 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeFrom Risk to Resilience: Towards Assessing and Mitigating the Risk of Data Reconstruction Attacks in Federated Learning
Dec 17, 2025Data Reconstruction Attacks (DRA) pose a significant threat to Federated Learning (FL) systems by enabling adversaries to infer sensitive training data from local clients. Despite extensive research, the question of how to characterize and assess the risk of DRAs in FL systems remains unresolved due to the lack of a theoretically-grounded risk quantification framework. In this work, we address this gap by introducing Invertibility Loss (InvLoss) to quantify the maximum achievable effectiveness of DRAs for a given data instance and FL model. We derive a tight and computable upper bound for InvLoss and explore its implications from three perspectives. First, we show that DRA risk is governed by the spectral properties of the Jacobian matrix of exchanged model updates or feature embeddings, providing a unified explanation for the effectiveness of defense methods. Second, we develop InvRE, an InvLoss-based DRA risk estimator that offers attack method-agnostic, comprehensive risk evaluation across data instances and model architectures. Third, we propose two adaptive noise perturbation defenses that enhance FL privacy without harming classification accuracy. Extensive experiments on real-world datasets validate our framework, demonstrating its potential for systematic DRA risk evaluation and mitigation in FL systems.
Triple-S: A Collaborative Multi-LLM Framework for Solving Long-Horizon Implicative Tasks in Robotics
Aug 10, 2025Leveraging Large Language Models (LLMs) to write policy code for controlling robots has gained significant attention. However, in long-horizon implicative tasks, this approach often results in API parameter, comments and sequencing errors, leading to task failure. To address this problem, we propose a collaborative Triple-S framework that involves multiple LLMs. Through In-Context Learning, different LLMs assume specific roles in a closed-loop Simplification-Solution-Summary process, effectively improving success rates and robustness in long-horizon implicative tasks. Additionally, a novel demonstration library update mechanism which learned from success allows it to generalize to previously failed tasks. We validate the framework in the Long-horizon Desktop Implicative Placement (LDIP) dataset across various baseline models, where Triple-S successfully executes 89% of tasks in both observable and partially observable scenarios. Experiments in both simulation and real-world robot settings further validated the effectiveness of Triple-S. Our code and dataset is available at: https://github.com/Ghbbbbb/Triple-S.
Lurking in the shadows: Unveiling Stealthy Backdoor Attacks against Personalized Federated Learning
Jun 10, 2024



Federated Learning (FL) is a collaborative machine learning technique where multiple clients work together with a central server to train a global model without sharing their private data. However, the distribution shift across non-IID datasets of clients poses a challenge to this one-model-fits-all method hindering the ability of the global model to effectively adapt to each client's unique local data. To echo this challenge, personalized FL (PFL) is designed to allow each client to create personalized local models tailored to their private data. While extensive research has scrutinized backdoor risks in FL, it has remained underexplored in PFL applications. In this study, we delve deep into the vulnerabilities of PFL to backdoor attacks. Our analysis showcases a tale of two cities. On the one hand, the personalization process in PFL can dilute the backdoor poisoning effects injected into the personalized local models. Furthermore, PFL systems can also deploy both server-end and client-end defense mechanisms to strengthen the barrier against backdoor attacks. On the other hand, our study shows that PFL fortified with these defense methods may offer a false sense of security. We propose \textit{PFedBA}, a stealthy and effective backdoor attack strategy applicable to PFL systems. \textit{PFedBA} ingeniously aligns the backdoor learning task with the main learning task of PFL by optimizing the trigger generation process. Our comprehensive experiments demonstrate the effectiveness of \textit{PFedBA} in seamlessly embedding triggers into personalized local models. \textit{PFedBA} yields outstanding attack performance across 10 state-of-the-art PFL algorithms, defeating the existing 6 defense mechanisms. Our study sheds light on the subtle yet potent backdoor threats to PFL systems, urging the community to bolster defenses against emerging backdoor challenges.
CARE: Ensemble Adversarial Robustness Evaluation Against Adaptive Attackers for Security Applications
Jan 20, 2024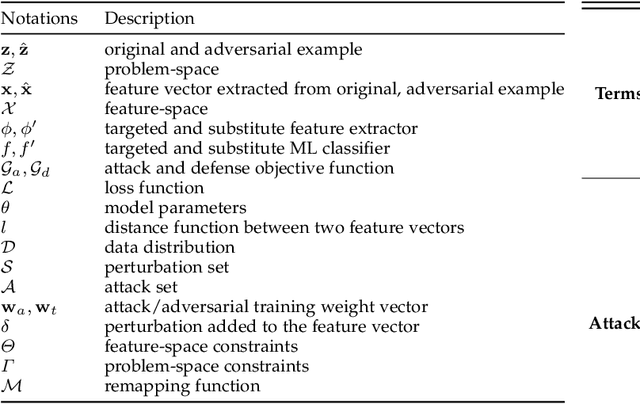
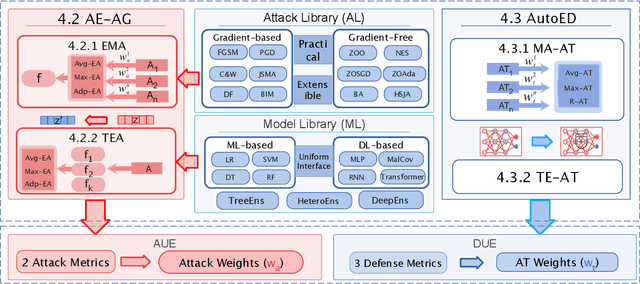

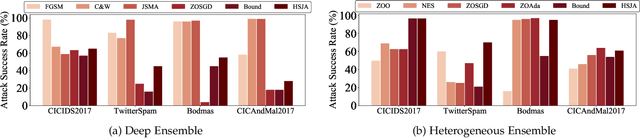
Ensemble defenses, are widely employed in various security-related applications to enhance model performance and robustness. The widespread adoption of these techniques also raises many questions: Are general ensembles defenses guaranteed to be more robust than individuals? Will stronger adaptive attacks defeat existing ensemble defense strategies as the cybersecurity arms race progresses? Can ensemble defenses achieve adversarial robustness to different types of attacks simultaneously and resist the continually adjusted adaptive attacks? Unfortunately, these critical questions remain unresolved as there are no platforms for comprehensive evaluation of ensemble adversarial attacks and defenses in the cybersecurity domain. In this paper, we propose a general Cybersecurity Adversarial Robustness Evaluation (CARE) platform aiming to bridge this gap.
TBDetector:Transformer-Based Detector for Advanced Persistent Threats with Provenance Graph
Apr 06, 2023



APT detection is difficult to detect due to the long-term latency, covert and slow multistage attack patterns of Advanced Persistent Threat (APT). To tackle these issues, we propose TBDetector, a transformer-based advanced persistent threat detection method for APT attack detection. Considering that provenance graphs provide rich historical information and have the powerful attacks historic correlation ability to identify anomalous activities, TBDetector employs provenance analysis for APT detection, which summarizes long-running system execution with space efficiency and utilizes transformer with self-attention based encoder-decoder to extract long-term contextual features of system states to detect slow-acting attacks. Furthermore, we further introduce anomaly scores to investigate the anomaly of different system states, where each state is calculated with an anomaly score corresponding to its similarity score and isolation score. To evaluate the effectiveness of the proposed method, we have conducted experiments on five public datasets, i.e., streamspot, cadets, shellshock, clearscope, and wget_baseline. Experimental results and comparisons with state-of-the-art methods have exhibited better performance of our proposed method.
DI-AA: An Interpretable White-box Attack for Fooling Deep Neural Networks
Oct 14, 2021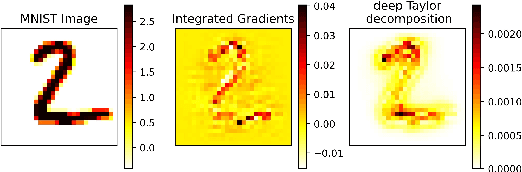
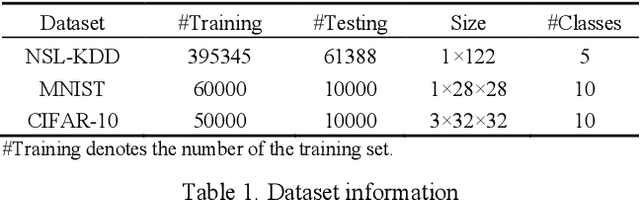
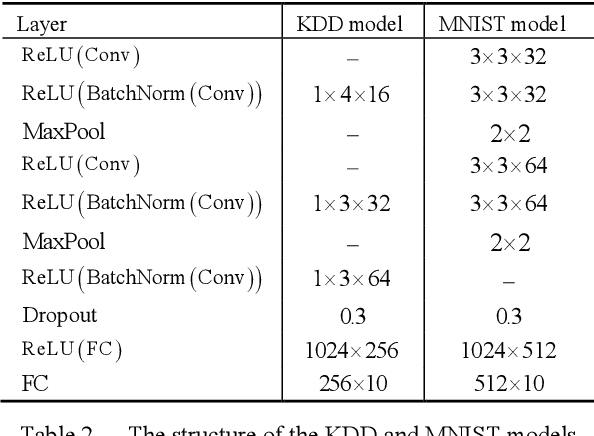
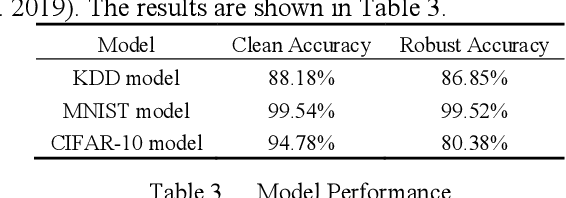
White-box Adversarial Example (AE) attacks towards Deep Neural Networks (DNNs) have a more powerful destructive capacity than black-box AE attacks in the fields of AE strategies. However, almost all the white-box approaches lack interpretation from the point of view of DNNs. That is, adversaries did not investigate the attacks from the perspective of interpretable features, and few of these approaches considered what features the DNN actually learns. In this paper, we propose an interpretable white-box AE attack approach, DI-AA, which explores the application of the interpretable approach of the deep Taylor decomposition in the selection of the most contributing features and adopts the Lagrangian relaxation optimization of the logit output and L_p norm to further decrease the perturbation. We compare DI-AA with six baseline attacks (including the state-of-the-art attack AutoAttack) on three datasets. Experimental results reveal that our proposed approach can 1) attack non-robust models with comparatively low perturbation, where the perturbation is closer to or lower than the AutoAttack approach; 2) break the TRADES adversarial training models with the highest success rate; 3) the generated AE can reduce the robust accuracy of the robust black-box models by 16% to 31% in the black-box transfer attack.
AppQ: Warm-starting App Recommendation Based on View Graphs
Sep 08, 2021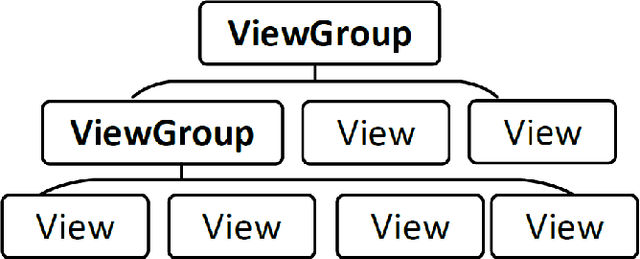
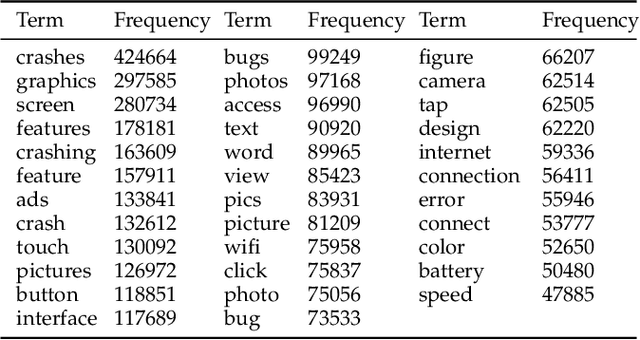
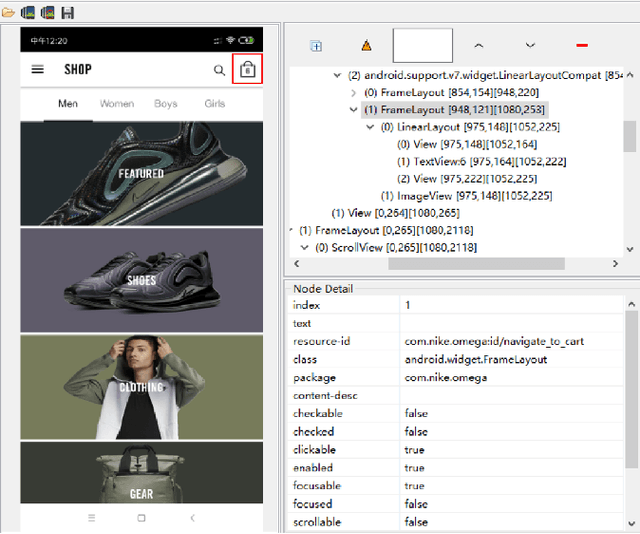
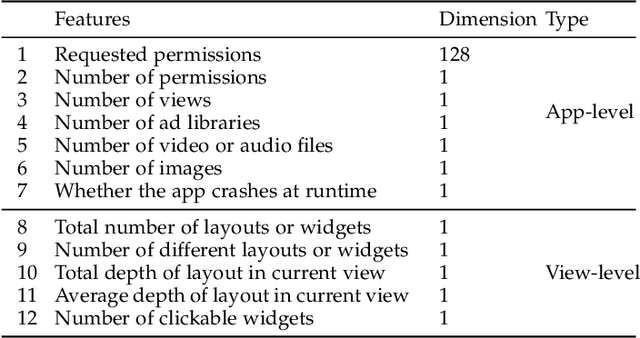
Current app ranking and recommendation systems are mainly based on user-generated information, e.g., number of downloads and ratings. However, new apps often have few (or even no) user feedback, suffering from the classic cold-start problem. How to quickly identify and then recommend new apps of high quality is a challenging issue. Here, a fundamental requirement is the capability to accurately measure an app's quality based on its inborn features, rather than user-generated features. Since users obtain first-hand experience of an app by interacting with its views, we speculate that the inborn features are largely related to the visual quality of individual views in an app and the ways the views switch to one another. In this work, we propose AppQ, a novel app quality grading and recommendation system that extracts inborn features of apps based on app source code. In particular, AppQ works in parallel to perform code analysis to extract app-level features as well as dynamic analysis to capture view-level layout hierarchy and the switching among views. Each app is then expressed as an attributed view graph, which is converted into a vector and fed to classifiers for recognizing its quality classes. Our evaluation with an app dataset from Google Play reports that AppQ achieves the best performance with accuracy of 85.0\%. This shows a lot of promise to warm-start app grading and recommendation systems with AppQ.
IWA: Integrated Gradient based White-box Attacks for Fooling Deep Neural Networks
Feb 03, 2021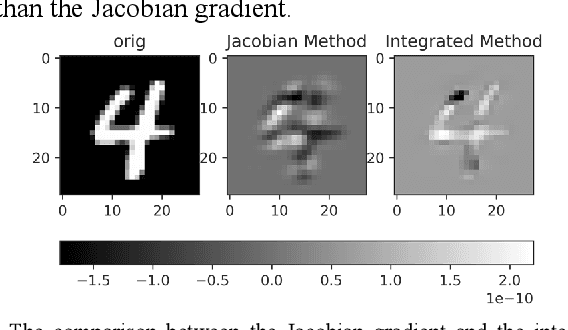
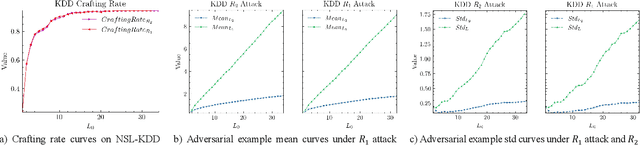
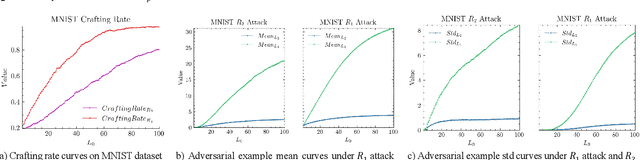
The widespread application of deep neural network (DNN) techniques is being challenged by adversarial examples, the legitimate input added with imperceptible and well-designed perturbations that can fool DNNs easily in the DNN testing/deploying stage. Previous adversarial example generation algorithms for adversarial white-box attacks used Jacobian gradient information to add perturbations. This information is too imprecise and inexplicit, which will cause unnecessary perturbations when generating adversarial examples. This paper aims to address this issue. We first propose to apply a more informative and distilled gradient information, namely integrated gradient, to generate adversarial examples. To further make the perturbations more imperceptible, we propose to employ the restriction combination of $L_0$ and $L_1/L_2$ secondly, which can restrict the total perturbations and perturbation points simultaneously. Meanwhile, to address the non-differentiable problem of $L_1$, we explore a proximal operation of $L_1$ thirdly. Based on these three works, we propose two Integrated gradient based White-box Adversarial example generation algorithms (IWA): IFPA and IUA. IFPA is suitable for situations where there are a determined number of points to be perturbed. IUA is suitable for situations where no perturbation point number is preset in order to obtain more adversarial examples. We verify the effectiveness of the proposed algorithms on both structured and unstructured datasets, and we compare them with five baseline generation algorithms. The results show that our proposed algorithms do craft adversarial examples with more imperceptible perturbations and satisfactory crafting rate. $L_2$ restriction is more suitable for unstructured dataset and $L_1$ restriction performs better in structured dataset.
Generalizing Adversarial Examples by AdaBelief Optimizer
Jan 25, 2021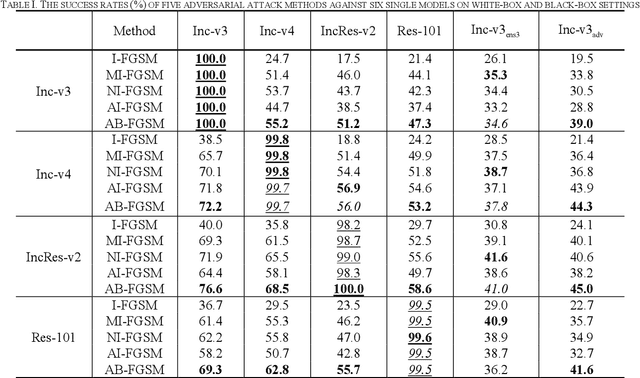
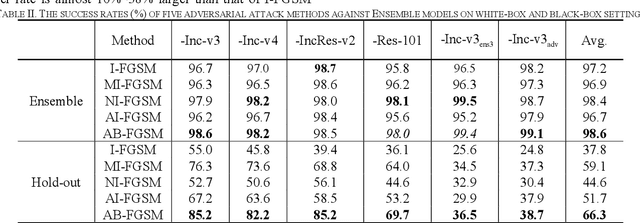
Recent research has proved that deep neural networks (DNNs) are vulnerable to adversarial examples, the legitimate input added with imperceptible and well-designed perturbations can fool DNNs easily in the testing stage. However, most of the existing adversarial attacks are difficult to fool adversarially trained models. To solve this issue, we propose an AdaBelief iterative Fast Gradient Sign Method (AB-FGSM) to generalize adversarial examples. By integrating AdaBelief optimization algorithm to I-FGSM, we believe that the generalization of adversarial examples will be improved, relying on the strong generalization of AdaBelief optimizer. To validate the effectiveness and transferability of adversarial examples generated by our proposed AB-FGSM, we conduct the white-box and black-box attacks on various single models and ensemble models. Compared with state-of-the-art attack methods, our proposed method can generate adversarial examples effectively in the white-box setting, and the transfer rate is 7%-21% higher than latest attack methods.
Bidirectional RNN-based Few-shot Training for Detecting Multi-stage Attack
May 09, 2019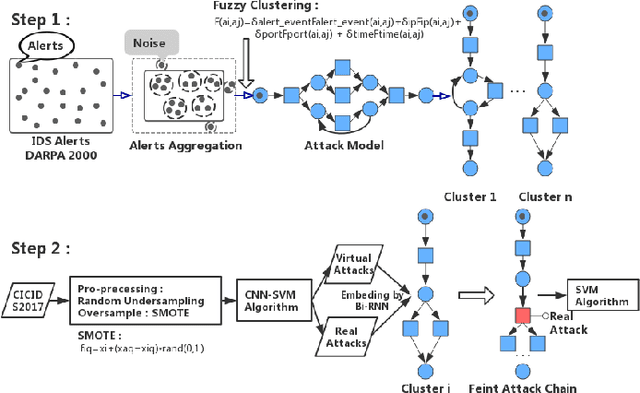
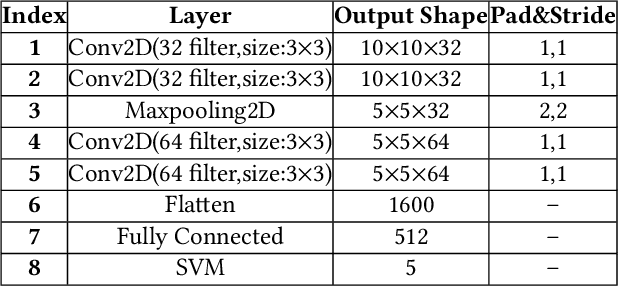
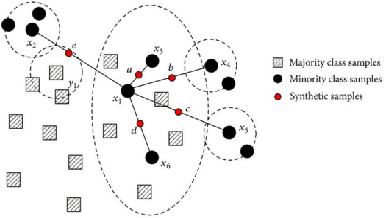
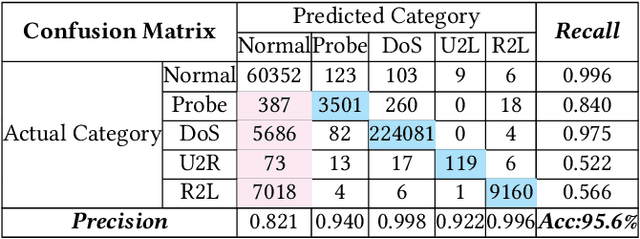
"Feint Attack", as a new type of APT attack, has become the focus of attention. It adopts a multi-stage attacks mode which can be concluded as a combination of virtual attacks and real attacks. Under the cover of virtual attacks, real attacks can achieve the real purpose of the attacker, as a result, it often caused huge losses inadvertently. However, to our knowledge, all previous works use common methods such as Causal-Correlation or Cased-based to detect outdated multi-stage attacks. Few attentions have been paid to detect the "Feint Attack", because the difficulty of detection lies in the diversification of the concept of "Feint Attack" and the lack of professional datasets, many detection methods ignore the semantic relationship in the attack. Aiming at the existing challenge, this paper explores a new method to solve the problem. In the attack scenario, the fuzzy clustering method based on attribute similarity is used to mine multi-stage attack chains. Then we use a few-shot deep learning algorithm (SMOTE&CNN-SVM) and bidirectional Recurrent Neural Network model (Bi-RNN) to obtain the "Feint Attack" chains. "Feint Attack" is simulated by the real attack inserted in the normal causal attack chain, and the addition of the real attack destroys the causal relationship of the original attack chain. So we used Bi-RNN coding to obtain the hidden feature of "Feint Attack" chain. In the end, our method achieved the goal to detect the "Feint Attack" accurately by using the LLDoS1.0 and LLDoS2.0 of DARPA2000 and CICIDS2017 of Canadian Institute for Cybersecurity.