 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFingerprinting Concepts in Data Streams with Supervised and Unsupervised Meta-Information
Mar 11, 2026Streaming sources of data are becoming more common as the ability to collect data in real-time grows. A major concern in dealing with data streams is concept drift, a change in the distribution of data over time, for example, due to changes in environmental conditions. Representing concepts (stationary periods featuring similar behaviour) is a key idea in adapting to concept drift. By testing the similarity of a concept representation to a window of observations, we can detect concept drift to a new or previously seen recurring concept. Concept representations are constructed using meta-information features, values describing aspects of concept behaviour. We find that previously proposed concept representations rely on small numbers of meta-information features. These representations often cannot distinguish concepts, leaving systems vulnerable to concept drift. We propose FiCSUM, a general framework to represent both supervised and unsupervised behaviours of a concept in a fingerprint, a vector of many distinct meta-information features able to uniquely identify more concepts. Our dynamic weighting strategy learns which meta-information features describe concept drift in a given dataset, allowing a diverse set of meta-information features to be used at once. FiCSUM outperforms state-of-the-art methods over a range of 11 real world and synthetic datasets in both accuracy and modeling underlying concept drift.
Let Your Image Move with Your Motion! -- Implicit Multi-Object Multi-Motion Transfer
Mar 01, 2026Motion transfer has emerged as a promising direction for controllable video generation, yet existing methods largely focus on single-object scenarios and struggle when multiple objects require distinct motion patterns. In this work, we present FlexiMMT, the first implicit image-to-video (I2V) motion transfer framework that explicitly enables multi-object, multi-motion transfer. Given a static multi-object image and multiple reference videos, FlexiMMT independently extracts motion representations and accurately assigns them to different objects, supporting flexible recombination and arbitrary motion-to-object mappings. To address the core challenge of cross-object motion entanglement, we introduce a Motion Decoupled Mask Attention Mechanism that uses object-specific masks to constrain attention, ensuring that motion and text tokens only influence their designated regions. We further propose a Differentiated Mask Propagation Mechanism that derives object-specific masks directly from diffusion attention and progressively propagates them across frames efficiently. Extensive experiments demonstrate that FlexiMMT achieves precise, compositional, and state-of-the-art performance in I2V-based multi-object multi-motion transfer.
Animal Re-Identification on Microcontrollers
Dec 09, 2025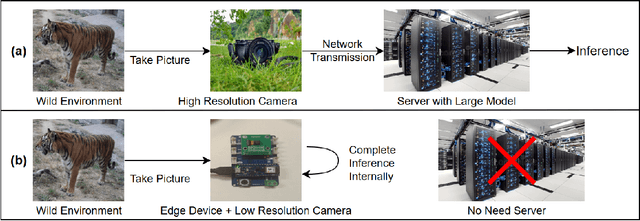



Camera-based animal re-identification (Animal Re-ID) can support wildlife monitoring and precision livestock management in large outdoor environments with limited wireless connectivity. In these settings, inference must run directly on collar tags or low-power edge nodes built around microcontrollers (MCUs), yet most Animal Re-ID models are designed for workstations or servers and are too large for devices with small memory and low-resolution inputs. We propose an on-device framework. First, we characterise the gap between state-of-the-art Animal Re-ID models and MCU-class hardware, showing that straightforward knowledge distillation from large teachers offers limited benefit once memory and input resolution are constrained. Second, guided by this analysis, we design a high-accuracy Animal Re-ID architecture by systematically scaling a CNN-based MobileNetV2 backbone for low-resolution inputs. Third, we evaluate the framework with a real-world dataset and introduce a data-efficient fine-tuning strategy to enable fast adaptation with just three images per animal identity at a new site. Across six public Animal Re-ID datasets, our compact model achieves competitive retrieval accuracy while reducing model size by over two orders of magnitude. On a self-collected cattle dataset, the deployed model performs fully on-device inference with only a small accuracy drop and unchanged Top-1 accuracy relative to its cluster version. We demonstrate that practical, adaptable Animal Re-ID is achievable on MCU-class devices, paving the way for scalable deployment in real field environments.
MultiPhishGuard: An LLM-based Multi-Agent System for Phishing Email Detection
May 26, 2025



Phishing email detection faces critical challenges from evolving adversarial tactics and heterogeneous attack patterns. Traditional detection methods, such as rule-based filters and denylists, often struggle to keep pace with these evolving tactics, leading to false negatives and compromised security. While machine learning approaches have improved detection accuracy, they still face challenges adapting to novel phishing strategies. We present MultiPhishGuard, a dynamic LLM-based multi-agent detection system that synergizes specialized expertise with adversarial-aware reinforcement learning. Our framework employs five cooperative agents (text, URL, metadata, explanation simplifier, and adversarial agents) with automatically adjusted decision weights powered by a Proximal Policy Optimization reinforcement learning algorithm. To address emerging threats, we introduce an adversarial training loop featuring an adversarial agent that generates subtle context-aware email variants, creating a self-improving defense ecosystem and enhancing system robustness. Experimental evaluations on public datasets demonstrate that MultiPhishGuard significantly outperforms Chain-of-Thoughts, single-agent baselines and state-of-the-art detectors, as validated by ablation studies and comparative analyses. Experiments demonstrate that MultiPhishGuard achieves high accuracy (97.89\%) with low false positive (2.73\%) and false negative rates (0.20\%). Additionally, we incorporate an explanation simplifier agent, which provides users with clear and easily understandable explanations for why an email is classified as phishing or legitimate. This work advances phishing defense through dynamic multi-agent collaboration and generative adversarial resilience.
Reducing Smoothness with Expressive Memory Enhanced Hierarchical Graph Neural Networks
Apr 02, 2025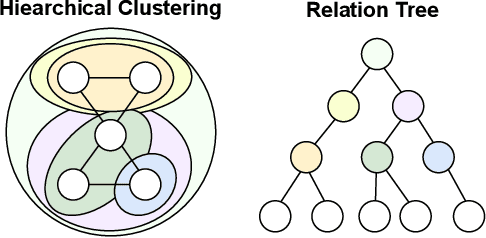
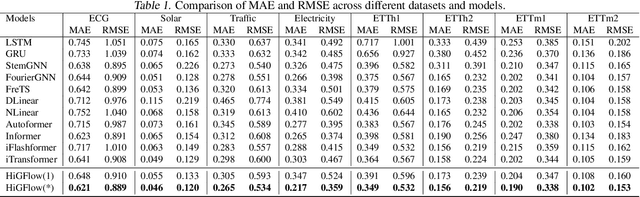
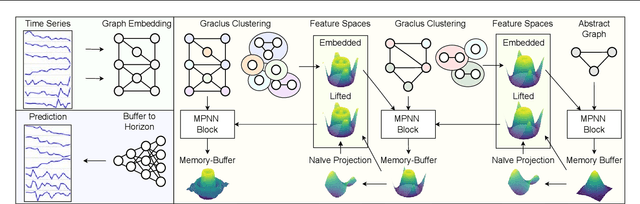
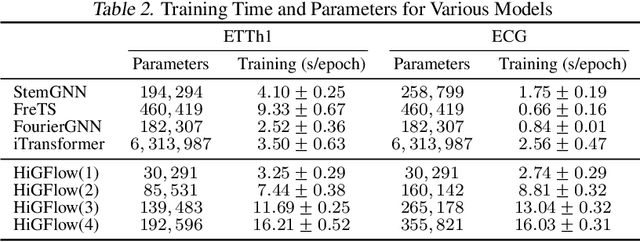
Graphical forecasting models learn the structure of time series data via projecting onto a graph, with recent techniques capturing spatial-temporal associations between variables via edge weights. Hierarchical variants offer a distinct advantage by analysing the time series across multiple resolutions, making them particularly effective in tasks like global weather forecasting, where low-resolution variable interactions are significant. A critical challenge in hierarchical models is information loss during forward or backward passes through the hierarchy. We propose the Hierarchical Graph Flow (HiGFlow) network, which introduces a memory buffer variable of dynamic size to store previously seen information across variable resolutions. We theoretically show two key results: HiGFlow reduces smoothness when mapping onto new feature spaces in the hierarchy and non-strictly enhances the utility of message-passing by improving Weisfeiler-Lehman (WL) expressivity. Empirical results demonstrate that HiGFlow outperforms state-of-the-art baselines, including transformer models, by at least an average of 6.1% in MAE and 6.2% in RMSE. Code is available at https://github.com/TB862/ HiGFlow.git.
A Study on Monthly Marine Heatwave Forecasts in New Zealand: An Investigation of Imbalanced Regression Loss Functions with Neural Network Models
Feb 19, 2025Marine heatwaves (MHWs) are extreme ocean-temperature events with significant impacts on marine ecosystems and related industries. Accurate forecasts (one to six months ahead) of MHWs would aid in mitigating these impacts. However, forecasting MHWs presents a challenging imbalanced regression task due to the rarity of extreme temperature anomalies in comparison to more frequent moderate conditions. In this study, we examine monthly MHW forecasts for 12 locations around New Zealand. We use a fully-connected neural network and compare standard and specialized regression loss functions, including the mean squared error (MSE), the mean absolute error (MAE), the Huber, the weighted MSE, the focal-R, the balanced MSE, and a proposed scaling-weighted MSE. Results show that (i) short lead times (one month) are considerably more predictable than three- and six-month leads, (ii) models trained with the standard MSE or MAE losses excel at forecasting average conditions but struggle to capture extremes, and (iii) specialized loss functions such as the balanced MSE and our scaling-weighted MSE substantially improve forecasting of MHW and suspected MHW events. These findings underscore the importance of tailored loss functions for imbalanced regression, particularly in forecasting rare but impactful events such as MHWs.
CapyMOA: Efficient Machine Learning for Data Streams in Python
Feb 11, 2025

CapyMOA is an open-source library designed for efficient machine learning on streaming data. It provides a structured framework for real-time learning and evaluation, featuring a flexible data representation. CapyMOA includes an extensible architecture that allows integration with external frameworks such as MOA and PyTorch, facilitating hybrid learning approaches that combine traditional online algorithms with deep learning techniques. By emphasizing adaptability, scalability, and usability, CapyMOA allows researchers and practitioners to tackle dynamic learning challenges across various domains.
Diving Deep: Forecasting Sea Surface Temperatures and Anomalies
Jan 10, 2025This overview paper details the findings from the Diving Deep: Forecasting Sea Surface Temperatures and Anomalies Challenge at the European Conference on Machine Learning and Principles and Practice of Knowledge Discovery in Databases (ECML PKDD) 2024. The challenge focused on the data-driven predictability of global sea surface temperatures (SSTs), a key factor in climate forecasting, ecosystem management, fisheries management, and climate change monitoring. The challenge involved forecasting SST anomalies (SSTAs) three months in advance using historical data and included a special task of predicting SSTAs nine months ahead for the Baltic Sea. Participants utilized various machine learning approaches to tackle the task, leveraging data from ERA5. This paper discusses the methodologies employed, the results obtained, and the lessons learned, offering insights into the future of climate-related predictive modeling.
Higher Order Graph Attention Probabilistic Walk Networks
Nov 18, 2024Graphs inherently capture dependencies between nodes or variables through their topological structure, with paths between any two nodes indicating a sequential dependency on the nodes traversed. Message Passing Neural Networks (MPNNs) leverage these latent relationships embedded in graph structures, and have become widely adopted across diverse applications. However, many existing methods predominantly rely on local information within the $1$-hop neighborhood. This approach has notable limitations; for example, $1$-hop aggregation schemes inherently lose long-distance information, and are limited in expressive power as defined by the $k$-Weisfeiler-Leman ($k$-WL) isomorphism test. To address these issues, we propose the Higher Order Graphical Attention (HoGA) module, which assigns weights to variable-length paths sampled based on feature-vector diversity, effectively reconstructing the $k$-hop neighborhood. HoGA represents higher-order relationships as a robust form of self-attention, applicable to any single-hop attention mechanism. In empirical studies, applying HoGA to existing attention-based models consistently leads to significant accuracy improvements on benchmark node classification datasets. Furthermore, we observe that the performance degradation typically associated with additional message-passing steps may be mitigated.
An Individual Identity-Driven Framework for Animal Re-Identification
Oct 30, 2024

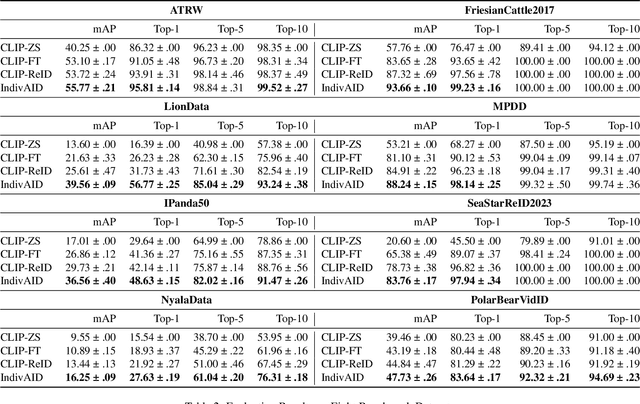
Reliable re-identification of individuals within large wildlife populations is crucial for biological studies, ecological research, and wildlife conservation. Classic computer vision techniques offer a promising direction for Animal Re-identification (Animal ReID), but their backbones' close-set nature limits their applicability and generalizability. Despite the demonstrated effectiveness of vision-language models like CLIP in re-identifying persons and vehicles, their application to Animal ReID remains limited due to unique challenges, such as the various visual representations of animals, including variations in poses and forms. To address these limitations, we leverage CLIP's cross-modal capabilities to introduce a two-stage framework, the \textbf{Indiv}idual \textbf{A}nimal \textbf{ID}entity-Driven (IndivAID) framework, specifically designed for Animal ReID. In the first stage, IndivAID trains a text description generator by extracting individual semantic information from each image, generating both image-specific and individual-specific textual descriptions that fully capture the diverse visual concepts of each individual across animal images. In the second stage, IndivAID refines its learning of visual concepts by dynamically incorporating individual-specific textual descriptions with an integrated attention module to further highlight discriminative features of individuals for Animal ReID. Evaluation against state-of-the-art methods across eight benchmark datasets and a real-world Stoat dataset demonstrates IndivAID's effectiveness and applicability. Code is available at \url{https://github.com/ywu840/IndivAID}.