 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeReducing Smoothness with Expressive Memory Enhanced Hierarchical Graph Neural Networks
Apr 02, 2025
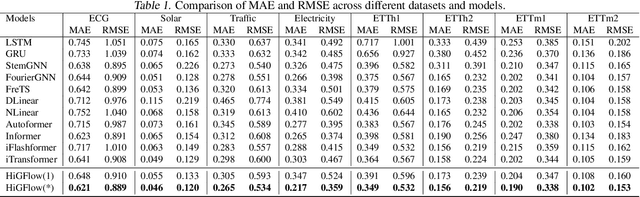
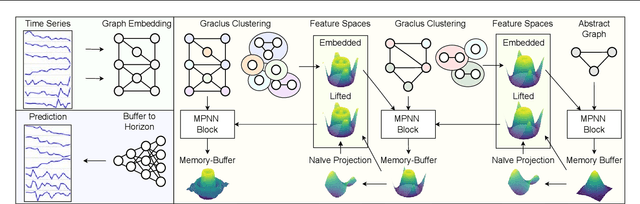
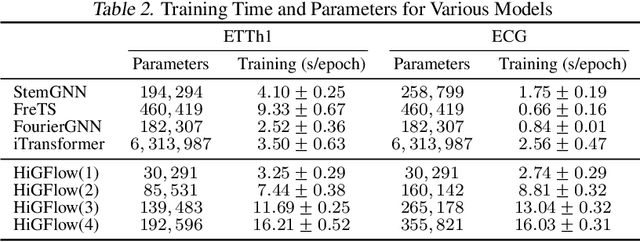
Graphical forecasting models learn the structure of time series data via projecting onto a graph, with recent techniques capturing spatial-temporal associations between variables via edge weights. Hierarchical variants offer a distinct advantage by analysing the time series across multiple resolutions, making them particularly effective in tasks like global weather forecasting, where low-resolution variable interactions are significant. A critical challenge in hierarchical models is information loss during forward or backward passes through the hierarchy. We propose the Hierarchical Graph Flow (HiGFlow) network, which introduces a memory buffer variable of dynamic size to store previously seen information across variable resolutions. We theoretically show two key results: HiGFlow reduces smoothness when mapping onto new feature spaces in the hierarchy and non-strictly enhances the utility of message-passing by improving Weisfeiler-Lehman (WL) expressivity. Empirical results demonstrate that HiGFlow outperforms state-of-the-art baselines, including transformer models, by at least an average of 6.1% in MAE and 6.2% in RMSE. Code is available at https://github.com/TB862/ HiGFlow.git.
INDUS: Effective and Efficient Language Models for Scientific Applications
May 17, 2024
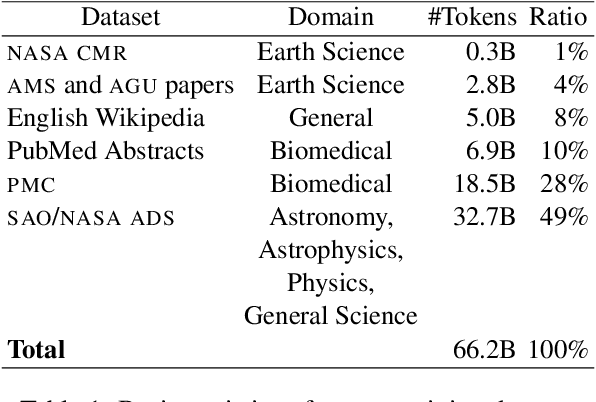
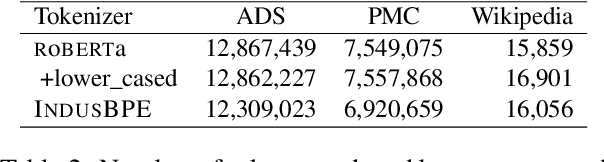

Large language models (LLMs) trained on general domain corpora showed remarkable results on natural language processing (NLP) tasks. However, previous research demonstrated LLMs trained using domain-focused corpora perform better on specialized tasks. Inspired by this pivotal insight, we developed INDUS, a comprehensive suite of LLMs tailored for the Earth science, biology, physics, heliophysics, planetary sciences and astrophysics domains and trained using curated scientific corpora drawn from diverse data sources. The suite of models include: (1) an encoder model trained using domain-specific vocabulary and corpora to address natural language understanding tasks, (2) a contrastive-learning-based general text embedding model trained using a diverse set of datasets drawn from multiple sources to address information retrieval tasks and (3) smaller versions of these models created using knowledge distillation techniques to address applications which have latency or resource constraints. We also created three new scientific benchmark datasets namely, CLIMATE-CHANGE-NER (entity-recognition), NASA-QA (extractive QA) and NASA-IR (IR) to accelerate research in these multi-disciplinary fields. Finally, we show that our models outperform both general-purpose encoders (RoBERTa) and existing domain-specific encoders (SciBERT) on these new tasks as well as existing benchmark tasks in the domains of interest.
Foundation Models for Generalist Geospatial Artificial Intelligence
Nov 08, 2023Significant progress in the development of highly adaptable and reusable Artificial Intelligence (AI) models is expected to have a significant impact on Earth science and remote sensing. Foundation models are pre-trained on large unlabeled datasets through self-supervision, and then fine-tuned for various downstream tasks with small labeled datasets. This paper introduces a first-of-a-kind framework for the efficient pre-training and fine-tuning of foundational models on extensive geospatial data. We have utilized this framework to create Prithvi, a transformer-based geospatial foundational model pre-trained on more than 1TB of multispectral satellite imagery from the Harmonized Landsat-Sentinel 2 (HLS) dataset. Our study demonstrates the efficacy of our framework in successfully fine-tuning Prithvi to a range of Earth observation tasks that have not been tackled by previous work on foundation models involving multi-temporal cloud gap imputation, flood mapping, wildfire scar segmentation, and multi-temporal crop segmentation. Our experiments show that the pre-trained model accelerates the fine-tuning process compared to leveraging randomly initialized weights. In addition, pre-trained Prithvi compares well against the state-of-the-art, e.g., outperforming a conditional GAN model in multi-temporal cloud imputation by up to 5pp (or 5.7%) in the structural similarity index. Finally, due to the limited availability of labeled data in the field of Earth observation, we gradually reduce the quantity of available labeled data for refining the model to evaluate data efficiency and demonstrate that data can be decreased significantly without affecting the model's accuracy. The pre-trained 100 million parameter model and corresponding fine-tuning workflows have been released publicly as open source contributions to the global Earth sciences community through Hugging Face.
AI Foundation Models for Weather and Climate: Applications, Design, and Implementation
Sep 20, 2023Machine learning and deep learning methods have been widely explored in understanding the chaotic behavior of the atmosphere and furthering weather forecasting. There has been increasing interest from technology companies, government institutions, and meteorological agencies in building digital twins of the Earth. Recent approaches using transformers, physics-informed machine learning, and graph neural networks have demonstrated state-of-the-art performance on relatively narrow spatiotemporal scales and specific tasks. With the recent success of generative artificial intelligence (AI) using pre-trained transformers for language modeling and vision with prompt engineering and fine-tuning, we are now moving towards generalizable AI. In particular, we are witnessing the rise of AI foundation models that can perform competitively on multiple domain-specific downstream tasks. Despite this progress, we are still in the nascent stages of a generalizable AI model for global Earth system models, regional climate models, and mesoscale weather models. Here, we review current state-of-the-art AI approaches, primarily from transformer and operator learning literature in the context of meteorology. We provide our perspective on criteria for success towards a family of foundation models for nowcasting and forecasting weather and climate predictions. We also discuss how such models can perform competitively on downstream tasks such as downscaling (super-resolution), identifying conditions conducive to the occurrence of wildfires, and predicting consequential meteorological phenomena across various spatiotemporal scales such as hurricanes and atmospheric rivers. In particular, we examine current AI methodologies and contend they have matured enough to design and implement a weather foundation model.
TensorBank:Tensor Lakehouse for Foundation Model Training
Sep 07, 2023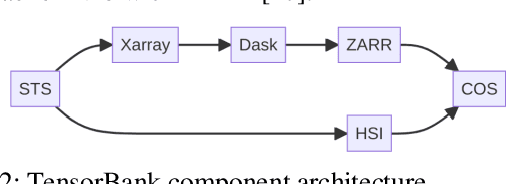
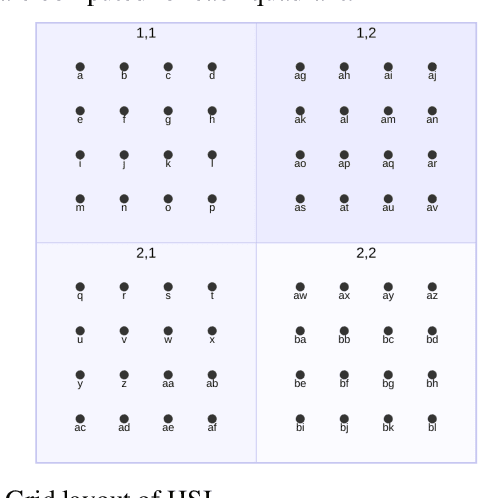
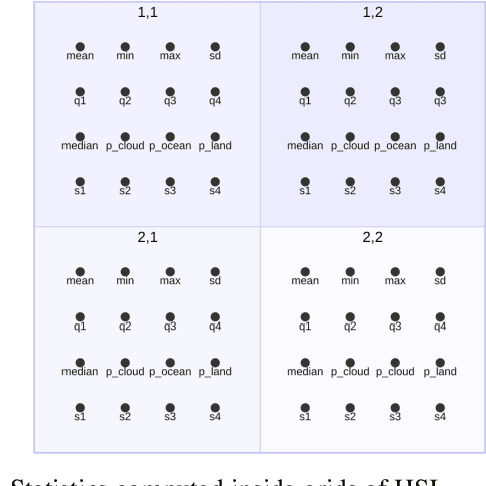
Storing and streaming high dimensional data for foundation model training became a critical requirement with the rise of foundation models beyond natural language. In this paper we introduce TensorBank, a petabyte scale tensor lakehouse capable of streaming tensors from Cloud Object Store (COS) to GPU memory at wire speed based on complex relational queries. We use Hierarchical Statistical Indices (HSI) for query acceleration. Our architecture allows to directly address tensors on block level using HTTP range reads. Once in GPU memory, data can be transformed using PyTorch transforms. We provide a generic PyTorch dataset type with a corresponding dataset factory translating relational queries and requested transformations as an instance. By making use of the HSI, irrelevant blocks can be skipped without reading them as those indices contain statistics on their content at different hierarchical resolution levels. This is an opinionated architecture powered by open standards and making heavy use of open-source technology. Although, hardened for production use using geospatial-temporal data, this architecture generalizes to other use case like computer vision, computational neuroscience, biological sequence analysis and more.
AB2CD: AI for Building Climate Damage Classification and Detection
Sep 03, 2023We explore the implementation of deep learning techniques for precise building damage assessment in the context of natural hazards, utilizing remote sensing data. The xBD dataset, comprising diverse disaster events from across the globe, serves as the primary focus, facilitating the evaluation of deep learning models. We tackle the challenges of generalization to novel disasters and regions while accounting for the influence of low-quality and noisy labels inherent in natural hazard data. Furthermore, our investigation quantitatively establishes that the minimum satellite imagery resolution essential for effective building damage detection is 3 meters and below 1 meter for classification using symmetric and asymmetric resolution perturbation analyses. To achieve robust and accurate evaluations of building damage detection and classification, we evaluated different deep learning models with residual, squeeze and excitation, and dual path network backbones, as well as ensemble techniques. Overall, the U-Net Siamese network ensemble with F-1 score of 0.812 performed the best against the xView2 challenge benchmark. Additionally, we evaluate a Universal model trained on all hazards against a flood expert model and investigate generalization gaps across events, and out of distribution from field data in the Ahr Valley. Our research findings showcase the potential and limitations of advanced AI solutions in enhancing the impact assessment of climate change-induced extreme weather events, such as floods and hurricanes. These insights have implications for disaster impact assessment in the face of escalating climate challenges.
Predicting ice flow using machine learning
Oct 20, 2019



Though machine learning has achieved notable success in modeling sequential and spatial data for speech recognition and in computer vision, applications to remote sensing and climate science problems are seldom considered. In this paper, we demonstrate techniques from unsupervised learning of future video frame prediction, to increase the accuracy of ice flow tracking in multi-spectral satellite images. As the volume of cryosphere data increases in coming years, this is an interesting and important opportunity for machine learning to address a global challenge for climate change, risk management from floods, and conserving freshwater resources. Future frame prediction of ice melt and tracking the optical flow of ice dynamics presents modeling difficulties, due to uncertainties in global temperature increase, changing precipitation patterns, occlusion from cloud cover, rapid melting and glacier retreat due to black carbon aerosol deposition, from wildfires or human fossil emissions. We show the adversarial learning method helps improve the accuracy of tracking the optical flow of ice dynamics compared to existing methods in climate science. We present a dataset, IceNet, to encourage machine learning research and to help facilitate further applications in the areas of cryospheric science and climate change.
Deep learning for Aerosol Forecasting
Oct 14, 2019
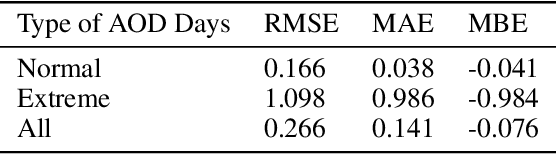


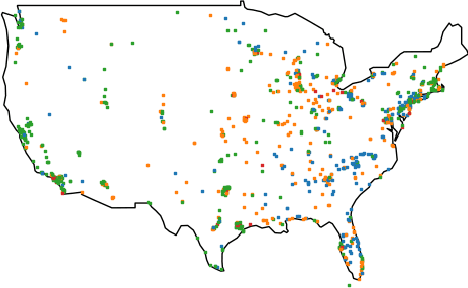
Reanalysis datasets combining numerical physics models and limited observations to generate a synthesised estimate of variables in an Earth system, are prone to biases against ground truth. Biases identified with the NASA Modern-Era Retrospective Analysis for Research and Applications, Version 2 (MERRA-2) aerosol optical depth (AOD) dataset, against the Aerosol Robotic Network (AERONET) ground measurements in previous studies, motivated the development of a deep learning based AOD prediction model globally. This study combines a convolutional neural network (CNN) with MERRA-2, tested against all AERONET sites. The new hybrid CNN-based model provides better estimates validated versus AERONET ground truth, than only using MERRA-2 reanalysis.
Tackling Climate Change with Machine Learning
Jun 10, 2019
Climate change is one of the greatest challenges facing humanity, and we, as machine learning experts, may wonder how we can help. Here we describe how machine learning can be a powerful tool in reducing greenhouse gas emissions and helping society adapt to a changing climate. From smart grids to disaster management, we identify high impact problems where existing gaps can be filled by machine learning, in collaboration with other fields. Our recommendations encompass exciting research questions as well as promising business opportunities. We call on the machine learning community to join the global effort against climate change.
Visualizing the Consequences of Climate Change Using Cycle-Consistent Adversarial Networks
May 02, 2019

We present a project that aims to generate images that depict accurate, vivid, and personalized outcomes of climate change using Cycle-Consistent Adversarial Networks (CycleGANs). By training our CycleGAN model on street-view images of houses before and after extreme weather events (e.g. floods, forest fires, etc.), we learn a mapping that can then be applied to images of locations that have not yet experienced these events. This visual transformation is paired with climate model predictions to assess likelihood and type of climate-related events in the long term (50 years) in order to bring the future closer in the viewers mind. The eventual goal of our project is to enable individuals to make more informed choices about their climate future by creating a more visceral understanding of the effects of climate change, while maintaining scientific credibility by drawing on climate model projections.