 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAI Steerability 360: A Toolkit for Steering Large Language Models
Mar 08, 2026The AI Steerability 360 toolkit is an extensible, open-source Python library for steering LLMs. Steering abstractions are designed around four model control surfaces: input (modification of the prompt), structural (modification of the model's weights or architecture), state (modification of the model's activations and attentions), and output (modification of the decoding or generation process). Steering methods exert control on the model through a common interface, termed a steering pipeline, which additionally allows for the composition of multiple steering methods. Comprehensive evaluation and comparison of steering methods/pipelines is facilitated by use case classes (for defining tasks) and a benchmark class (for performance comparison on a given task). The functionality provided by the toolkit significantly lowers the barrier to developing and comprehensively evaluating steering methods. The toolkit is Hugging Face native and is released under an Apache 2.0 license at https://github.com/IBM/AISteer360.
CoFrGeNet: Continued Fraction Architectures for Language Generation
Jan 29, 2026Transformers are arguably the preferred architecture for language generation. In this paper, inspired by continued fractions, we introduce a new function class for generative modeling. The architecture family implementing this function class is named CoFrGeNets - Continued Fraction Generative Networks. We design novel architectural components based on this function class that can replace Multi-head Attention and Feed-Forward Networks in Transformer blocks while requiring much fewer parameters. We derive custom gradient formulations to optimize the proposed components more accurately and efficiently than using standard PyTorch-based gradients. Our components are a plug-in replacement requiring little change in training or inference procedures that have already been put in place for Transformer-based models thus making our approach easy to incorporate in large industrial workflows. We experiment on two very different transformer architectures GPT2-xl (1.5B) and Llama3 (3.2B), where the former we pre-train on OpenWebText and GneissWeb, while the latter we pre-train on the docling data mix which consists of nine different datasets. Results show that the performance on downstream classification, Q\& A, reasoning and text understanding tasks of our models is competitive and sometimes even superior to the original models with $\frac{2}{3}$ to $\frac{1}{2}$ the parameters and shorter pre-training time. We believe that future implementations customized to hardware will further bring out the true potential of our architectures.
CoFrNets: Interpretable Neural Architecture Inspired by Continued Fractions
Jun 05, 2025In recent years there has been a considerable amount of research on local post hoc explanations for neural networks. However, work on building interpretable neural architectures has been relatively sparse. In this paper, we present a novel neural architecture, CoFrNet, inspired by the form of continued fractions which are known to have many attractive properties in number theory, such as fast convergence of approximations to real numbers. We show that CoFrNets can be efficiently trained as well as interpreted leveraging their particular functional form. Moreover, we prove that such architectures are universal approximators based on a proof strategy that is different than the typical strategy used to prove universal approximation results for neural networks based on infinite width (or depth), which is likely to be of independent interest. We experiment on nonlinear synthetic functions and are able to accurately model as well as estimate feature attributions and even higher order terms in some cases, which is a testament to the representational power as well as interpretability of such architectures. To further showcase the power of CoFrNets, we experiment on seven real datasets spanning tabular, text and image modalities, and show that they are either comparable or significantly better than other interpretable models and multilayer perceptrons, sometimes approaching the accuracies of state-of-the-art models.
EpMAN: Episodic Memory AttentioN for Generalizing to Longer Contexts
Feb 20, 2025



Recent advances in Large Language Models (LLMs) have yielded impressive successes on many language tasks. However, efficient processing of long contexts using LLMs remains a significant challenge. We introduce \textbf{EpMAN} -- a method for processing long contexts in an \textit{episodic memory} module while \textit{holistically attending to} semantically relevant context chunks. The output of \textit{episodic attention} is then used to reweigh the decoder's self-attention to the stored KV cache of the context during training and generation. When an LLM decoder is trained using \textbf{EpMAN}, its performance on multiple challenging single-hop long-context recall and question-answering benchmarks is found to be stronger and more robust across the range from 16k to 256k tokens than baseline decoders trained with self-attention, and popular retrieval-augmented generation frameworks.
Modular Prompt Learning Improves Vision-Language Models
Feb 19, 2025Pre-trained vision-language models are able to interpret visual concepts and language semantics. Prompt learning, a method of constructing prompts for text encoders or image encoders, elicits the potentials of pre-trained models and readily adapts them to new scenarios. Compared to fine-tuning, prompt learning enables the model to achieve comparable or better performance using fewer trainable parameters. Besides, prompt learning freezes the pre-trained model and avoids the catastrophic forgetting issue in the fine-tuning. Continuous prompts inserted into the input of every transformer layer (i.e. deep prompts) can improve the performances of pre-trained models on downstream tasks. For i-th transformer layer, the inserted prompts replace previously inserted prompts in the $(i-1)$-th layer. Although the self-attention mechanism contextualizes newly inserted prompts for the current layer and embeddings from the previous layer's output, removing all inserted prompts from the previous layer inevitably loses information contained in the continuous prompts. In this work, we propose Modular Prompt Learning (MPL) that is designed to promote the preservation of information contained in the inserted prompts. We evaluate the proposed method on base-to-new generalization and cross-dataset tasks. On average of 11 datasets, our method achieves 0.7% performance gain on the base-to-new generalization task compared to the state-of-the-art method. The largest improvement on the individual dataset is 10.7% (EuroSAT dataset).
Differentiable Prompt Learning for Vision Language Models
Dec 31, 2024



Prompt learning is an effective way to exploit the potential of large-scale pre-trained foundational models. Continuous prompts parameterize context tokens in prompts by turning them into differentiable vectors. Deep continuous prompts insert prompts not only in the input but also in the intermediate hidden representations. Manually designed deep continuous prompts exhibit a remarkable improvement compared to the zero-shot pre-trained model on downstream tasks. How to automate the continuous prompt design is an underexplored area, and a fundamental question arises, is manually designed deep prompt strategy optimal? To answer this question, we propose a method dubbed differentiable prompt learning (DPL). The DPL method is formulated as an optimization problem to automatically determine the optimal context length of the prompt to be added to each layer, where the objective is to maximize the performance. We test the DPL method on the pre-trained CLIP. We empirically find that by using only limited data, our DPL method can find deep continuous prompt configuration with high confidence. The performance on the downstream tasks exhibits the superiority of the automatic design: our method boosts the average test accuracy by 2.60% on 11 datasets compared to baseline methods. Besides, our method focuses only on the prompt configuration (i.e. context length for each layer), which means that our method is compatible with the baseline methods that have sophisticated designs to boost the performance. The DPL method can be deployed to large language models or computer vision models at no cost.
Granite Guardian
Dec 10, 2024



We introduce the Granite Guardian models, a suite of safeguards designed to provide risk detection for prompts and responses, enabling safe and responsible use in combination with any large language model (LLM). These models offer comprehensive coverage across multiple risk dimensions, including social bias, profanity, violence, sexual content, unethical behavior, jailbreaking, and hallucination-related risks such as context relevance, groundedness, and answer relevance for retrieval-augmented generation (RAG). Trained on a unique dataset combining human annotations from diverse sources and synthetic data, Granite Guardian models address risks typically overlooked by traditional risk detection models, such as jailbreaks and RAG-specific issues. With AUC scores of 0.871 and 0.854 on harmful content and RAG-hallucination-related benchmarks respectively, Granite Guardian is the most generalizable and competitive model available in the space. Released as open-source, Granite Guardian aims to promote responsible AI development across the community. https://github.com/ibm-granite/granite-guardian
Large Language Models can be Strong Self-Detoxifiers
Oct 04, 2024Reducing the likelihood of generating harmful and toxic output is an essential task when aligning large language models (LLMs). Existing methods mainly rely on training an external reward model (i.e., another language model) or fine-tuning the LLM using self-generated data to influence the outcome. In this paper, we show that LLMs have the capability of self-detoxification without the use of an additional reward model or re-training. We propose \textit{Self-disciplined Autoregressive Sampling (SASA)}, a lightweight controlled decoding algorithm for toxicity reduction of LLMs. SASA leverages the contextual representations from an LLM to learn linear subspaces characterizing toxic v.s. non-toxic output in analytical forms. When auto-completing a response token-by-token, SASA dynamically tracks the margin of the current output to steer the generation away from the toxic subspace, by adjusting the autoregressive sampling strategy. Evaluated on LLMs of different scale and nature, namely Llama-3.1-Instruct (8B), Llama-2 (7B), and GPT2-L models with the RealToxicityPrompts, BOLD, and AttaQ benchmarks, SASA markedly enhances the quality of the generated sentences relative to the original models and attains comparable performance to state-of-the-art detoxification techniques, significantly reducing the toxicity level by only using the LLM's internal representations.
TabSketchFM: Sketch-based Tabular Representation Learning for Data Discovery over Data Lakes
Jun 28, 2024



Enterprises have a growing need to identify relevant tables in data lakes; e.g. tables that are unionable, joinable, or subsets of each other. Tabular neural models can be helpful for such data discovery tasks. In this paper, we present TabSketchFM, a neural tabular model for data discovery over data lakes. First, we propose a novel pre-training sketch-based approach to enhance the effectiveness of data discovery techniques in neural tabular models. Second, to further finetune the pretrained model for several downstream tasks, we develop LakeBench, a collection of 8 benchmarks to help with different data discovery tasks such as finding tasks that are unionable, joinable, or subsets of each other. We then show on these finetuning tasks that TabSketchFM achieves state-of-the art performance compared to existing neural models. Third, we use these finetuned models to search for tables that are unionable, joinable, or can be subsets of each other. Our results demonstrate improvements in F1 scores for search compared to state-of-the-art techniques (even up to 70% improvement in a joinable search benchmark). Finally, we show significant transfer across datasets and tasks establishing that our model can generalize across different tasks over different data lakes
Large Language Model Confidence Estimation via Black-Box Access
Jun 01, 2024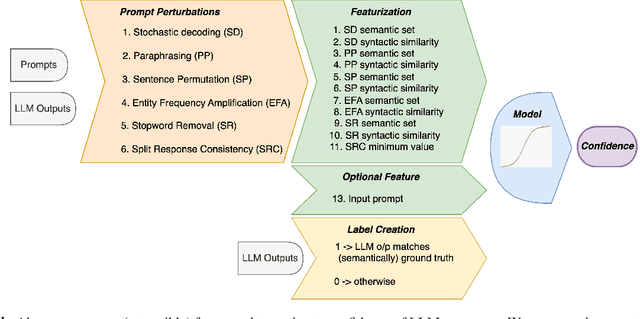
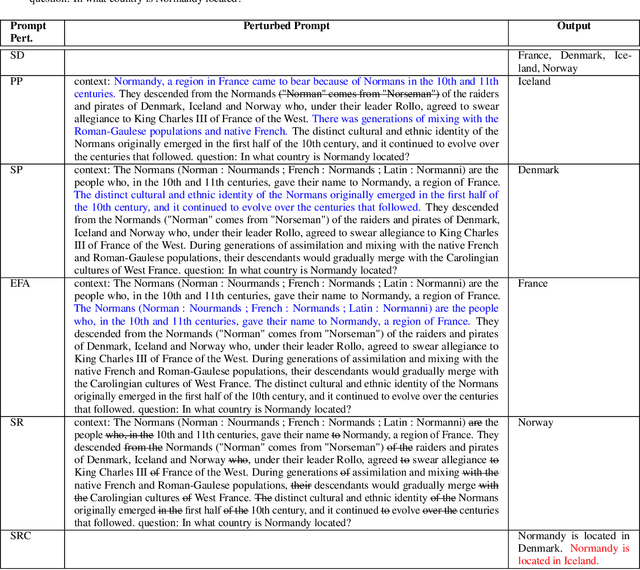
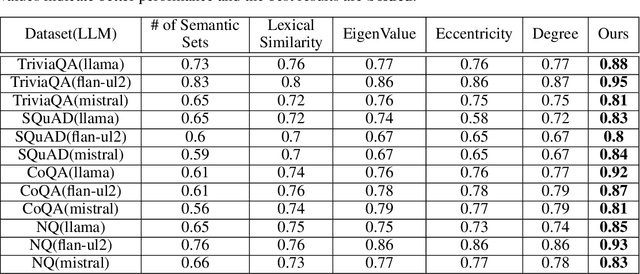
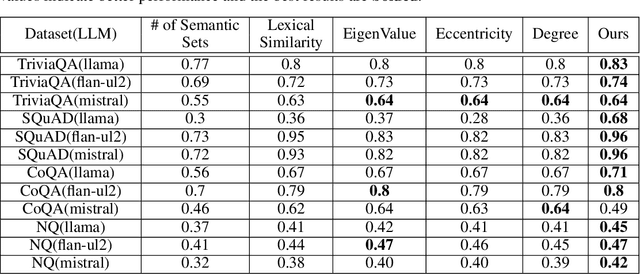
Estimating uncertainty or confidence in the responses of a model can be significant in evaluating trust not only in the responses, but also in the model as a whole. In this paper, we explore the problem of estimating confidence for responses of large language models (LLMs) with simply black-box or query access to them. We propose a simple and extensible framework where, we engineer novel features and train a (interpretable) model (viz. logistic regression) on these features to estimate the confidence. We empirically demonstrate that our simple framework is effective in estimating confidence of flan-ul2, llama-13b and mistral-7b with it consistently outperforming existing black-box confidence estimation approaches on benchmark datasets such as TriviaQA, SQuAD, CoQA and Natural Questions by even over $10\%$ (on AUROC) in some cases. Additionally, our interpretable approach provides insight into features that are predictive of confidence, leading to the interesting and useful discovery that our confidence models built for one LLM generalize zero-shot across others on a given dataset.