 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeAn Individual Identity-Driven Framework for Animal Re-Identification
Paper and Code

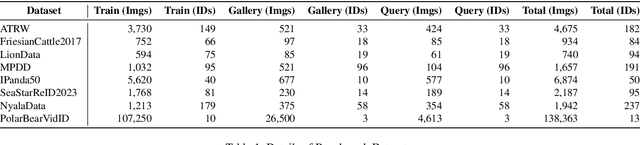

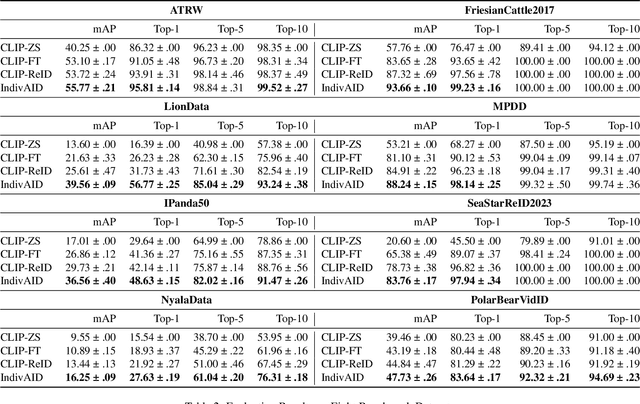
Reliable re-identification of individuals within large wildlife populations is crucial for biological studies, ecological research, and wildlife conservation. Classic computer vision techniques offer a promising direction for Animal Re-identification (Animal ReID), but their backbones' close-set nature limits their applicability and generalizability. Despite the demonstrated effectiveness of vision-language models like CLIP in re-identifying persons and vehicles, their application to Animal ReID remains limited due to unique challenges, such as the various visual representations of animals, including variations in poses and forms. To address these limitations, we leverage CLIP's cross-modal capabilities to introduce a two-stage framework, the \textbf{Indiv}idual \textbf{A}nimal \textbf{ID}entity-Driven (IndivAID) framework, specifically designed for Animal ReID. In the first stage, IndivAID trains a text description generator by extracting individual semantic information from each image, generating both image-specific and individual-specific textual descriptions that fully capture the diverse visual concepts of each individual across animal images. In the second stage, IndivAID refines its learning of visual concepts by dynamically incorporating individual-specific textual descriptions with an integrated attention module to further highlight discriminative features of individuals for Animal ReID. Evaluation against state-of-the-art methods across eight benchmark datasets and a real-world Stoat dataset demonstrates IndivAID's effectiveness and applicability. Code is available at \url{https://github.com/ywu840/IndivAID}.