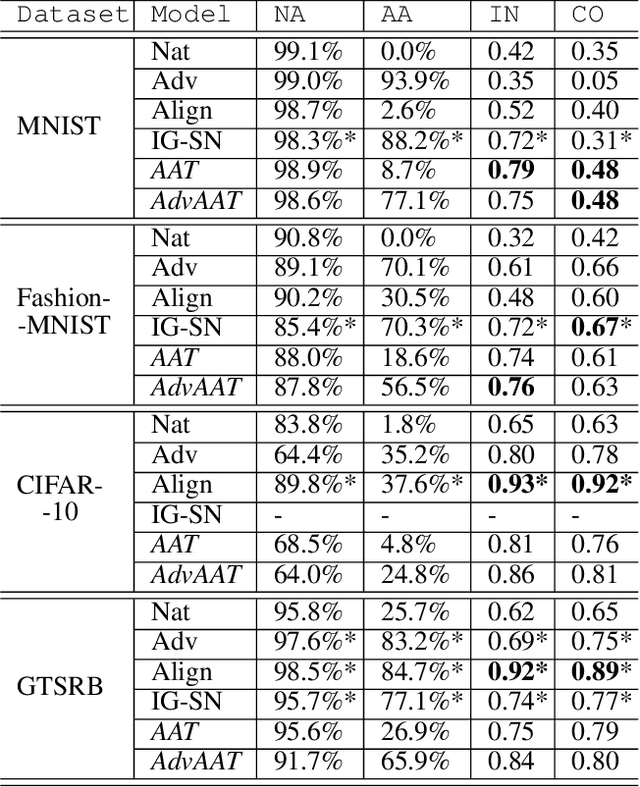
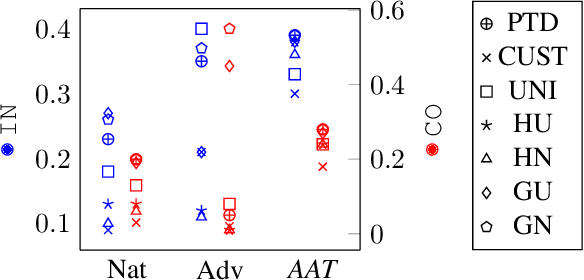
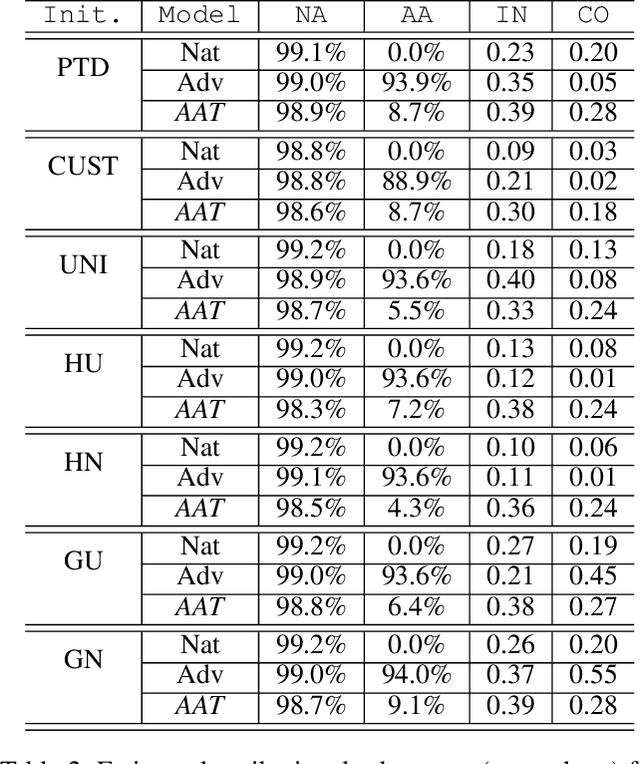
Attribution maps have gained popularity as tools for explaining neural networks predictions. By assigning an importance value to each input dimension that represents their influence towards the outcome, they give an intuitive explanation of the decision process. However, recent work has discovered vulnerability of these maps to imperceptible, carefully crafted changes in the input that lead to significantly different attributions, rendering them meaningless. By borrowing notions of traditional adversarial training - a method to achieve robust predictions - we propose a novel framework for attributional robustness (FAR) to mitigate this vulnerability. Central assumption is that similar inputs should yield similar attribution maps, while keeping the prediction of the network constant. Specifically, we define a new generic regularization term and training objective that minimizes the maximal dissimilarity of attribution maps in a local neighbourhood of the input. We then show how current state-of-the-art methods can be recovered through principled instantiations of these objectives. Moreover, we propose two new training methods, AAT and AdvAAT, derived from the framework, that directly optimize for robust attributions and predictions. We showcase the effectivity of our training methods by comparing them to current state-of-the-art attributional robustness approaches on widely used vision datasets. Experiments show that they perform better or comparably to current methods in terms of attributional robustness, while being applicable to any attribution method and input data domain. We finally show that our methods mitigate undesired dependencies of attributional robustness and some training and estimation parameters, which seem to critically affect other methods.
Patient Risk Assessment and Warning Symptom Detection Using Deep Attention-Based Neural Networks
Sep 28, 2018
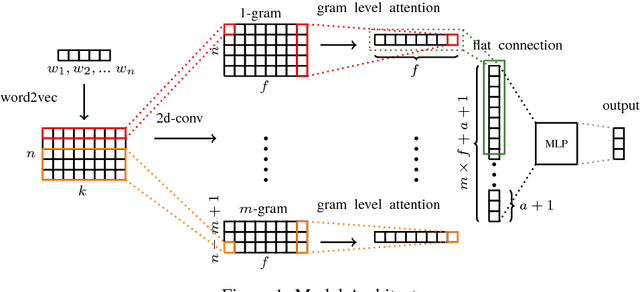


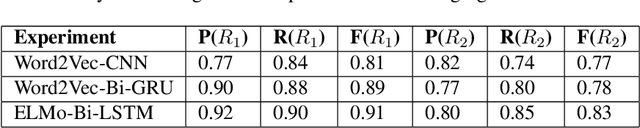
We present an operational component of a real-world patient triage system. Given a specific patient presentation, the system is able to assess the level of medical urgency and issue the most appropriate recommendation in terms of best point of care and time to treat. We use an attention-based convolutional neural network architecture trained on 600,000 doctor notes in German. We compare two approaches, one that uses the full text of the medical notes and one that uses only a selected list of medical entities extracted from the text. These approaches achieve 79% and 66% precision, respectively, but on a confidence threshold of 0.6, precision increases to 85% and 75%, respectively. In addition, a method to detect warning symptoms is implemented to render the classification task transparent from a medical perspective. The method is based on the learning of attention scores and a method of automatic validation using the same data.