 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeMatching of Descriptive Labels to Glossary Descriptions
Oct 27, 2023



Semantic text similarity plays an important role in software engineering tasks in which engineers are requested to clarify the semantics of descriptive labels (e.g., business terms, table column names) that are often consists of too short or too generic words and appears in their IT systems. We formulate this type of problem as a task of matching descriptive labels to glossary descriptions. We then propose a framework to leverage an existing semantic text similarity measurement (STS) and augment it using semantic label enrichment and set-based collective contextualization where the former is a method to retrieve sentences relevant to a given label and the latter is a method to compute similarity between two contexts each of which is derived from a set of texts (e.g., column names in the same table). We performed an experiment on two datasets derived from publicly available data sources. The result indicated that the proposed methods helped the underlying STS correctly match more descriptive labels with the descriptions.
Learning Symbolic Rules over Abstract Meaning Representations for Textual Reinforcement Learning
Jul 05, 2023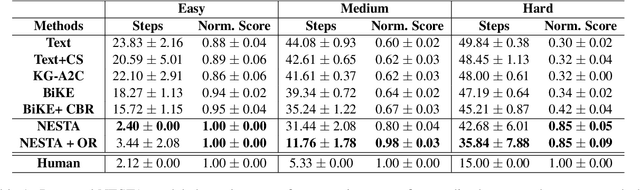
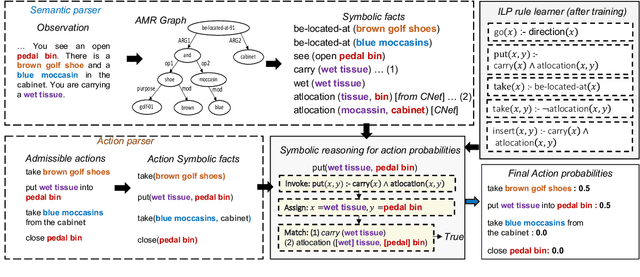
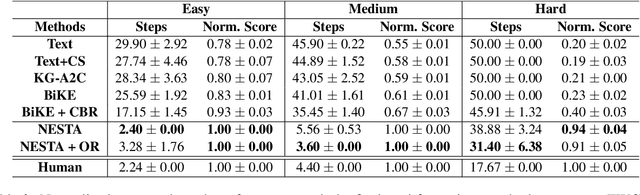
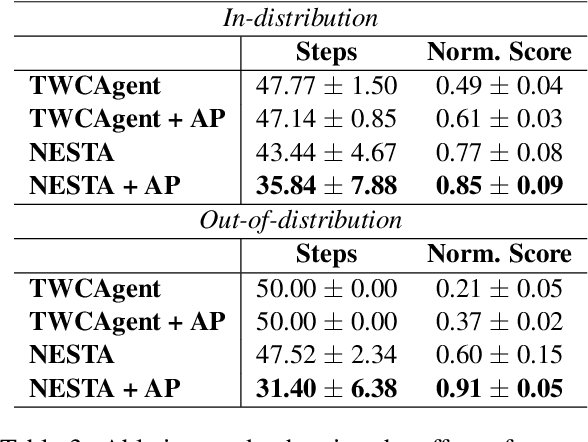
Text-based reinforcement learning agents have predominantly been neural network-based models with embeddings-based representation, learning uninterpretable policies that often do not generalize well to unseen games. On the other hand, neuro-symbolic methods, specifically those that leverage an intermediate formal representation, are gaining significant attention in language understanding tasks. This is because of their advantages ranging from inherent interpretability, the lesser requirement of training data, and being generalizable in scenarios with unseen data. Therefore, in this paper, we propose a modular, NEuro-Symbolic Textual Agent (NESTA) that combines a generic semantic parser with a rule induction system to learn abstract interpretable rules as policies. Our experiments on established text-based game benchmarks show that the proposed NESTA method outperforms deep reinforcement learning-based techniques by achieving better generalization to unseen test games and learning from fewer training interactions.
Utterance Classification with Logical Neural Network: Explainable AI for Mental Disorder Diagnosis
Jun 06, 2023In response to the global challenge of mental health problems, we proposes a Logical Neural Network (LNN) based Neuro-Symbolic AI method for the diagnosis of mental disorders. Due to the lack of effective therapy coverage for mental disorders, there is a need for an AI solution that can assist therapists with the diagnosis. However, current Neural Network models lack explainability and may not be trusted by therapists. The LNN is a Recurrent Neural Network architecture that combines the learning capabilities of neural networks with the reasoning capabilities of classical logic-based AI. The proposed system uses input predicates from clinical interviews to output a mental disorder class, and different predicate pruning techniques are used to achieve scalability and higher scores. In addition, we provide an insight extraction method to aid therapists with their diagnosis. The proposed system addresses the lack of explainability of current Neural Network models and provides a more trustworthy solution for mental disorder diagnosis.
DiffG-RL: Leveraging Difference between State and Common Sense
Nov 29, 2022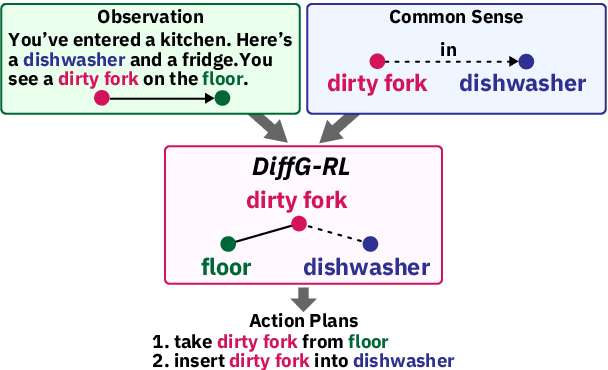
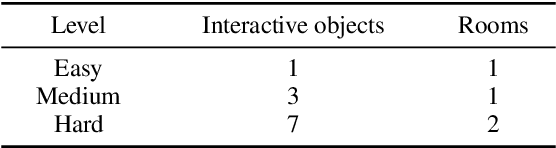
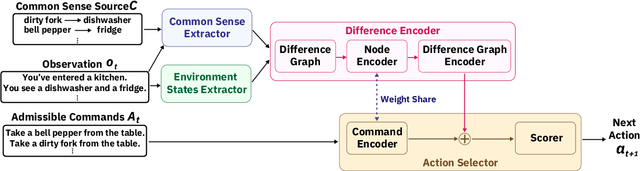
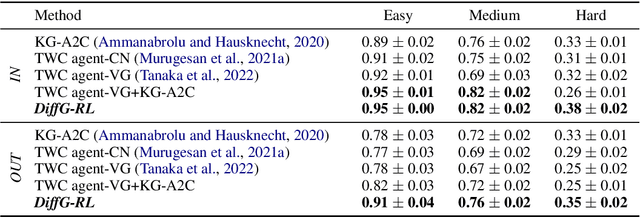
Taking into account background knowledge as the context has always been an important part of solving tasks that involve natural language. One representative example of such tasks is text-based games, where players need to make decisions based on both description text previously shown in the game, and their own background knowledge about the language and common sense. In this work, we investigate not simply giving common sense, as can be seen in prior research, but also its effective usage. We assume that a part of the environment states different from common sense should constitute one of the grounds for action selection. We propose a novel agent, DiffG-RL, which constructs a Difference Graph that organizes the environment states and common sense by means of interactive objects with a dedicated graph encoder. DiffG-RL also contains a framework for extracting the appropriate amount and representation of common sense from the source to support the construction of the graph. We validate DiffG-RL in experiments with text-based games that require common sense and show that it outperforms baselines by 17% of scores. The code is available at https://github.com/ibm/diffg-rl
Deep Temporal Interpolation of Radar-based Precipitation
Mar 01, 2022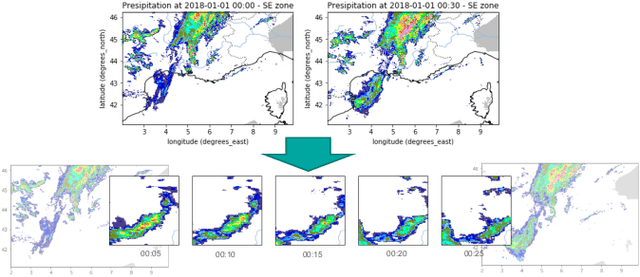
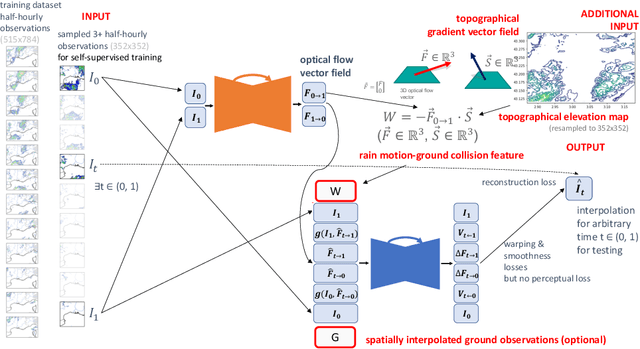
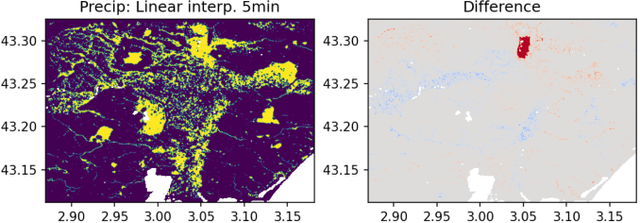
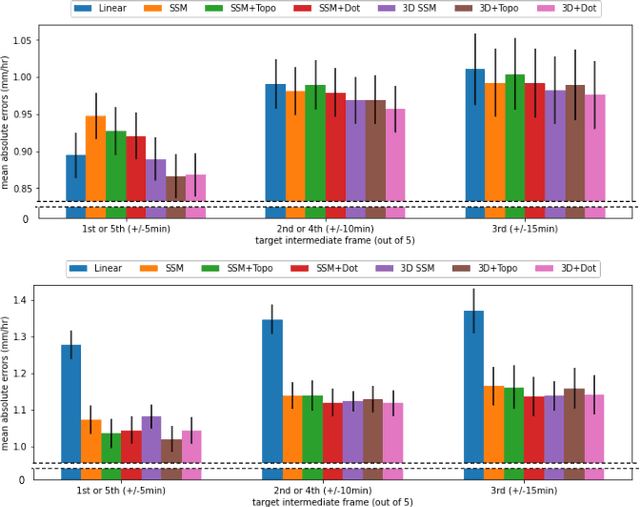
When providing the boundary conditions for hydrological flood models and estimating the associated risk, interpolating precipitation at very high temporal resolutions (e.g. 5 minutes) is essential not to miss the cause of flooding in local regions. In this paper, we study optical flow-based interpolation of globally available weather radar images from satellites. The proposed approach uses deep neural networks for the interpolation of multiple video frames, while terrain information is combined with temporarily coarse-grained precipitation radar observation as inputs for self-supervised training. An experiment with the Meteonet radar precipitation dataset for the flood risk simulation in Aude, a department in Southern France (2018), demonstrated the advantage of the proposed method over a linear interpolation baseline, with up to 20% error reduction.
LOA: Logical Optimal Actions for Text-based Interaction Games
Oct 21, 2021
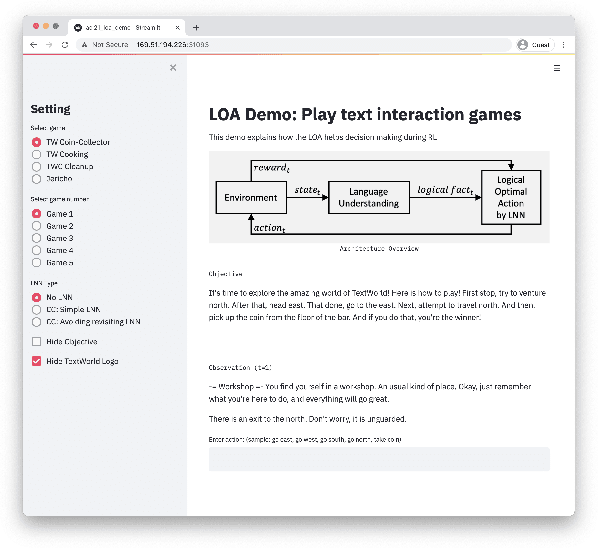
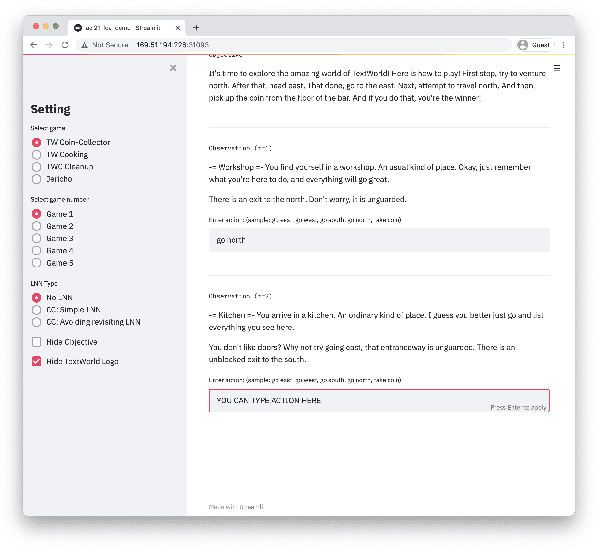
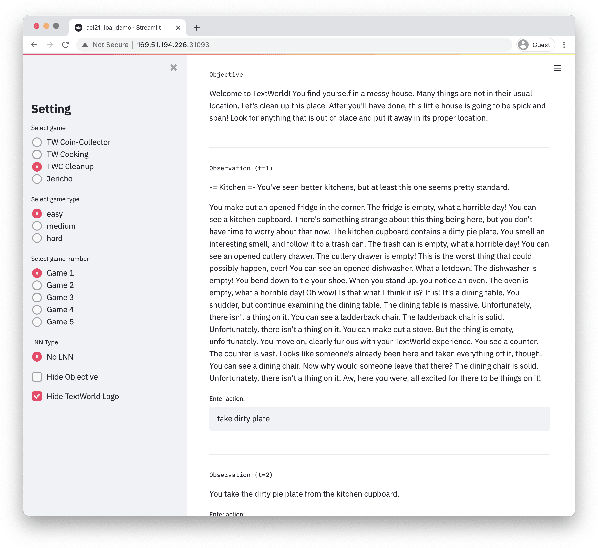
We present Logical Optimal Actions (LOA), an action decision architecture of reinforcement learning applications with a neuro-symbolic framework which is a combination of neural network and symbolic knowledge acquisition approach for natural language interaction games. The demonstration for LOA experiments consists of a web-based interactive platform for text-based games and visualization for acquired knowledge for improving interpretability for trained rules. This demonstration also provides a comparison module with other neuro-symbolic approaches as well as non-symbolic state-of-the-art agent models on the same text-based games. Our LOA also provides open-sourced implementation in Python for the reinforcement learning environment to facilitate an experiment for studying neuro-symbolic agents. Code: https://github.com/ibm/loa
Neuro-Symbolic Reinforcement Learning with First-Order Logic
Oct 21, 2021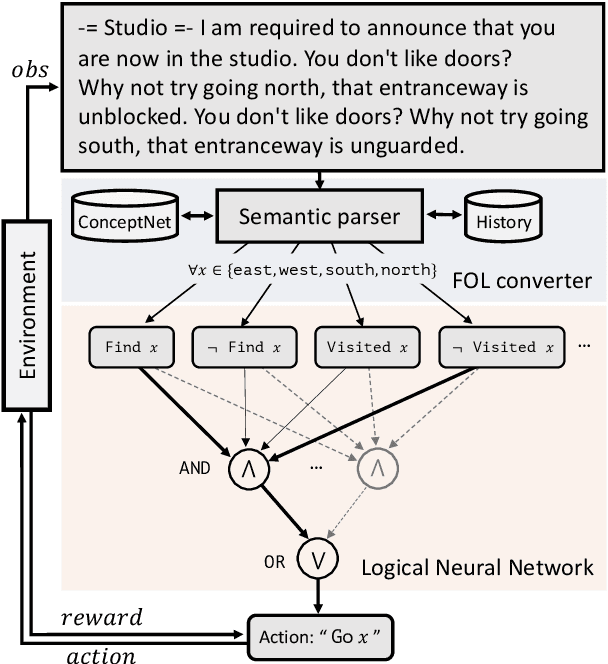
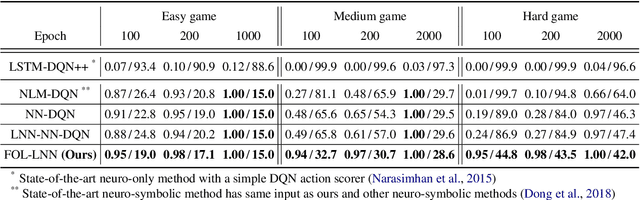
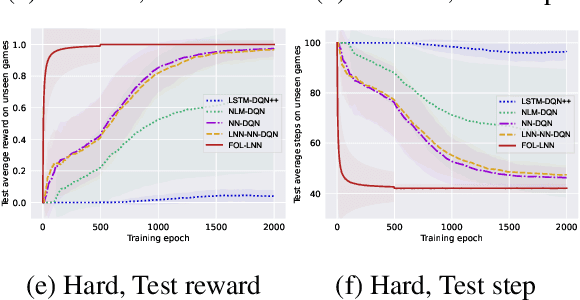
Deep reinforcement learning (RL) methods often require many trials before convergence, and no direct interpretability of trained policies is provided. In order to achieve fast convergence and interpretability for the policy in RL, we propose a novel RL method for text-based games with a recent neuro-symbolic framework called Logical Neural Network, which can learn symbolic and interpretable rules in their differentiable network. The method is first to extract first-order logical facts from text observation and external word meaning network (ConceptNet), then train a policy in the network with directly interpretable logical operators. Our experimental results show RL training with the proposed method converges significantly faster than other state-of-the-art neuro-symbolic methods in a TextWorld benchmark.
Online Adaptation of Parameters using GRU-based Neural Network with BO for Accurate Driving Model
Sep 24, 2021



Testing self-driving cars in different areas requires surrounding cars with accordingly different driving styles such as aggressive or conservative styles. A method of numerically measuring and differentiating human driving styles to create a virtual driver with a certain driving style is in demand. However, most methods for measuring human driving styles require thresholds or labels to classify the driving styles, and some require additional questionnaires for drivers about their driving attitude. These limitations are not suitable for creating a large virtual testing environment. Driving models (DMs) simulate human driving styles. Calibrating a DM makes the simulated driving behavior closer to human-driving behavior, and enable the simulation of human-driving cars. Conventional DM-calibrating methods do not take into account that the parameters in a DM vary while driving. These "fixed" calibrating methods cannot reflect an actual interactive driving scenario. In this paper, we propose a DM-calibration method for measuring human driving styles to reproduce real car-following behavior more accurately. The method includes 1) an objective entropy weight method for measuring and clustering human driving styles, and 2) online adaption of DM parameters based on deep learning by combining Bayesian optimization (BO) and a gated recurrent unit neural network. We conducted experiments to evaluate the proposed method, and the results indicate that it can be easily used to measure human driver styles. The experiments also showed that we can calibrate a corresponding DM in a virtual testing environment with up to 26% more accuracy than with fixed calibration methods.
Reinforcement Learning with External Knowledge by using Logical Neural Networks
Mar 03, 2021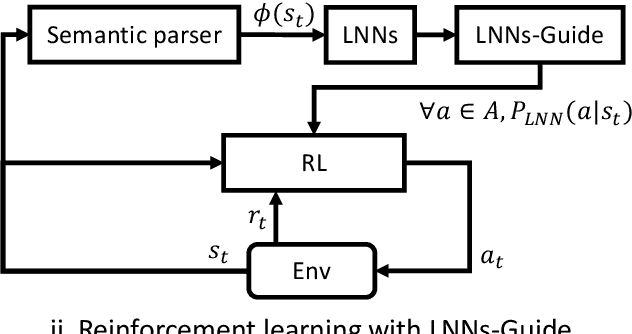
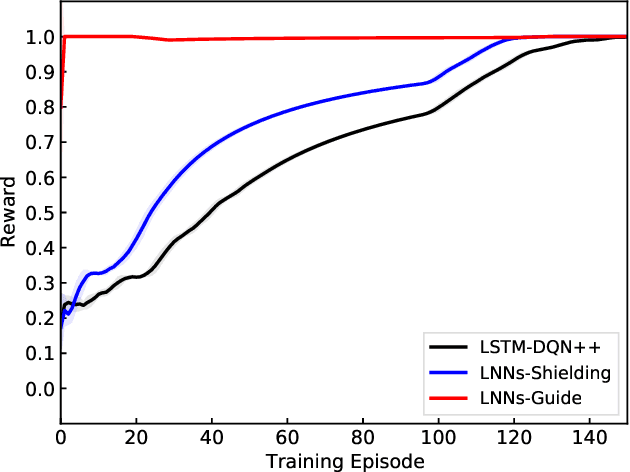
Conventional deep reinforcement learning methods are sample-inefficient and usually require a large number of training trials before convergence. Since such methods operate on an unconstrained action set, they can lead to useless actions. A recent neuro-symbolic framework called the Logical Neural Networks (LNNs) can simultaneously provide key-properties of both neural networks and symbolic logic. The LNNs functions as an end-to-end differentiable network that minimizes a novel contradiction loss to learn interpretable rules. In this paper, we utilize LNNs to define an inference graph using basic logical operations, such as AND and NOT, for faster convergence in reinforcement learning. Specifically, we propose an integrated method that enables model-free reinforcement learning from external knowledge sources in an LNNs-based logical constrained framework such as action shielding and guide. Our results empirically demonstrate that our method converges faster compared to a model-free reinforcement learning method that doesn't have such logical constraints.
VisualHints: A Visual-Lingual Environment for Multimodal Reinforcement Learning
Oct 26, 2020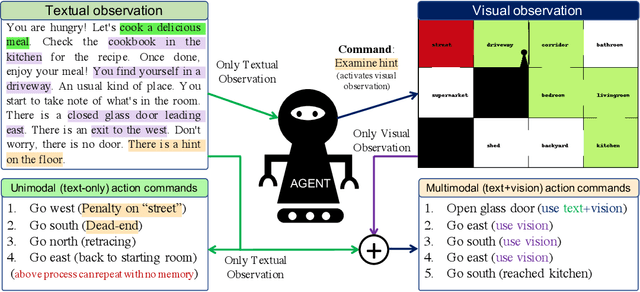
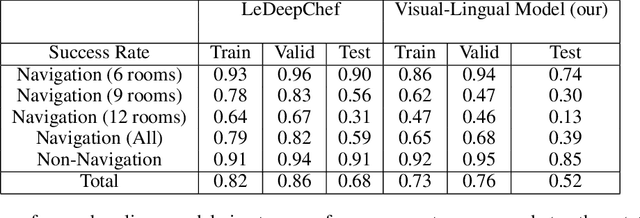
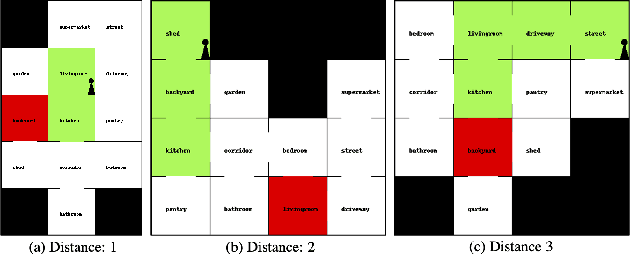

We present VisualHints, a novel environment for multimodal reinforcement learning (RL) involving text-based interactions along with visual hints (obtained from the environment). Real-life problems often demand that agents interact with the environment using both natural language information and visual perception towards solving a goal. However, most traditional RL environments either solve pure vision-based tasks like Atari games or video-based robotic manipulation; or entirely use natural language as a mode of interaction, like Text-based games and dialog systems. In this work, we aim to bridge this gap and unify these two approaches in a single environment for multimodal RL. We introduce an extension of the TextWorld cooking environment with the addition of visual clues interspersed throughout the environment. The goal is to force an RL agent to use both text and visual features to predict natural language action commands for solving the final task of cooking a meal. We enable variations and difficulties in our environment to emulate various interactive real-world scenarios. We present a baseline multimodal agent for solving such problems using CNN-based feature extraction from visual hints and LSTMs for textual feature extraction. We believe that our proposed visual-lingual environment will facilitate novel problem settings for the RL community.