 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeTrifuse: Enhancing Attention-Based GUI Grounding via Multimodal Fusion
Feb 06, 2026GUI grounding maps natural language instructions to the correct interface elements, serving as the perception foundation for GUI agents. Existing approaches predominantly rely on fine-tuning multimodal large language models (MLLMs) using large-scale GUI datasets to predict target element coordinates, which is data-intensive and generalizes poorly to unseen interfaces. Recent attention-based alternatives exploit localization signals in MLLMs attention mechanisms without task-specific fine-tuning, but suffer from low reliability due to the lack of explicit and complementary spatial anchors in GUI images. To address this limitation, we propose Trifuse, an attention-based grounding framework that explicitly integrates complementary spatial anchors. Trifuse integrates attention, OCR-derived textual cues, and icon-level caption semantics via a Consensus-SinglePeak (CS) fusion strategy that enforces cross-modal agreement while retaining sharp localization peaks. Extensive evaluations on four grounding benchmarks demonstrate that Trifuse achieves strong performance without task-specific fine-tuning, substantially reducing the reliance on expensive annotated data. Moreover, ablation studies reveal that incorporating OCR and caption cues consistently improves attention-based grounding performance across different backbones, highlighting its effectiveness as a general framework for GUI grounding.
TowerMind: A Tower Defence Game Learning Environment and Benchmark for LLM as Agents
Jan 09, 2026Recent breakthroughs in Large Language Models (LLMs) have positioned them as a promising paradigm for agents, with long-term planning and decision-making emerging as core general-purpose capabilities for adapting to diverse scenarios and tasks. Real-time strategy (RTS) games serve as an ideal testbed for evaluating these two capabilities, as their inherent gameplay requires both macro-level strategic planning and micro-level tactical adaptation and action execution. Existing RTS game-based environments either suffer from relatively high computational demands or lack support for textual observations, which has constrained the use of RTS games for LLM evaluation. Motivated by this, we present TowerMind, a novel environment grounded in the tower defense (TD) subgenre of RTS games. TowerMind preserves the key evaluation strengths of RTS games for assessing LLMs, while featuring low computational demands and a multimodal observation space, including pixel-based, textual, and structured game-state representations. In addition, TowerMind supports the evaluation of model hallucination and provides a high degree of customizability. We design five benchmark levels to evaluate several widely used LLMs under different multimodal input settings. The results reveal a clear performance gap between LLMs and human experts across both capability and hallucination dimensions. The experiments further highlight key limitations in LLM behavior, such as inadequate planning validation, a lack of multifinality in decision-making, and inefficient action use. We also evaluate two classic reinforcement learning algorithms: Ape-X DQN and PPO. By offering a lightweight and multimodal design, TowerMind complements the existing RTS game-based environment landscape and introduces a new benchmark for the AI agent field. The source code is publicly available on GitHub(https://github.com/tb6147877/TowerMind).
Animal Re-Identification on Microcontrollers
Dec 09, 2025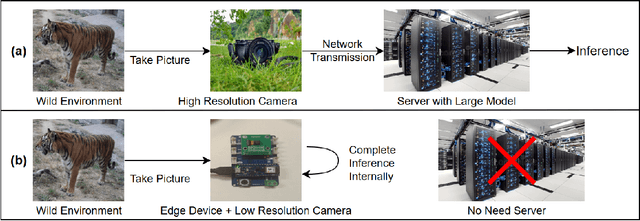



Camera-based animal re-identification (Animal Re-ID) can support wildlife monitoring and precision livestock management in large outdoor environments with limited wireless connectivity. In these settings, inference must run directly on collar tags or low-power edge nodes built around microcontrollers (MCUs), yet most Animal Re-ID models are designed for workstations or servers and are too large for devices with small memory and low-resolution inputs. We propose an on-device framework. First, we characterise the gap between state-of-the-art Animal Re-ID models and MCU-class hardware, showing that straightforward knowledge distillation from large teachers offers limited benefit once memory and input resolution are constrained. Second, guided by this analysis, we design a high-accuracy Animal Re-ID architecture by systematically scaling a CNN-based MobileNetV2 backbone for low-resolution inputs. Third, we evaluate the framework with a real-world dataset and introduce a data-efficient fine-tuning strategy to enable fast adaptation with just three images per animal identity at a new site. Across six public Animal Re-ID datasets, our compact model achieves competitive retrieval accuracy while reducing model size by over two orders of magnitude. On a self-collected cattle dataset, the deployed model performs fully on-device inference with only a small accuracy drop and unchanged Top-1 accuracy relative to its cluster version. We demonstrate that practical, adaptable Animal Re-ID is achievable on MCU-class devices, paving the way for scalable deployment in real field environments.
Real-time volumetric free-hand ultrasound imaging for large-sized organs: A study of imaging the whole spine
Nov 25, 2024Three-dimensional (3D) ultrasound imaging can overcome the limitations of conventional two dimensional (2D) ultrasound imaging in structural observation and measurement. However, conducting volumetric ultrasound imaging for large-sized organs still faces difficulties including long acquisition time, inevitable patient movement, and 3D feature recognition. In this study, we proposed a real-time volumetric free-hand ultrasound imaging system optimized for the above issues and applied it to the clinical diagnosis of scoliosis. This study employed an incremental imaging method coupled with algorithmic acceleration to enable real-time processing and visualization of the large amounts of data generated when scanning large-sized organs. Furthermore, to deal with the difficulty of image feature recognition, we proposed two tissue segmentation algorithms to reconstruct and visualize the spinal anatomy in 3D space by approximating the depth at which the bone structures are located and segmenting the ultrasound images at different depths. We validated the adaptability of our system by deploying it to multiple models of ultra-sound equipment and conducting experiments using different types of ultrasound probes. We also conducted experiments on 6 scoliosis patients and 10 normal volunteers to evaluate the performance of our proposed method. Ultrasound imaging of a volunteer spine from shoulder to crotch (more than 500 mm) was performed in 2 minutes, and the 3D imaging results displayed in real-time were compared with the corresponding X-ray images with a correlation coefficient of 0.96 in spinal curvature. Our proposed volumetric ultrasound imaging system might hold the potential to be clinically applied to other large-sized organs.
An Individual Identity-Driven Framework for Animal Re-Identification
Oct 30, 2024
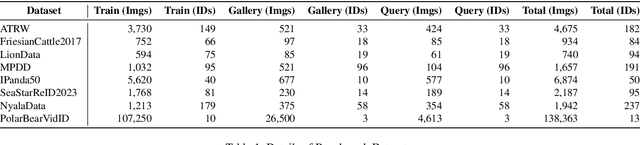

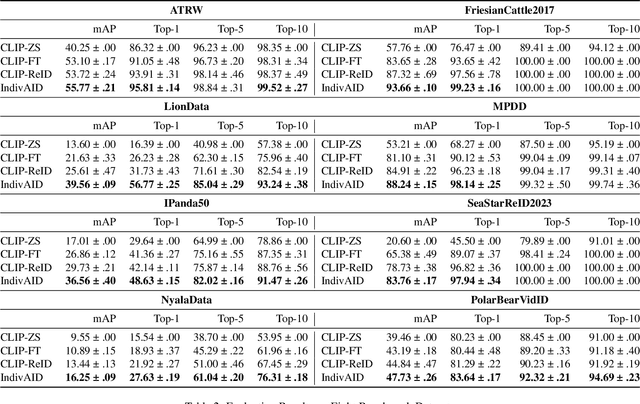
Reliable re-identification of individuals within large wildlife populations is crucial for biological studies, ecological research, and wildlife conservation. Classic computer vision techniques offer a promising direction for Animal Re-identification (Animal ReID), but their backbones' close-set nature limits their applicability and generalizability. Despite the demonstrated effectiveness of vision-language models like CLIP in re-identifying persons and vehicles, their application to Animal ReID remains limited due to unique challenges, such as the various visual representations of animals, including variations in poses and forms. To address these limitations, we leverage CLIP's cross-modal capabilities to introduce a two-stage framework, the \textbf{Indiv}idual \textbf{A}nimal \textbf{ID}entity-Driven (IndivAID) framework, specifically designed for Animal ReID. In the first stage, IndivAID trains a text description generator by extracting individual semantic information from each image, generating both image-specific and individual-specific textual descriptions that fully capture the diverse visual concepts of each individual across animal images. In the second stage, IndivAID refines its learning of visual concepts by dynamically incorporating individual-specific textual descriptions with an integrated attention module to further highlight discriminative features of individuals for Animal ReID. Evaluation against state-of-the-art methods across eight benchmark datasets and a real-world Stoat dataset demonstrates IndivAID's effectiveness and applicability. Code is available at \url{https://github.com/ywu840/IndivAID}.
MCNet: A crowd denstity estimation network based on integrating multiscale attention module
Mar 29, 2024



Aiming at the metro video surveillance system has not been able to effectively solve the metro crowd density estimation problem, a Metro Crowd density estimation Network (called MCNet) is proposed to automatically classify crowd density level of passengers. Firstly, an Integrating Multi-scale Attention (IMA) module is proposed to enhance the ability of the plain classifiers to extract semantic crowd texture features to accommodate to the characteristics of the crowd texture feature. The innovation of the IMA module is to fuse the dilation convolution, multiscale feature extraction and attention mechanism to obtain multi-scale crowd feature activation from a larger receptive field with lower computational cost, and to strengthen the crowds activation state of convolutional features in top layers. Secondly, a novel lightweight crowd texture feature extraction network is proposed, which can directly process video frames and automatically extract texture features for crowd density estimation, while its faster image processing speed and fewer network parameters make it flexible to be deployed on embedded platforms with limited hardware resources. Finally, this paper integrates IMA module and the lightweight crowd texture feature extraction network to construct the MCNet, and validate the feasibility of this network on image classification dataset: Cifar10 and four crowd density datasets: PETS2009, Mall, QUT and SH_METRO to validate the MCNet whether can be a suitable solution for crowd density estimation in metro video surveillance where there are image processing challenges such as high density, high occlusion, perspective distortion and limited hardware resources.
Radiomics-Informed Deep Learning for Classification of Atrial Fibrillation Sub-Types from Left-Atrium CT Volumes
Aug 14, 2023



Atrial Fibrillation (AF) is characterized by rapid, irregular heartbeats, and can lead to fatal complications such as heart failure. The disease is divided into two sub-types based on severity, which can be automatically classified through CT volumes for disease screening of severe cases. However, existing classification approaches rely on generic radiomic features that may not be optimal for the task, whilst deep learning methods tend to over-fit to the high-dimensional volume inputs. In this work, we propose a novel radiomics-informed deep-learning method, RIDL, that combines the advantages of deep learning and radiomic approaches to improve AF sub-type classification. Unlike existing hybrid techniques that mostly rely on na\"ive feature concatenation, we observe that radiomic feature selection methods can serve as an information prior, and propose supplementing low-level deep neural network (DNN) features with locally computed radiomic features. This reduces DNN over-fitting and allows local variations between radiomic features to be better captured. Furthermore, we ensure complementary information is learned by deep and radiomic features by designing a novel feature de-correlation loss. Combined, our method addresses the limitations of deep learning and radiomic approaches and outperforms state-of-the-art radiomic, deep learning, and hybrid approaches, achieving 86.9% AUC for the AF sub-type classification task. Code is available at https://github.com/xmed-lab/RIDL.
RISC-V Toolchain and Agile Development based Open-source Neuromorphic Processor
Oct 06, 2022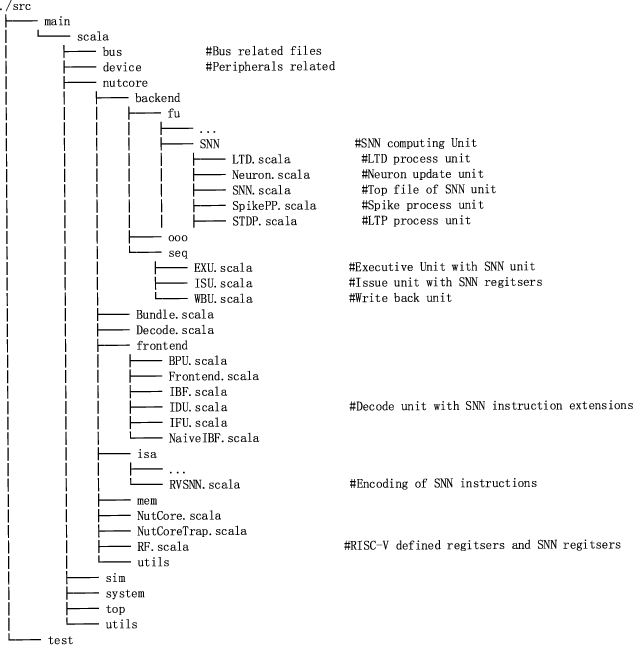

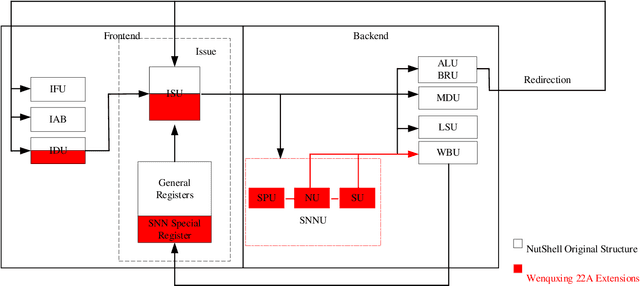
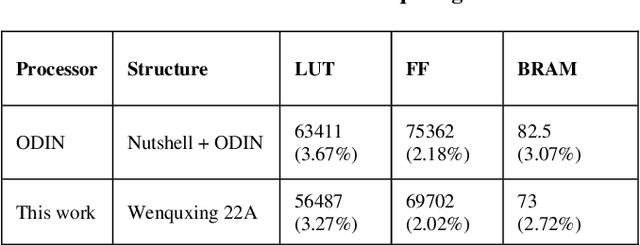
In recent decades, neuromorphic computing aiming to imitate brains' behaviors has been developed in various fields of computer science. The Artificial Neural Network (ANN) is an important concept in Artificial Intelligence (AI). It is utilized in recognition and classification. To explore a better way to simulate obtained brain behaviors, which is fast and energy-efficient, on hardware, researchers need an advanced method such as neuromorphic computing. In this case, Spiking Neural Network (SNN) becomes an optimal choice in hardware implementation. Recent works are focusing on accelerating SNN computing. However, most accelerator solutions are based on CPU-accelerator architecture which is energy-inefficient due to the complex control flows in this structure. This paper proposes Wenquxing 22A, a low-power neuromorphic processor that combines general-purpose CPU functions and SNN to efficiently compute it with RISC-V SNN extension instructions. The main idea of Wenquxing 22A is to integrate the SNN calculation unit into the pipeline of a general-purpose CPU to achieve low-power computing with customized RISC-V SNN instructions version 1.0 (RV-SNN V1.0), Streamlined Leaky Integrate-and-Fire (LIF) model, and the binary stochastic Spike-timing-dependent-plasticity (STDP). The source code of Wenquxing 22A is released online on Gitee and GitHub. We apply Wenquxing 22A to the recognition of the MNIST dataset to make a comparison with other SNN systems. Our experiment results show that Wenquxing 22A improves the energy expenses by 5.13 times over the accelerator solution, ODIN, with approximately classification accuracy, 85.00% for 3-bit ODIN online learning, and 91.91% for 1-bit Wenquxing 22A.
EEGDnet: Fusing Non-Local and Local Self-Similarity for 1-D EEG Signal Denoising with 2-D Transformer
Sep 09, 2021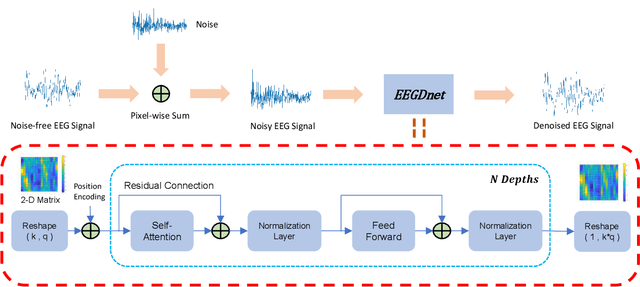



Electroencephalogram (EEG) has shown a useful approach to produce a brain-computer interface (BCI). One-dimensional (1-D) EEG signal is yet easily disturbed by certain artifacts (a.k.a. noise) due to the high temporal resolution. Thus, it is crucial to remove the noise in received EEG signal. Recently, deep learning-based EEG signal denoising approaches have achieved impressive performance compared with traditional ones. It is well known that the characteristics of self-similarity (including non-local and local ones) of data (e.g., natural images and time-domain signals) are widely leveraged for denoising. However, existing deep learning-based EEG signal denoising methods ignore either the non-local self-similarity (e.g., 1-D convolutional neural network) or local one (e.g., fully connected network and recurrent neural network). To address this issue, we propose a novel 1-D EEG signal denoising network with 2-D transformer, namely EEGDnet. Specifically, we comprehensively take into account the non-local and local self-similarity of EEG signal through the transformer module. By fusing non-local self-similarity in self-attention blocks and local self-similarity in feed forward blocks, the negative impact caused by noises and outliers can be reduced significantly. Extensive experiments show that, compared with other state-of-the-art models, EEGDnet achieves much better performance in terms of both quantitative and qualitative metrics.
Bidirectional RNN-based Few-shot Training for Detecting Multi-stage Attack
May 09, 2019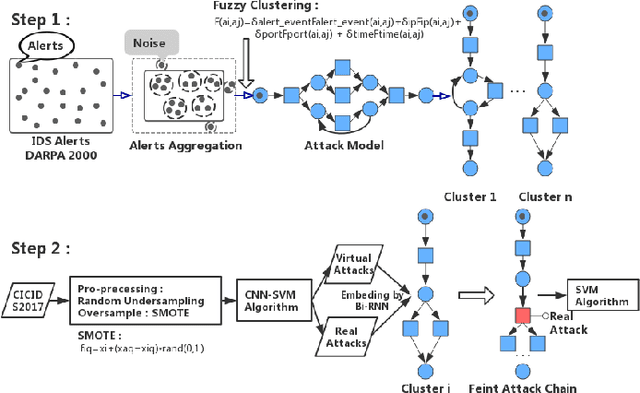
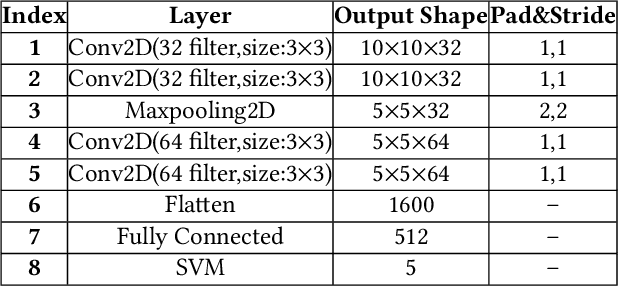
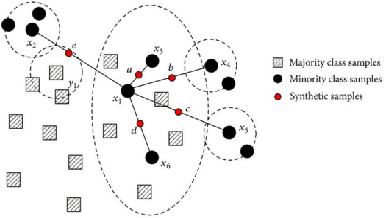
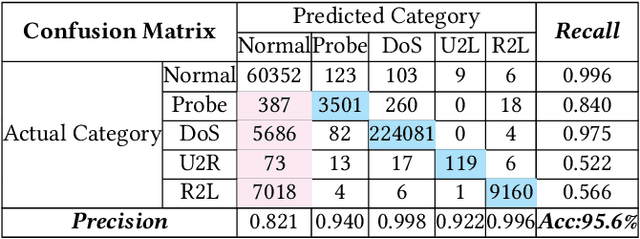
"Feint Attack", as a new type of APT attack, has become the focus of attention. It adopts a multi-stage attacks mode which can be concluded as a combination of virtual attacks and real attacks. Under the cover of virtual attacks, real attacks can achieve the real purpose of the attacker, as a result, it often caused huge losses inadvertently. However, to our knowledge, all previous works use common methods such as Causal-Correlation or Cased-based to detect outdated multi-stage attacks. Few attentions have been paid to detect the "Feint Attack", because the difficulty of detection lies in the diversification of the concept of "Feint Attack" and the lack of professional datasets, many detection methods ignore the semantic relationship in the attack. Aiming at the existing challenge, this paper explores a new method to solve the problem. In the attack scenario, the fuzzy clustering method based on attribute similarity is used to mine multi-stage attack chains. Then we use a few-shot deep learning algorithm (SMOTE&CNN-SVM) and bidirectional Recurrent Neural Network model (Bi-RNN) to obtain the "Feint Attack" chains. "Feint Attack" is simulated by the real attack inserted in the normal causal attack chain, and the addition of the real attack destroys the causal relationship of the original attack chain. So we used Bi-RNN coding to obtain the hidden feature of "Feint Attack" chain. In the end, our method achieved the goal to detect the "Feint Attack" accurately by using the LLDoS1.0 and LLDoS2.0 of DARPA2000 and CICIDS2017 of Canadian Institute for Cybersecurity.