 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeNull-Space Constrained Low-Rank Adaptation for Response-Specified Large Language Model Unlearning
Jun 09, 2026Large language model unlearning aims to suppress designated undesirable knowledge while preserving benign capabilities. Many unlearning objectives focus on suppressing undesired answers, while recent target-guided variants specify replacement behavior but still leave update locality largely unconstrained. This paper introduces \emph{Null-Space Constrained Response-Specified Unlearning} (NSRU), a projection-constrained low-rank framework for controlled LLM unlearning. NSRU uses an explicitly structured safe target response to specify the desired behavior for each forget query, while suppressing the original undesired content. To localize adaptation, NSRU estimates per-module retain subspaces from benign hidden representations and uses an orthogonal-projected low-rank parameterization to confine LoRA updates to the null space of the retain subspace. The resulting objective jointly optimizes safe-target learning, undesired-response suppression, and retention preservation under this constrained parameterization. We provide a local first-order analysis showing that the projected update reduces retain-side perturbations while preserving editable directions for shaping forget-query behavior. Experiments on TOFU show that NSRU effectively suppresses extractable forget-set knowledge while improving retain QA performance, model utility, and safe-target alignment over representative baselines. On WMDP, NSRU keeps hazardous-domain accuracy near the random-choice region while preserving broad and domain-adjacent MMLU utility. Ablation studies support the complementary roles of safe-target supervision, undesired-response suppression, retention loss, and null-space projected updates, while sensitivity and robustness analyses indicate stable behavior across the tested hyperparameter and prompt variations.
Sparse Threats, Focused Defense: Criticality-Aware Robust Reinforcement Learning for Safe Autonomous Driving
Jan 05, 2026Reinforcement learning (RL) has shown considerable potential in autonomous driving (AD), yet its vulnerability to perturbations remains a critical barrier to real-world deployment. As a primary countermeasure, adversarial training improves policy robustness by training the AD agent in the presence of an adversary that deliberately introduces perturbations. Existing approaches typically model the interaction as a zero-sum game with continuous attacks. However, such designs overlook the inherent asymmetry between the agent and the adversary and then fail to reflect the sparsity of safety-critical risks, rendering the achieved robustness inadequate for practical AD scenarios. To address these limitations, we introduce criticality-aware robust RL (CARRL), a novel adversarial training approach for handling sparse, safety-critical risks in autonomous driving. CARRL consists of two interacting components: a risk exposure adversary (REA) and a risk-targeted robust agent (RTRA). We model the interaction between the REA and RTRA as a general-sum game, allowing the REA to focus on exposing safety-critical failures (e.g., collisions) while the RTRA learns to balance safety with driving efficiency. The REA employs a decoupled optimization mechanism to better identify and exploit sparse safety-critical moments under a constrained budget. However, such focused attacks inevitably result in a scarcity of adversarial data. The RTRA copes with this scarcity by jointly leveraging benign and adversarial experiences via a dual replay buffer and enforces policy consistency under perturbations to stabilize behavior. Experimental results demonstrate that our approach reduces the collision rate by at least 22.66\% across all cases compared to state-of-the-art baseline methods.
Safe and Economical UAV Trajectory Planning in Low-Altitude Airspace: A Hybrid DRL-LLM Approach with Compliance Awareness
Jun 10, 2025



The rapid growth of the low-altitude economy has driven the widespread adoption of unmanned aerial vehicles (UAVs). This growing deployment presents new challenges for UAV trajectory planning in complex urban environments. However, existing studies often overlook key factors, such as urban airspace constraints and economic efficiency, which are essential in low-altitude economy contexts. Deep reinforcement learning (DRL) is regarded as a promising solution to these issues, while its practical adoption remains limited by low learning efficiency. To overcome this limitation, we propose a novel UAV trajectory planning framework that combines DRL with large language model (LLM) reasoning to enable safe, compliant, and economically viable path planning. Experimental results demonstrate that our method significantly outperforms existing baselines across multiple metrics, including data collection rate, collision avoidance, successful landing, regulatory compliance, and energy efficiency. These results validate the effectiveness of our approach in addressing UAV trajectory planning key challenges under constraints of the low-altitude economy networking.
Less is More: A Stealthy and Efficient Adversarial Attack Method for DRL-based Autonomous Driving Policies
Dec 04, 2024Despite significant advancements in deep reinforcement learning (DRL)-based autonomous driving policies, these policies still exhibit vulnerability to adversarial attacks. This vulnerability poses a formidable challenge to the practical deployment of these policies in autonomous driving. Designing effective adversarial attacks is an indispensable prerequisite for enhancing the robustness of these policies. In view of this, we present a novel stealthy and efficient adversarial attack method for DRL-based autonomous driving policies. Specifically, we introduce a DRL-based adversary designed to trigger safety violations (e.g., collisions) by injecting adversarial samples at critical moments. We model the attack as a mixed-integer optimization problem and formulate it as a Markov decision process. Then, we train the adversary to learn the optimal policy for attacking at critical moments without domain knowledge. Furthermore, we introduce attack-related information and a trajectory clipping method to enhance the learning capability of the adversary. Finally, we validate our method in an unprotected left-turn scenario across different traffic densities. The experimental results show that our method achieves more than 90% collision rate within three attacks in most cases. Furthermore, our method achieves more than 130% improvement in attack efficiency compared to the unlimited attack method.
CRS-FL: Conditional Random Sampling for Communication-Efficient and Privacy-Preserving Federated Learning
Jun 07, 2023


Federated Learning (FL), a privacy-oriented distributed ML paradigm, is being gaining great interest in Internet of Things because of its capability to protect participants data privacy. Studies have been conducted to address challenges existing in standard FL, including communication efficiency and privacy-preserving. But they cannot achieve the goal of making a tradeoff between communication efficiency and model accuracy while guaranteeing privacy. This paper proposes a Conditional Random Sampling (CRS) method and implements it into the standard FL settings (CRS-FL) to tackle the above-mentioned challenges. CRS explores a stochastic coefficient based on Poisson sampling to achieve a higher probability of obtaining zero-gradient unbiasedly, and then decreases the communication overhead effectively without model accuracy degradation. Moreover, we dig out the relaxation Local Differential Privacy (LDP) guarantee conditions of CRS theoretically. Extensive experiment results indicate that (1) in communication efficiency, CRS-FL performs better than the existing methods in metric accuracy per transmission byte without model accuracy reduction in more than 7% sampling ratio (# sampling size / # model size); (2) in privacy-preserving, CRS-FL achieves no accuracy reduction compared with LDP baselines while holding the efficiency, even exceeding them in model accuracy under more sampling ratio conditions.
DI-AA: An Interpretable White-box Attack for Fooling Deep Neural Networks
Oct 14, 2021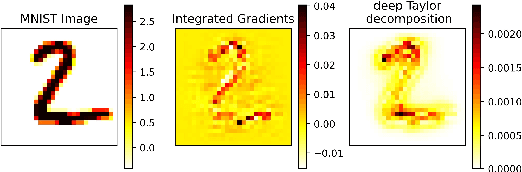
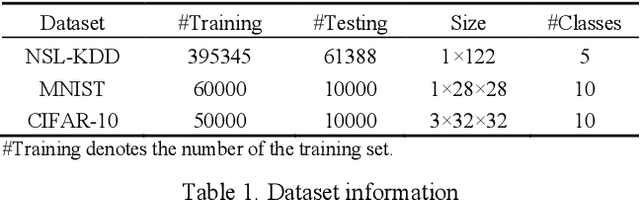
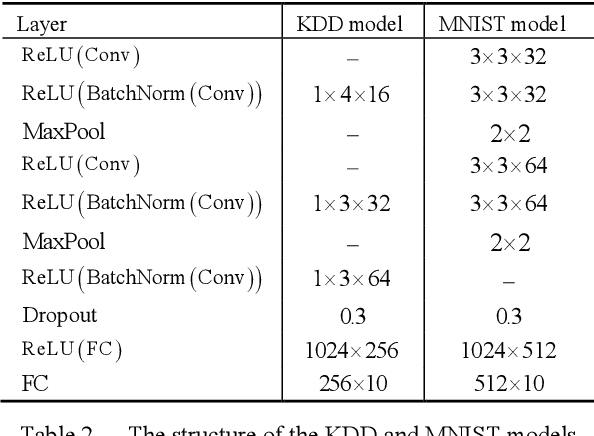
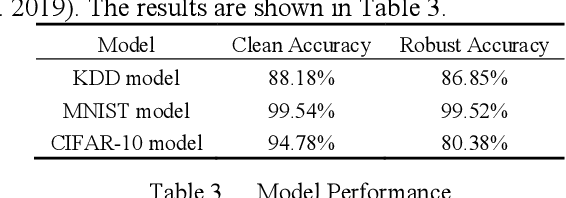
White-box Adversarial Example (AE) attacks towards Deep Neural Networks (DNNs) have a more powerful destructive capacity than black-box AE attacks in the fields of AE strategies. However, almost all the white-box approaches lack interpretation from the point of view of DNNs. That is, adversaries did not investigate the attacks from the perspective of interpretable features, and few of these approaches considered what features the DNN actually learns. In this paper, we propose an interpretable white-box AE attack approach, DI-AA, which explores the application of the interpretable approach of the deep Taylor decomposition in the selection of the most contributing features and adopts the Lagrangian relaxation optimization of the logit output and L_p norm to further decrease the perturbation. We compare DI-AA with six baseline attacks (including the state-of-the-art attack AutoAttack) on three datasets. Experimental results reveal that our proposed approach can 1) attack non-robust models with comparatively low perturbation, where the perturbation is closer to or lower than the AutoAttack approach; 2) break the TRADES adversarial training models with the highest success rate; 3) the generated AE can reduce the robust accuracy of the robust black-box models by 16% to 31% in the black-box transfer attack.
IWA: Integrated Gradient based White-box Attacks for Fooling Deep Neural Networks
Feb 03, 2021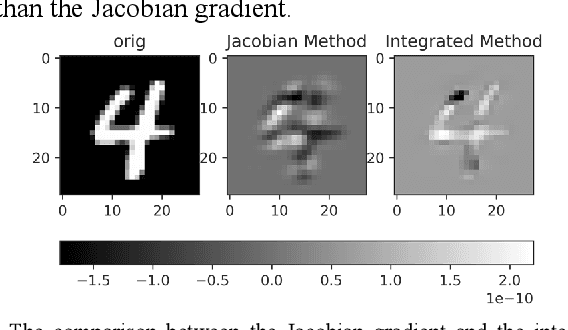
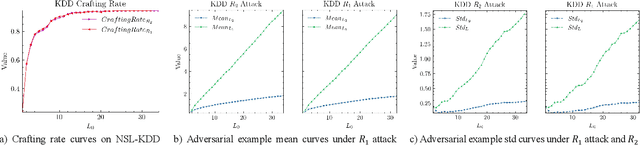
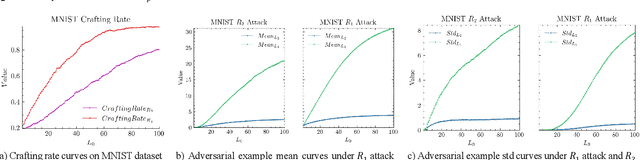
The widespread application of deep neural network (DNN) techniques is being challenged by adversarial examples, the legitimate input added with imperceptible and well-designed perturbations that can fool DNNs easily in the DNN testing/deploying stage. Previous adversarial example generation algorithms for adversarial white-box attacks used Jacobian gradient information to add perturbations. This information is too imprecise and inexplicit, which will cause unnecessary perturbations when generating adversarial examples. This paper aims to address this issue. We first propose to apply a more informative and distilled gradient information, namely integrated gradient, to generate adversarial examples. To further make the perturbations more imperceptible, we propose to employ the restriction combination of $L_0$ and $L_1/L_2$ secondly, which can restrict the total perturbations and perturbation points simultaneously. Meanwhile, to address the non-differentiable problem of $L_1$, we explore a proximal operation of $L_1$ thirdly. Based on these three works, we propose two Integrated gradient based White-box Adversarial example generation algorithms (IWA): IFPA and IUA. IFPA is suitable for situations where there are a determined number of points to be perturbed. IUA is suitable for situations where no perturbation point number is preset in order to obtain more adversarial examples. We verify the effectiveness of the proposed algorithms on both structured and unstructured datasets, and we compare them with five baseline generation algorithms. The results show that our proposed algorithms do craft adversarial examples with more imperceptible perturbations and satisfactory crafting rate. $L_2$ restriction is more suitable for unstructured dataset and $L_1$ restriction performs better in structured dataset.
Generalizing Adversarial Examples by AdaBelief Optimizer
Jan 25, 2021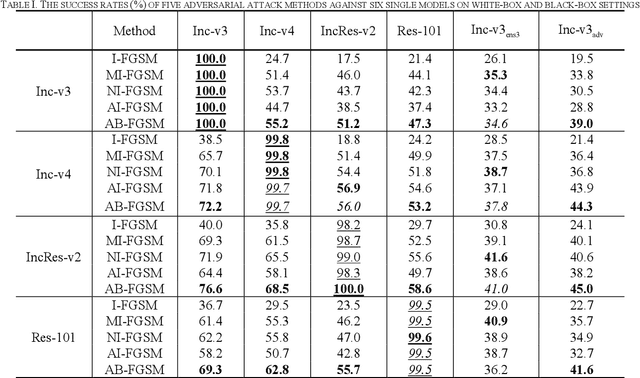
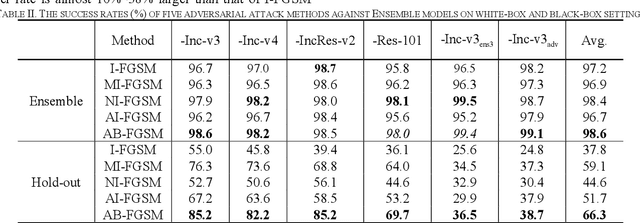
Recent research has proved that deep neural networks (DNNs) are vulnerable to adversarial examples, the legitimate input added with imperceptible and well-designed perturbations can fool DNNs easily in the testing stage. However, most of the existing adversarial attacks are difficult to fool adversarially trained models. To solve this issue, we propose an AdaBelief iterative Fast Gradient Sign Method (AB-FGSM) to generalize adversarial examples. By integrating AdaBelief optimization algorithm to I-FGSM, we believe that the generalization of adversarial examples will be improved, relying on the strong generalization of AdaBelief optimizer. To validate the effectiveness and transferability of adversarial examples generated by our proposed AB-FGSM, we conduct the white-box and black-box attacks on various single models and ensemble models. Compared with state-of-the-art attack methods, our proposed method can generate adversarial examples effectively in the white-box setting, and the transfer rate is 7%-21% higher than latest attack methods.
Towards interpreting ML-based automated malware detection models: a survey
Jan 15, 2021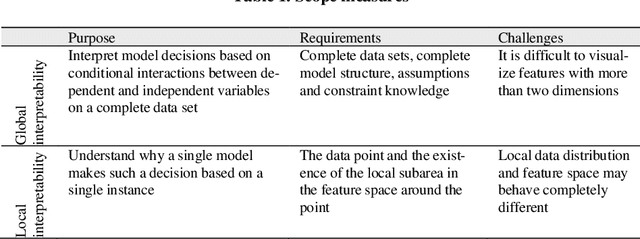



Malware is being increasingly threatening and malware detectors based on traditional signature-based analysis are no longer suitable for current malware detection. Recently, the models based on machine learning (ML) are developed for predicting unknown malware variants and saving human strength. However, most of the existing ML models are black-box, which made their pre-diction results undependable, and therefore need further interpretation in order to be effectively deployed in the wild. This paper aims to examine and categorize the existing researches on ML-based malware detector interpretability. We first give a detailed comparison over the previous work on common ML model inter-pretability in groups after introducing the principles, attributes, evaluation indi-cators and taxonomy of common ML interpretability. Then we investigate the interpretation methods towards malware detection, by addressing the importance of interpreting malware detectors, challenges faced by this field, solutions for migitating these challenges, and a new taxonomy for classifying all the state-of-the-art malware detection interpretability work in recent years. The highlight of our survey is providing a new taxonomy towards malware detection interpreta-tion methods based on the common taxonomy summarized by previous re-searches in the common field. In addition, we are the first to evaluate the state-of-the-art approaches by interpretation method attributes to generate the final score so as to give insight to quantifying the interpretability. By concluding the results of the recent researches, we hope our work can provide suggestions for researchers who are interested in the interpretability on ML-based malware de-tection models.
Towards Interpretable Ensemble Learning for Image-based Malware Detection
Jan 13, 2021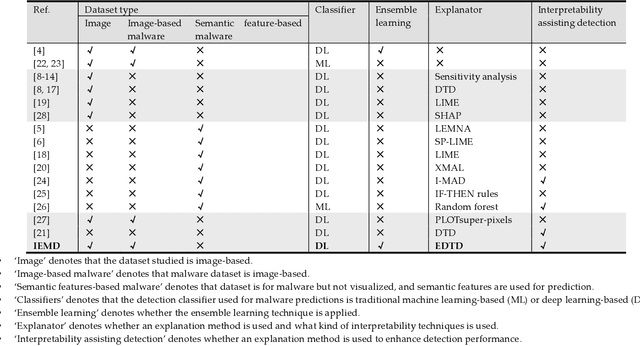
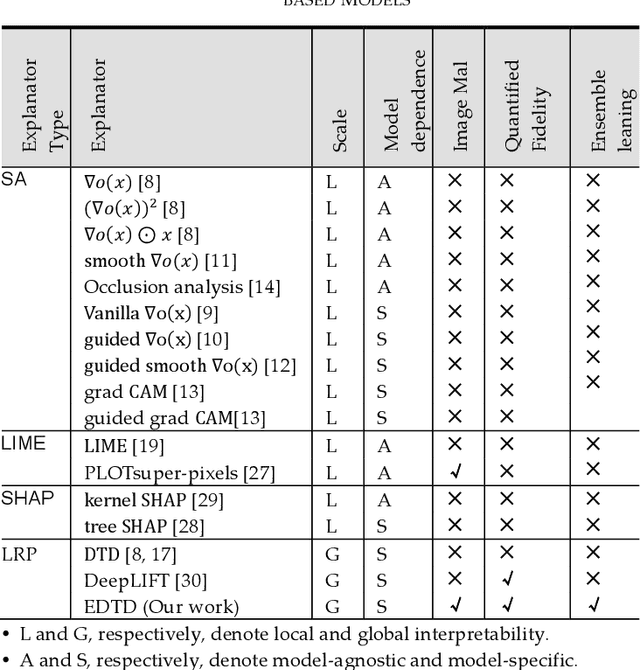

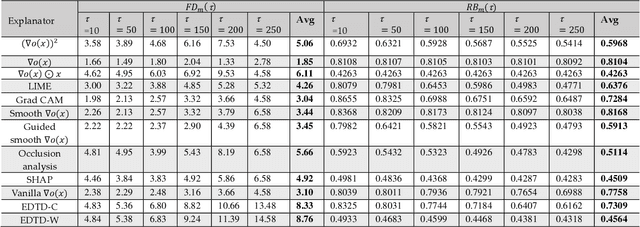
Deep learning (DL) models for image-based malware detection have exhibited their capability in producing high prediction accuracy. But model interpretability is posing challenges to their widespread application in security and safety-critical application domains. This paper aims for designing an Interpretable Ensemble learning approach for image-based Malware Detection (IEMD). We first propose a Selective Deep Ensemble Learning-based (SDEL) detector and then design an Ensemble Deep Taylor Decomposition (EDTD) approach, which can give the pixel-level explanation to SDEL detector outputs. Furthermore, we develop formulas for calculating fidelity, robustness and expressiveness on pixel-level heatmaps in order to assess the quality of EDTD explanation. With EDTD explanation, we develop a novel Interpretable Dropout approach (IDrop), which establishes IEMD by training SDEL detector. Experiment results exhibit the better explanation of our EDTD than the previous explanation methods for image-based malware detection. Besides, experiment results indicate that IEMD achieves a higher detection accuracy up to 99.87% while exhibiting interpretability with high quality of prediction results. Moreover, experiment results indicate that IEMD interpretability increases with the increasing detection accuracy during the construction of IEMD. This consistency suggests that IDrop can mitigate the tradeoff between model interpretability and detection accuracy.