 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFine-tuning of Geospatial Foundation Models for Aboveground Biomass Estimation
Jun 28, 2024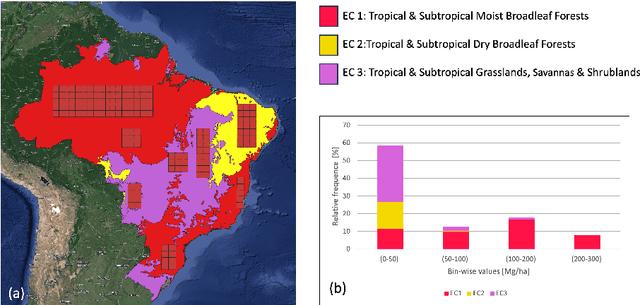

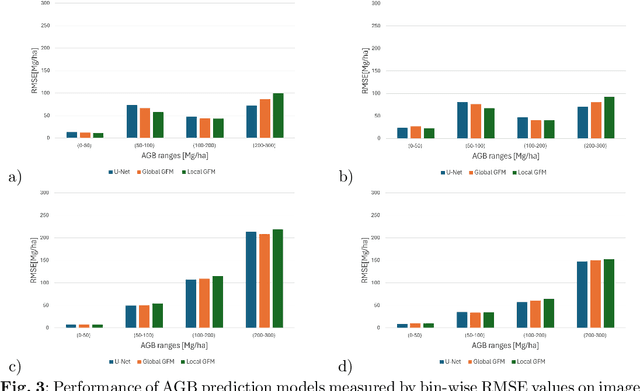
Global vegetation structure mapping is critical for understanding the global carbon cycle and maximizing the efficacy of nature-based carbon sequestration initiatives. Moreover, vegetation structure mapping can help reduce the impacts of climate change by, for example, guiding actions to improve water security, increase biodiversity and reduce flood risk. Global satellite measurements provide an important set of observations for monitoring and managing deforestation and degradation of existing forests, natural forest regeneration, reforestation, biodiversity restoration, and the implementation of sustainable agricultural practices. In this paper, we explore the effectiveness of fine-tuning of a geospatial foundation model to estimate above-ground biomass (AGB) using space-borne data collected across different eco-regions in Brazil. The fine-tuned model architecture consisted of a Swin-B transformer as the encoder (i.e., backbone) and a single convolutional layer for the decoder head. All results were compared to a U-Net which was trained as the baseline model Experimental results of this sparse-label prediction task demonstrate that the fine-tuned geospatial foundation model with a frozen encoder has comparable performance to a U-Net trained from scratch. This is despite the fine-tuned model having 13 times less parameters requiring optimization, which saves both time and compute resources. Further, we explore the transfer-learning capabilities of the geospatial foundation models by fine-tuning on satellite imagery with sparse labels from different eco-regions in Brazil.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
TensorBank:Tensor Lakehouse for Foundation Model Training
Sep 07, 2023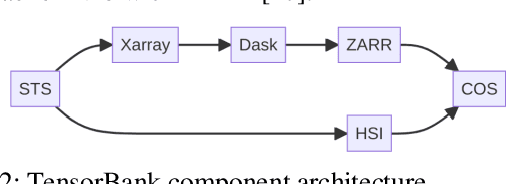
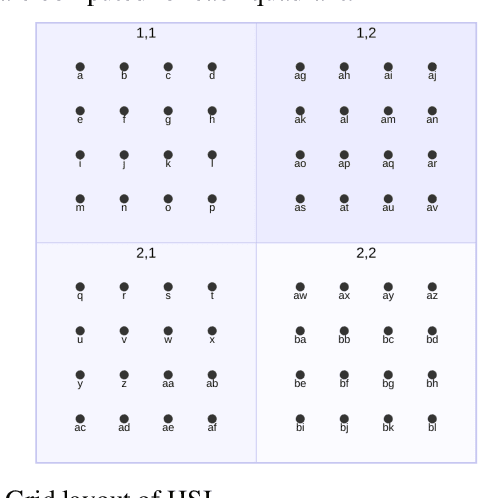
Storing and streaming high dimensional data for foundation model training became a critical requirement with the rise of foundation models beyond natural language. In this paper we introduce TensorBank, a petabyte scale tensor lakehouse capable of streaming tensors from Cloud Object Store (COS) to GPU memory at wire speed based on complex relational queries. We use Hierarchical Statistical Indices (HSI) for query acceleration. Our architecture allows to directly address tensors on block level using HTTP range reads. Once in GPU memory, data can be transformed using PyTorch transforms. We provide a generic PyTorch dataset type with a corresponding dataset factory translating relational queries and requested transformations as an instance. By making use of the HSI, irrelevant blocks can be skipped without reading them as those indices contain statistics on their content at different hierarchical resolution levels. This is an opinionated architecture powered by open standards and making heavy use of open-source technology. Although, hardened for production use using geospatial-temporal data, this architecture generalizes to other use case like computer vision, computational neuroscience, biological sequence analysis and more.
Learning Symbolic Rules over Abstract Meaning Representations for Textual Reinforcement Learning
Jul 05, 2023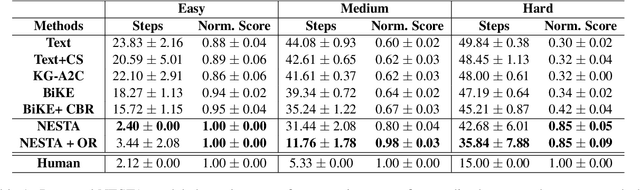
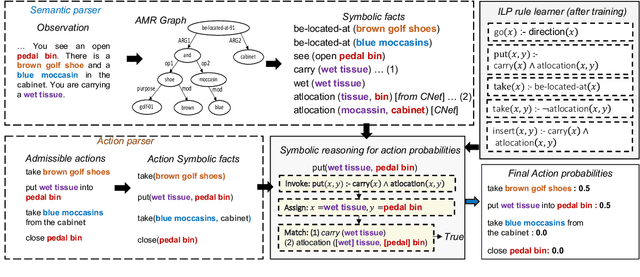
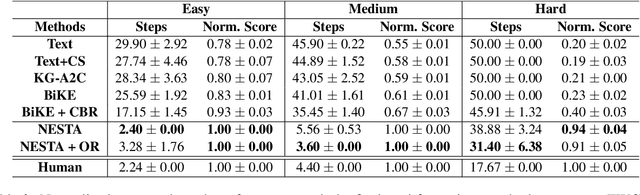
Text-based reinforcement learning agents have predominantly been neural network-based models with embeddings-based representation, learning uninterpretable policies that often do not generalize well to unseen games. On the other hand, neuro-symbolic methods, specifically those that leverage an intermediate formal representation, are gaining significant attention in language understanding tasks. This is because of their advantages ranging from inherent interpretability, the lesser requirement of training data, and being generalizable in scenarios with unseen data. Therefore, in this paper, we propose a modular, NEuro-Symbolic Textual Agent (NESTA) that combines a generic semantic parser with a rule induction system to learn abstract interpretable rules as policies. Our experiments on established text-based game benchmarks show that the proposed NESTA method outperforms deep reinforcement learning-based techniques by achieving better generalization to unseen test games and learning from fewer training interactions.
Utterance Classification with Logical Neural Network: Explainable AI for Mental Disorder Diagnosis
Jun 06, 2023In response to the global challenge of mental health problems, we proposes a Logical Neural Network (LNN) based Neuro-Symbolic AI method for the diagnosis of mental disorders. Due to the lack of effective therapy coverage for mental disorders, there is a need for an AI solution that can assist therapists with the diagnosis. However, current Neural Network models lack explainability and may not be trusted by therapists. The LNN is a Recurrent Neural Network architecture that combines the learning capabilities of neural networks with the reasoning capabilities of classical logic-based AI. The proposed system uses input predicates from clinical interviews to output a mental disorder class, and different predicate pruning techniques are used to achieve scalability and higher scores. In addition, we provide an insight extraction method to aid therapists with their diagnosis. The proposed system addresses the lack of explainability of current Neural Network models and provides a more trustworthy solution for mental disorder diagnosis.
DiffG-RL: Leveraging Difference between State and Common Sense
Nov 29, 2022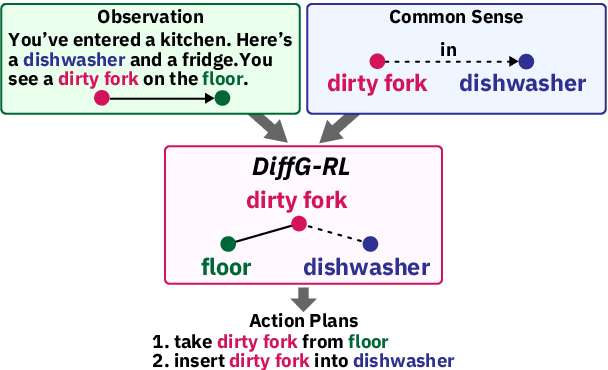
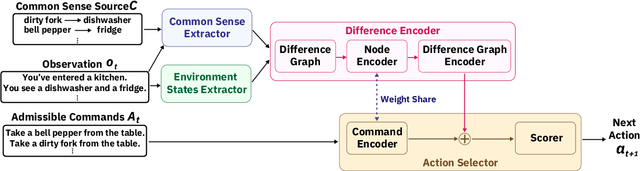
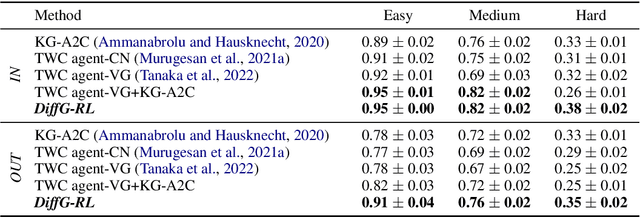
Taking into account background knowledge as the context has always been an important part of solving tasks that involve natural language. One representative example of such tasks is text-based games, where players need to make decisions based on both description text previously shown in the game, and their own background knowledge about the language and common sense. In this work, we investigate not simply giving common sense, as can be seen in prior research, but also its effective usage. We assume that a part of the environment states different from common sense should constitute one of the grounds for action selection. We propose a novel agent, DiffG-RL, which constructs a Difference Graph that organizes the environment states and common sense by means of interactive objects with a dedicated graph encoder. DiffG-RL also contains a framework for extracting the appropriate amount and representation of common sense from the source to support the construction of the graph. We validate DiffG-RL in experiments with text-based games that require common sense and show that it outperforms baselines by 17% of scores. The code is available at https://github.com/ibm/diffg-rl
LOA: Logical Optimal Actions for Text-based Interaction Games
Oct 21, 2021
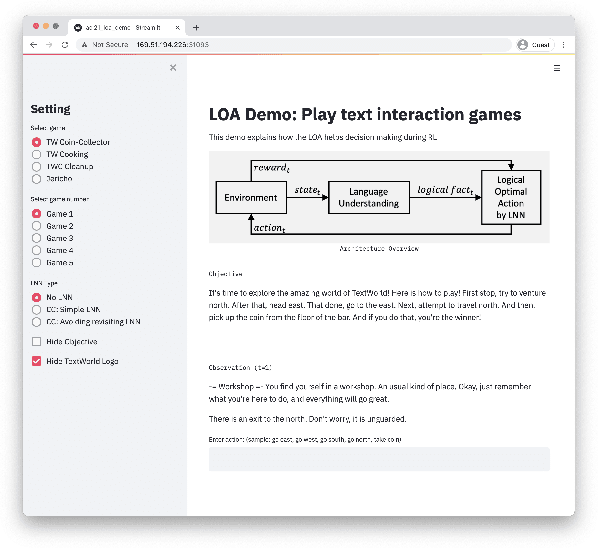
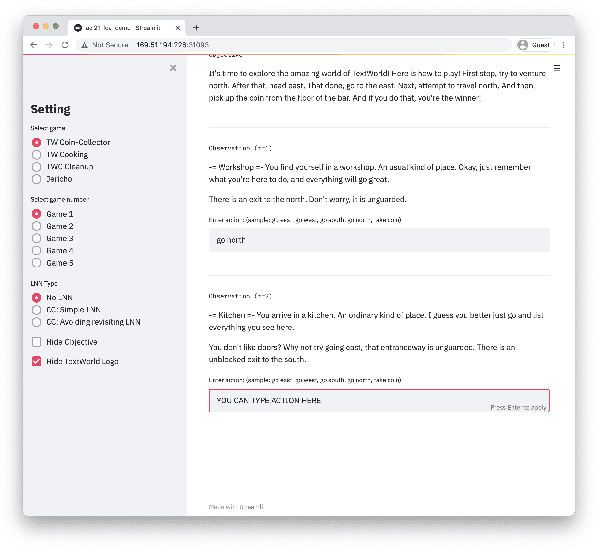
We present Logical Optimal Actions (LOA), an action decision architecture of reinforcement learning applications with a neuro-symbolic framework which is a combination of neural network and symbolic knowledge acquisition approach for natural language interaction games. The demonstration for LOA experiments consists of a web-based interactive platform for text-based games and visualization for acquired knowledge for improving interpretability for trained rules. This demonstration also provides a comparison module with other neuro-symbolic approaches as well as non-symbolic state-of-the-art agent models on the same text-based games. Our LOA also provides open-sourced implementation in Python for the reinforcement learning environment to facilitate an experiment for studying neuro-symbolic agents. Code: https://github.com/ibm/loa
Neuro-Symbolic Reinforcement Learning with First-Order Logic
Oct 21, 2021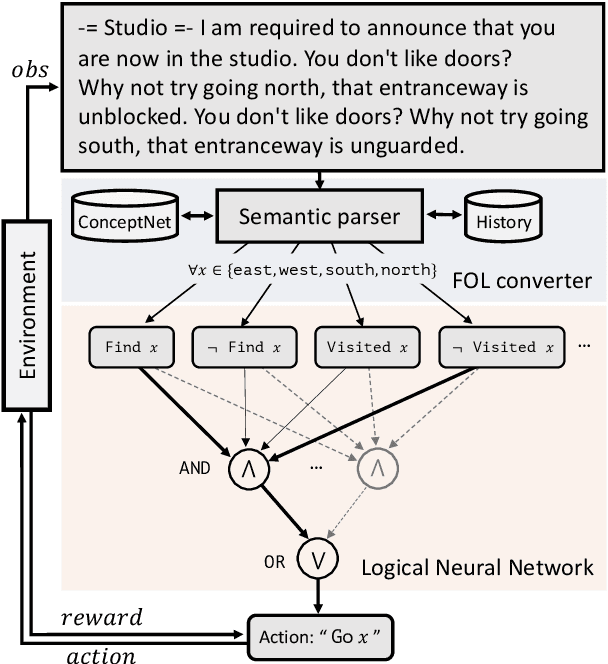
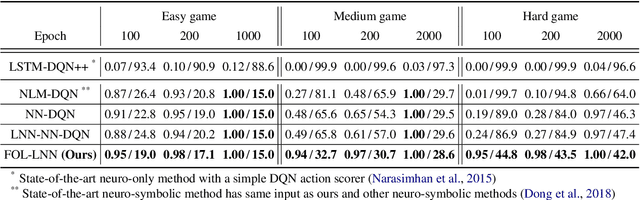
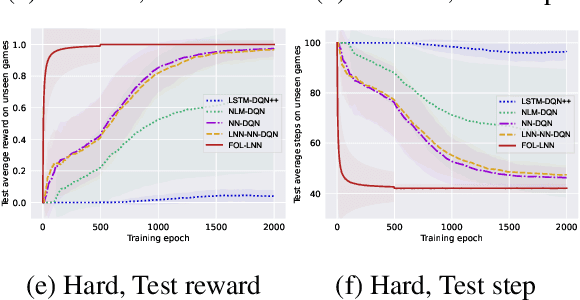
Deep reinforcement learning (RL) methods often require many trials before convergence, and no direct interpretability of trained policies is provided. In order to achieve fast convergence and interpretability for the policy in RL, we propose a novel RL method for text-based games with a recent neuro-symbolic framework called Logical Neural Network, which can learn symbolic and interpretable rules in their differentiable network. The method is first to extract first-order logical facts from text observation and external word meaning network (ConceptNet), then train a policy in the network with directly interpretable logical operators. Our experimental results show RL training with the proposed method converges significantly faster than other state-of-the-art neuro-symbolic methods in a TextWorld benchmark.
Reinforcement Learning with External Knowledge by using Logical Neural Networks
Mar 03, 2021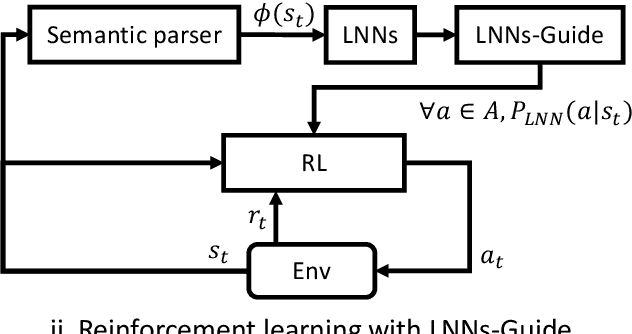
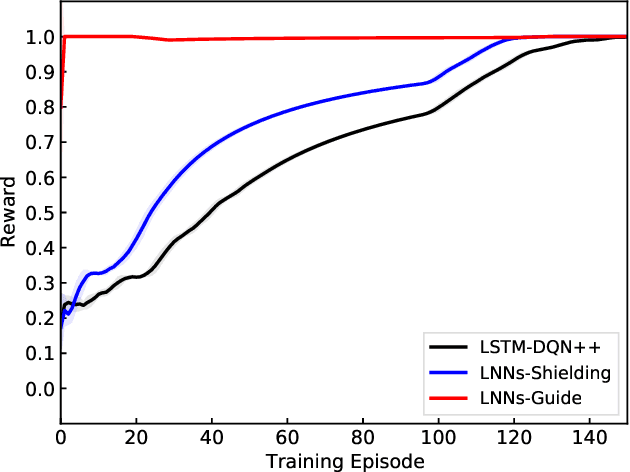
Conventional deep reinforcement learning methods are sample-inefficient and usually require a large number of training trials before convergence. Since such methods operate on an unconstrained action set, they can lead to useless actions. A recent neuro-symbolic framework called the Logical Neural Networks (LNNs) can simultaneously provide key-properties of both neural networks and symbolic logic. The LNNs functions as an end-to-end differentiable network that minimizes a novel contradiction loss to learn interpretable rules. In this paper, we utilize LNNs to define an inference graph using basic logical operations, such as AND and NOT, for faster convergence in reinforcement learning. Specifically, we propose an integrated method that enables model-free reinforcement learning from external knowledge sources in an LNNs-based logical constrained framework such as action shielding and guide. Our results empirically demonstrate that our method converges faster compared to a model-free reinforcement learning method that doesn't have such logical constraints.
Bootstrapped Q-learning with Context Relevant Observation Pruning to Generalize in Text-based Games
Sep 24, 2020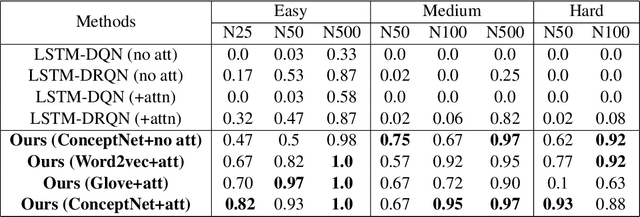
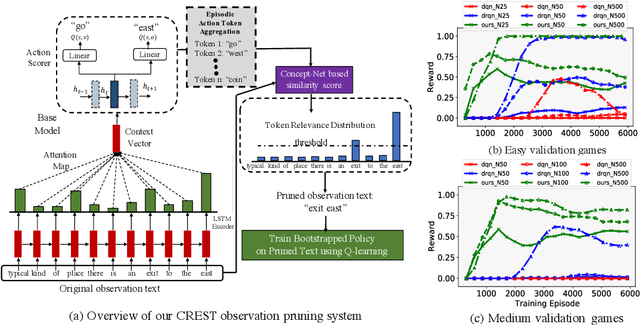
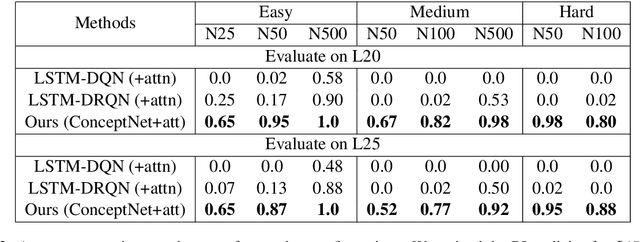
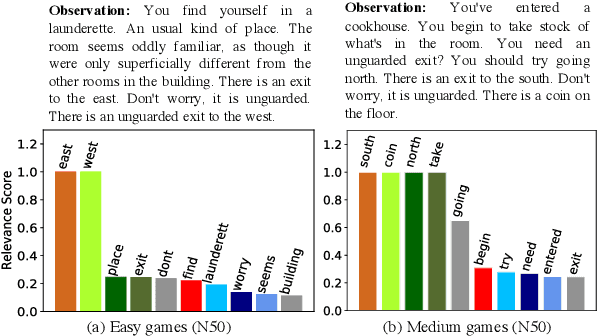
We show that Reinforcement Learning (RL) methods for solving Text-Based Games (TBGs) often fail to generalize on unseen games, especially in small data regimes. To address this issue, we propose Context Relevant Episodic State Truncation (CREST) for irrelevant token removal in observation text for improved generalization. Our method first trains a base model using Q-learning, which typically overfits the training games. The base model's action token distribution is used to perform observation pruning that removes irrelevant tokens. A second bootstrapped model is then retrained on the pruned observation text. Our bootstrapped agent shows improved generalization in solving unseen TextWorld games, using 10x-20x fewer training games compared to previous state-of-the-art methods despite requiring less number of training episodes.