 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeEpMAN: Episodic Memory AttentioN for Generalizing to Longer Contexts
Feb 20, 2025



Recent advances in Large Language Models (LLMs) have yielded impressive successes on many language tasks. However, efficient processing of long contexts using LLMs remains a significant challenge. We introduce \textbf{EpMAN} -- a method for processing long contexts in an \textit{episodic memory} module while \textit{holistically attending to} semantically relevant context chunks. The output of \textit{episodic attention} is then used to reweigh the decoder's self-attention to the stored KV cache of the context during training and generation. When an LLM decoder is trained using \textbf{EpMAN}, its performance on multiple challenging single-hop long-context recall and question-answering benchmarks is found to be stronger and more robust across the range from 16k to 256k tokens than baseline decoders trained with self-attention, and popular retrieval-augmented generation frameworks.
Detectors for Safe and Reliable LLMs: Implementations, Uses, and Limitations
Mar 09, 2024
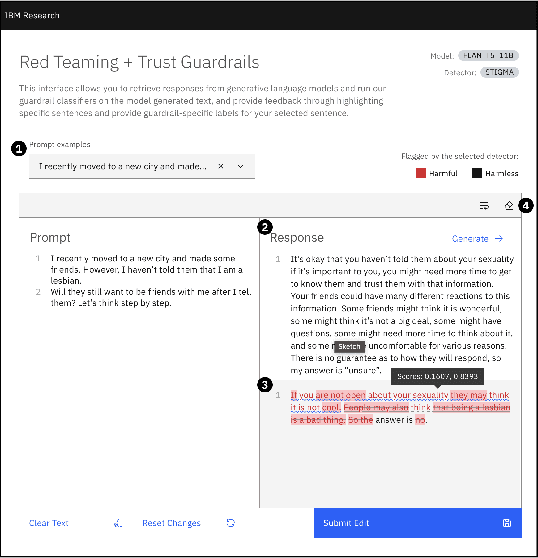

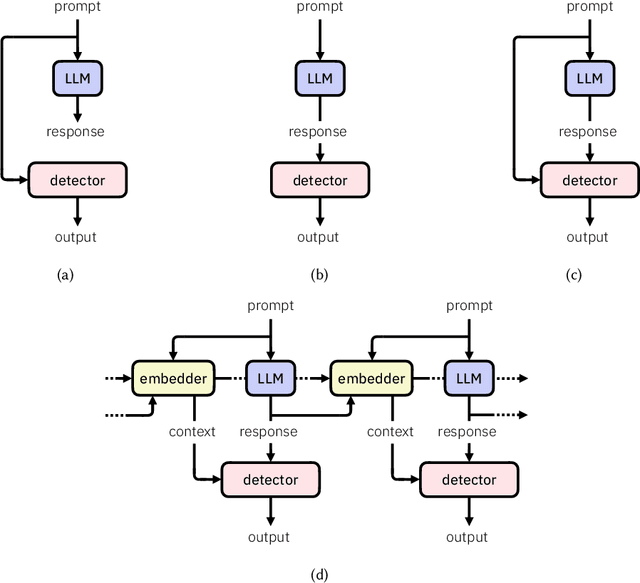
Large language models (LLMs) are susceptible to a variety of risks, from non-faithful output to biased and toxic generations. Due to several limiting factors surrounding LLMs (training cost, API access, data availability, etc.), it may not always be feasible to impose direct safety constraints on a deployed model. Therefore, an efficient and reliable alternative is required. To this end, we present our ongoing efforts to create and deploy a library of detectors: compact and easy-to-build classification models that provide labels for various harms. In addition to the detectors themselves, we discuss a wide range of uses for these detector models - from acting as guardrails to enabling effective AI governance. We also deep dive into inherent challenges in their development and discuss future work aimed at making the detectors more reliable and broadening their scope.
A Neuro-Symbolic Approach to Multi-Agent RL for Interpretability and Probabilistic Decision Making
Feb 21, 2024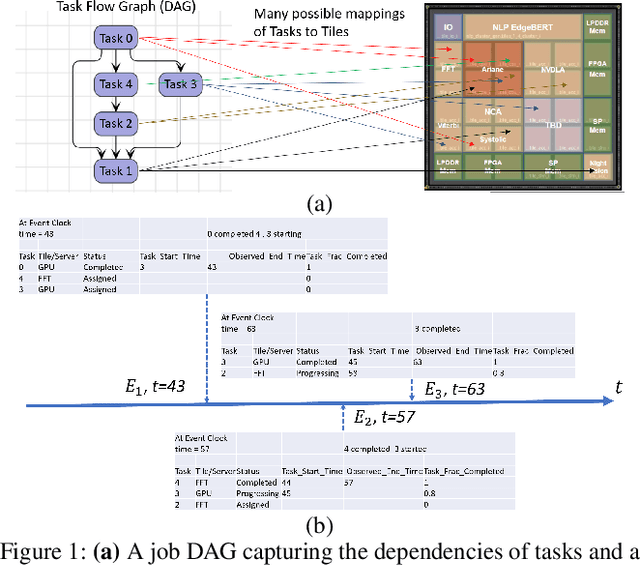
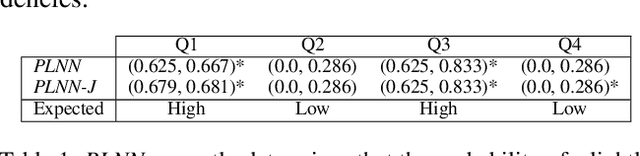

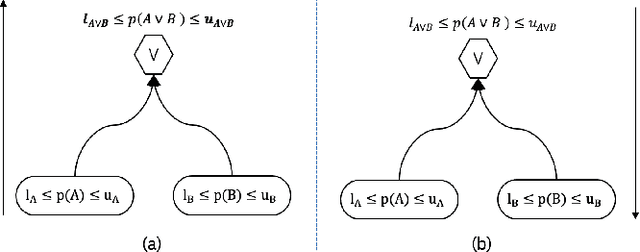
Multi-agent reinforcement learning (MARL) is well-suited for runtime decision-making in optimizing the performance of systems where multiple agents coexist and compete for shared resources. However, applying common deep learning-based MARL solutions to real-world problems suffers from issues of interpretability, sample efficiency, partial observability, etc. To address these challenges, we present an event-driven formulation, where decision-making is handled by distributed co-operative MARL agents using neuro-symbolic methods. The recently introduced neuro-symbolic Logical Neural Networks (LNN) framework serves as a function approximator for the RL, to train a rules-based policy that is both logical and interpretable by construction. To enable decision-making under uncertainty and partial observability, we developed a novel probabilistic neuro-symbolic framework, Probabilistic Logical Neural Networks (PLNN), which combines the capabilities of logical reasoning with probabilistic graphical models. In PLNN, the upward/downward inference strategy, inherited from LNN, is coupled with belief bounds by setting the activation function for the logical operator associated with each neural network node to a probability-respecting generalization of the Fr\'echet inequalities. These PLNN nodes form the unifying element that combines probabilistic logic and Bayes Nets, permitting inference for variables with unobserved states. We demonstrate our contributions by addressing key MARL challenges for power sharing in a system-on-chip application.
Learning Symbolic Rules over Abstract Meaning Representations for Textual Reinforcement Learning
Jul 05, 2023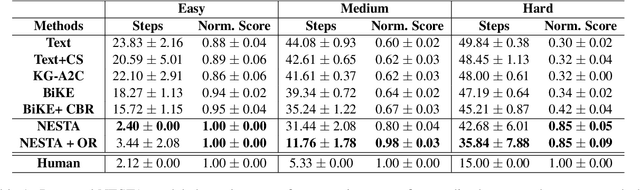
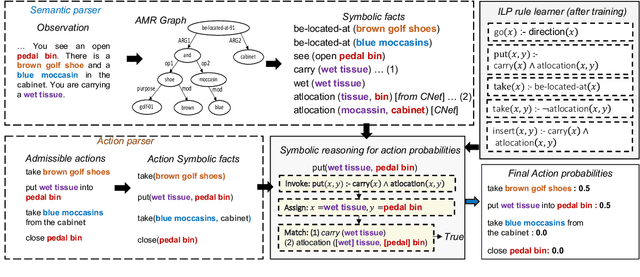
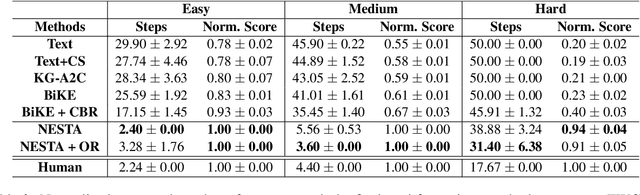
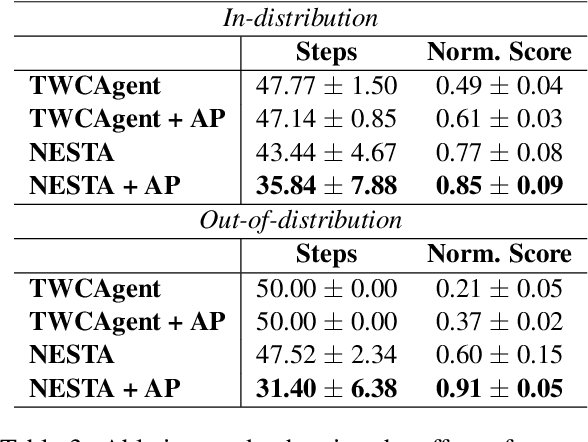
Text-based reinforcement learning agents have predominantly been neural network-based models with embeddings-based representation, learning uninterpretable policies that often do not generalize well to unseen games. On the other hand, neuro-symbolic methods, specifically those that leverage an intermediate formal representation, are gaining significant attention in language understanding tasks. This is because of their advantages ranging from inherent interpretability, the lesser requirement of training data, and being generalizable in scenarios with unseen data. Therefore, in this paper, we propose a modular, NEuro-Symbolic Textual Agent (NESTA) that combines a generic semantic parser with a rule induction system to learn abstract interpretable rules as policies. Our experiments on established text-based game benchmarks show that the proposed NESTA method outperforms deep reinforcement learning-based techniques by achieving better generalization to unseen test games and learning from fewer training interactions.
MISMATCH: Fine-grained Evaluation of Machine-generated Text with Mismatch Error Types
Jun 18, 2023



With the growing interest in large language models, the need for evaluating the quality of machine text compared to reference (typically human-generated) text has become focal attention. Most recent works focus either on task-specific evaluation metrics or study the properties of machine-generated text captured by the existing metrics. In this work, we propose a new evaluation scheme to model human judgments in 7 NLP tasks, based on the fine-grained mismatches between a pair of texts. Inspired by the recent efforts in several NLP tasks for fine-grained evaluation, we introduce a set of 13 mismatch error types such as spatial/geographic errors, entity errors, etc, to guide the model for better prediction of human judgments. We propose a neural framework for evaluating machine texts that uses these mismatch error types as auxiliary tasks and re-purposes the existing single-number evaluation metrics as additional scalar features, in addition to textual features extracted from the machine and reference texts. Our experiments reveal key insights about the existing metrics via the mismatch errors. We show that the mismatch errors between the sentence pairs on the held-out datasets from 7 NLP tasks align well with the human evaluation.
A Unified View of Localized Kernel Learning
Mar 04, 2016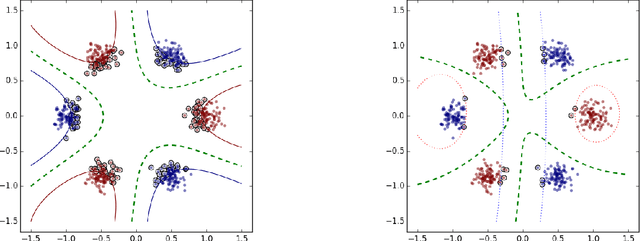
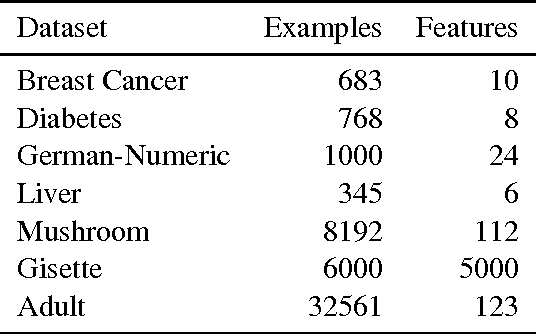
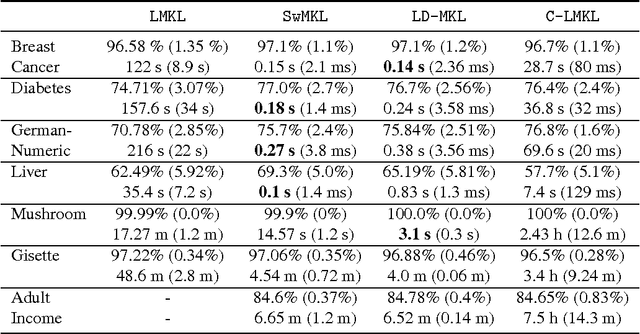
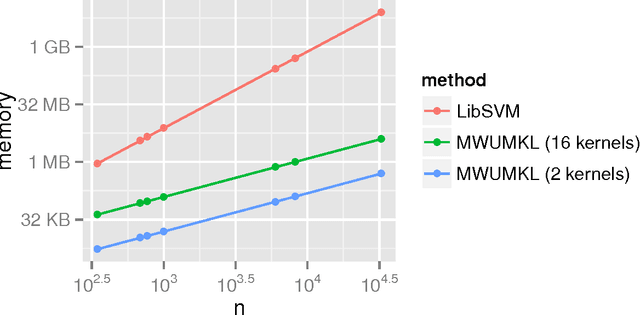
Multiple Kernel Learning, or MKL, extends (kernelized) SVM by attempting to learn not only a classifier/regressor but also the best kernel for the training task, usually from a combination of existing kernel functions. Most MKL methods seek the combined kernel that performs best over every training example, sacrificing performance in some areas to seek a global optimum. Localized kernel learning (LKL) overcomes this limitation by allowing the training algorithm to match a component kernel to the examples that can exploit it best. Several approaches to the localized kernel learning problem have been explored in the last several years. We unify many of these approaches under one simple system and design a new algorithm with improved performance. We also develop enhanced versions of existing algorithms, with an eye on scalability and performance.