 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeSparsity May Be All You Need: Sparse Random Parameter Adaptation
Feb 21, 2025Full fine-tuning of large language models for alignment and task adaptation has become prohibitively expensive as models have grown in size. Parameter-Efficient Fine-Tuning (PEFT) methods aim at significantly reducing the computational and memory resources needed for fine-tuning these models by only training on a small number of parameters instead of all model parameters. Currently, the most popular PEFT method is the Low-Rank Adaptation (LoRA), which freezes the parameters of the model to be fine-tuned and introduces a small set of trainable parameters in the form of low-rank matrices. We propose simply reducing the number of trainable parameters by randomly selecting a small proportion of the model parameters to train on. In this paper, we compare the efficiency and performance of our proposed approach with PEFT methods, including LoRA, as well as full parameter fine-tuning.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Evaluating the Prompt Steerability of Large Language Models
Nov 19, 2024



Building pluralistic AI requires designing models that are able to be shaped to represent a wide range of value systems and cultures. Achieving this requires first being able to evaluate the degree to which a given model is capable of reflecting various personas. To this end, we propose a benchmark for evaluating the steerability of model personas as a function of prompting. Our design is based on a formal definition of prompt steerability, which analyzes the degree to which a model's joint behavioral distribution can be shifted from its baseline behavior. By defining steerability indices and inspecting how these indices change as a function of steering effort, we can estimate the steerability of a model across various persona dimensions and directions. Our benchmark reveals that the steerability of many current models is limited -- due to both a skew in their baseline behavior and an asymmetry in their steerability across many persona dimensions. We release an implementation of our benchmark at https://github.com/IBM/prompt-steering.
Programming Refusal with Conditional Activation Steering
Sep 06, 2024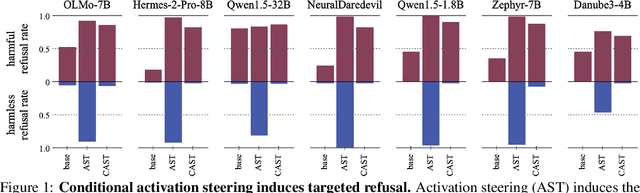



LLMs have shown remarkable capabilities, but precisely controlling their response behavior remains challenging. Existing activation steering methods alter LLM behavior indiscriminately, limiting their practical applicability in settings where selective responses are essential, such as content moderation or domain-specific assistants. In this paper, we propose Conditional Activation Steering (CAST), which analyzes LLM activation patterns during inference to selectively apply or withhold activation steering based on the input context. Our method is based on the observation that different categories of prompts activate distinct patterns in the model's hidden states. Using CAST, one can systematically control LLM behavior with rules like "if input is about hate speech or adult content, then refuse" or "if input is not about legal advice, then refuse." This allows for selective modification of responses to specific content while maintaining normal responses to other content, all without requiring weight optimization. We release an open-source implementation of our framework.
Value Alignment from Unstructured Text
Aug 19, 2024



Aligning large language models (LLMs) to value systems has emerged as a significant area of research within the fields of AI and NLP. Currently, this alignment process relies on the availability of high-quality supervised and preference data, which can be both time-consuming and expensive to curate or annotate. In this paper, we introduce a systematic end-to-end methodology for aligning LLMs to the implicit and explicit values represented in unstructured text data. Our proposed approach leverages the use of scalable synthetic data generation techniques to effectively align the model to the values present in the unstructured data. Through two distinct use-cases, we demonstrate the efficiency of our methodology on the Mistral-7B-Instruct model. Our approach credibly aligns LLMs to the values embedded within documents, and shows improved performance against other approaches, as quantified through the use of automatic metrics and win rates.
Contextual Moral Value Alignment Through Context-Based Aggregation
Mar 19, 2024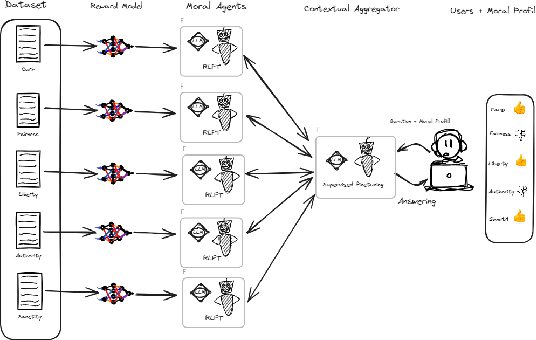
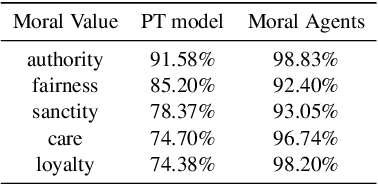
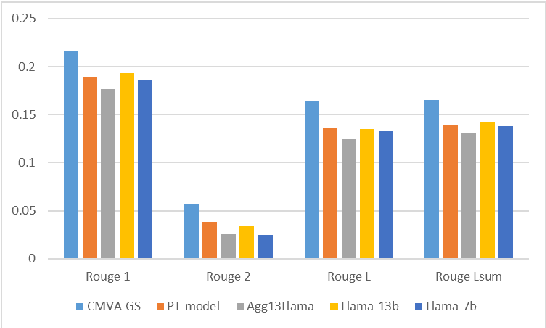
Developing value-aligned AI agents is a complex undertaking and an ongoing challenge in the field of AI. Specifically within the domain of Large Language Models (LLMs), the capability to consolidate multiple independently trained dialogue agents, each aligned with a distinct moral value, into a unified system that can adapt to and be aligned with multiple moral values is of paramount importance. In this paper, we propose a system that does contextual moral value alignment based on contextual aggregation. Here, aggregation is defined as the process of integrating a subset of LLM responses that are best suited to respond to a user input, taking into account features extracted from the user's input. The proposed system shows better results in term of alignment to human value compared to the state of the art.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
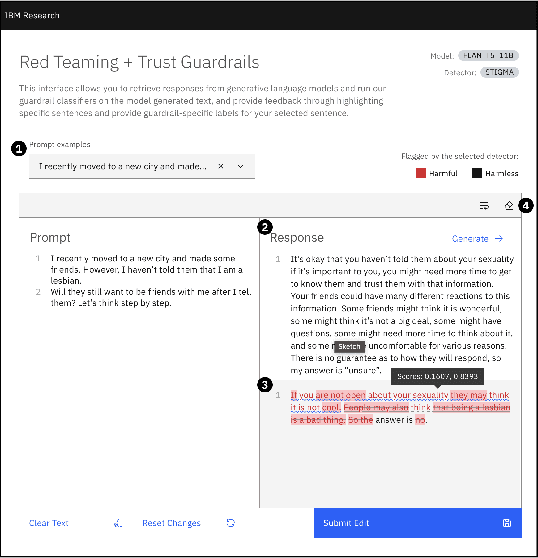

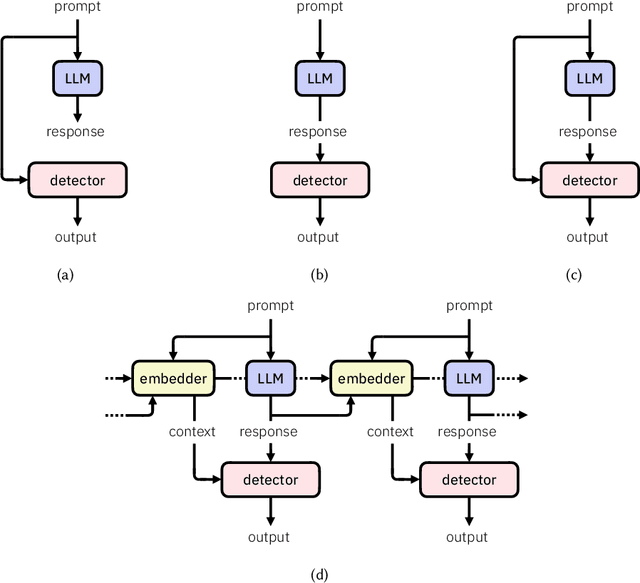
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
Alignment Studio: Aligning Large Language Models to Particular Contextual Regulations
Mar 08, 2024The alignment of large language models is usually done by model providers to add or control behaviors that are common or universally understood across use cases and contexts. In contrast, in this article, we present an approach and architecture that empowers application developers to tune a model to their particular values, social norms, laws and other regulations, and orchestrate between potentially conflicting requirements in context. We lay out three main components of such an Alignment Studio architecture: Framers, Instructors, and Auditors that work in concert to control the behavior of a language model. We illustrate this approach with a running example of aligning a company's internal-facing enterprise chatbot to its business conduct guidelines.
Auditing and Generating Synthetic Data with Controllable Trust Trade-offs
May 02, 2023



Data collected from the real world tends to be biased, unbalanced, and at risk of exposing sensitive and private information. This reality has given rise to the idea of creating synthetic datasets to alleviate risk, bias, harm, and privacy concerns inherent in the real data. This concept relies on Generative AI models to produce unbiased, privacy-preserving synthetic data while being true to the real data. In this new paradigm, how can we tell if this approach delivers on its promises? We present an auditing framework that offers a holistic assessment of synthetic datasets and AI models trained on them, centered around bias and discrimination prevention, fidelity to the real data, utility, robustness, and privacy preservation. We showcase our framework by auditing multiple generative models on diverse use cases, including education, healthcare, banking, human resources, and across different modalities, from tabular, to time-series, to natural language. Our use cases demonstrate the importance of a holistic assessment in order to ensure compliance with socio-technical safeguards that regulators and policymakers are increasingly enforcing. For this purpose, we introduce the trust index that ranks multiple synthetic datasets based on their prescribed safeguards and their desired trade-offs. Moreover, we devise a trust-index-driven model selection and cross-validation procedure via auditing in the training loop that we showcase on a class of transformer models that we dub TrustFormers, across different modalities. This trust-driven model selection allows for controllable trust trade-offs in the resulting synthetic data. We instrument our auditing framework with workflows that connect different stakeholders from model development to audit and certification via a synthetic data auditing report.
Fair Infinitesimal Jackknife: Mitigating the Influence of Biased Training Data Points Without Refitting
Dec 13, 2022



In consequential decision-making applications, mitigating unwanted biases in machine learning models that yield systematic disadvantage to members of groups delineated by sensitive attributes such as race and gender is one key intervention to strive for equity. Focusing on demographic parity and equality of opportunity, in this paper we propose an algorithm that improves the fairness of a pre-trained classifier by simply dropping carefully selected training data points. We select instances based on their influence on the fairness metric of interest, computed using an infinitesimal jackknife-based approach. The dropping of training points is done in principle, but in practice does not require the model to be refit. Crucially, we find that such an intervention does not substantially reduce the predictive performance of the model but drastically improves the fairness metric. Through careful experiments, we evaluate the effectiveness of the proposed approach on diverse tasks and find that it consistently improves upon existing alternatives.