 Add to Chrome
Add to Chrome Add to Firefox
Add to Firefox Add to Edge
Add to EdgeERNIE 5.0 Technical Report
Feb 04, 2026In this report, we introduce ERNIE 5.0, a natively autoregressive foundation model desinged for unified multimodal understanding and generation across text, image, video, and audio. All modalities are trained from scratch under a unified next-group-of-tokens prediction objective, based on an ultra-sparse mixture-of-experts (MoE) architecture with modality-agnostic expert routing. To address practical challenges in large-scale deployment under diverse resource constraints, ERNIE 5.0 adopts a novel elastic training paradigm. Within a single pre-training run, the model learns a family of sub-models with varying depths, expert capacities, and routing sparsity, enabling flexible trade-offs among performance, model size, and inference latency in memory- or time-constrained scenarios. Moreover, we systematically address the challenges of scaling reinforcement learning to unified foundation models, thereby guaranteeing efficient and stable post-training under ultra-sparse MoE architectures and diverse multimodal settings. Extensive experiments demonstrate that ERNIE 5.0 achieves strong and balanced performance across multiple modalities. To the best of our knowledge, among publicly disclosed models, ERNIE 5.0 represents the first production-scale realization of a trillion-parameter unified autoregressive model that supports both multimodal understanding and generation. To facilitate further research, we present detailed visualizations of modality-agnostic expert routing in the unified model, alongside comprehensive empirical analysis of elastic training, aiming to offer profound insights to the community.
Sparse Threats, Focused Defense: Criticality-Aware Robust Reinforcement Learning for Safe Autonomous Driving
Jan 05, 2026Reinforcement learning (RL) has shown considerable potential in autonomous driving (AD), yet its vulnerability to perturbations remains a critical barrier to real-world deployment. As a primary countermeasure, adversarial training improves policy robustness by training the AD agent in the presence of an adversary that deliberately introduces perturbations. Existing approaches typically model the interaction as a zero-sum game with continuous attacks. However, such designs overlook the inherent asymmetry between the agent and the adversary and then fail to reflect the sparsity of safety-critical risks, rendering the achieved robustness inadequate for practical AD scenarios. To address these limitations, we introduce criticality-aware robust RL (CARRL), a novel adversarial training approach for handling sparse, safety-critical risks in autonomous driving. CARRL consists of two interacting components: a risk exposure adversary (REA) and a risk-targeted robust agent (RTRA). We model the interaction between the REA and RTRA as a general-sum game, allowing the REA to focus on exposing safety-critical failures (e.g., collisions) while the RTRA learns to balance safety with driving efficiency. The REA employs a decoupled optimization mechanism to better identify and exploit sparse safety-critical moments under a constrained budget. However, such focused attacks inevitably result in a scarcity of adversarial data. The RTRA copes with this scarcity by jointly leveraging benign and adversarial experiences via a dual replay buffer and enforces policy consistency under perturbations to stabilize behavior. Experimental results demonstrate that our approach reduces the collision rate by at least 22.66\% across all cases compared to state-of-the-art baseline methods.
An artificially intelligent magnetic resonance spectroscopy quantification method: Comparison between QNet and LCModel on the cloud computing platform CloudBrain-MRS
Mar 06, 2025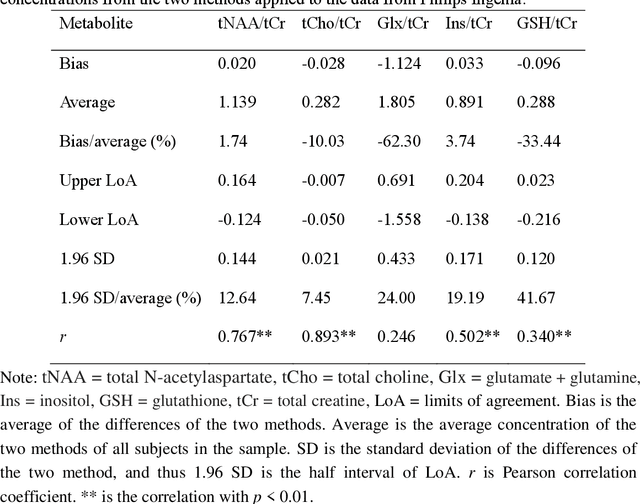

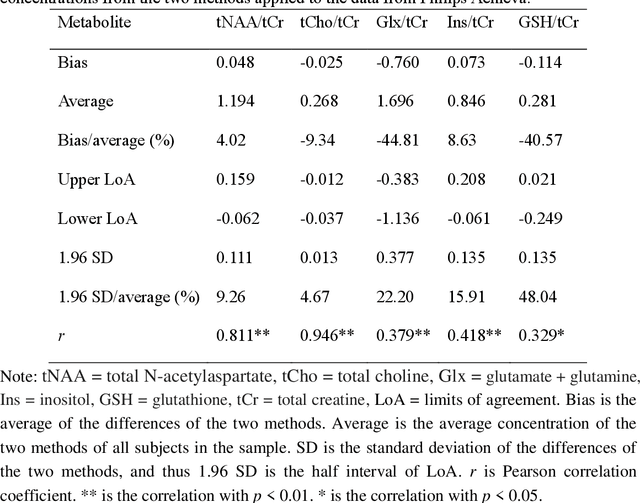
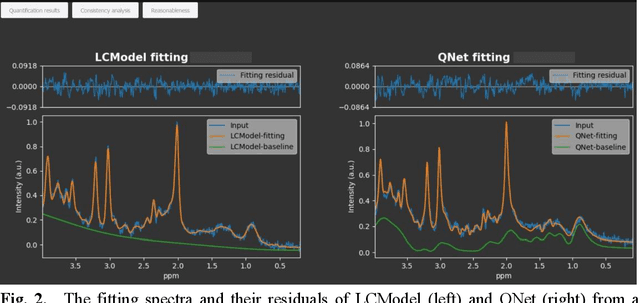
Objctives: This work aimed to statistically compare the metabolite quantification of human brain magnetic resonance spectroscopy (MRS) between the deep learning method QNet and the classical method LCModel through an easy-to-use intelligent cloud computing platform CloudBrain-MRS. Materials and Methods: In this retrospective study, two 3 T MRI scanners Philips Ingenia and Achieva collected 61 and 46 in vivo 1H magnetic resonance (MR) spectra of healthy participants, respectively, from the brain region of pregenual anterior cingulate cortex from September to October 2021. The analyses of Bland-Altman, Pearson correlation and reasonability were performed to assess the degree of agreement, linear correlation and reasonability between the two quantification methods. Results: Fifteen healthy volunteers (12 females and 3 males, age range: 21-35 years, mean age/standard deviation = 27.4/3.9 years) were recruited. The analyses of Bland-Altman, Pearson correlation and reasonability showed high to good consistency and very strong to moderate correlation between the two methods for quantification of total N-acetylaspartate (tNAA), total choline (tCho), and inositol (Ins) (relative half interval of limits of agreement = 3.04%, 9.3%, and 18.5%, respectively; Pearson correlation coefficient r = 0.775, 0.927, and 0.469, respectively). In addition, quantification results of QNet are more likely to be closer to the previous reported average values than those of LCModel. Conclusion: There were high or good degrees of consistency between the quantification results of QNet and LCModel for tNAA, tCho, and Ins, and QNet generally has more reasonable quantification than LCModel.
Reproducibility Assessment of Magnetic Resonance Spectroscopy of Pregenual Anterior Cingulate Cortex across Sessions and Vendors via the Cloud Computing Platform CloudBrain-MRS
Mar 06, 2025



Given the need to elucidate the mechanisms underlying illnesses and their treatment, as well as the lack of harmonization of acquisition and post-processing protocols among different magnetic resonance system vendors, this work is to determine if metabolite concentrations obtained from different sessions, machine models and even different vendors of 3 T scanners can be highly reproducible and be pooled for diagnostic analysis, which is very valuable for the research of rare diseases. Participants underwent magnetic resonance imaging (MRI) scanning once on two separate days within one week (one session per day, each session including two proton magnetic resonance spectroscopy (1H-MRS) scans with no more than a 5-minute interval between scans (no off-bed activity)) on each machine. were analyzed for reliability of within- and between- sessions using the coefficient of variation (CV) and intraclass correlation coefficient (ICC), and for reproducibility of across the machines using correlation coefficient. As for within- and between- session, all CV values for a group of all the first or second scans of a session, or for a session were almost below 20%, and most of the ICCs for metabolites range from moderate (0.4-0.59) to excellent (0.75-1), indicating high data reliability. When it comes to the reproducibility across the three scanners, all Pearson correlation coefficients across the three machines approached 1 with most around 0.9, and majority demonstrated statistical significance (P<0.01). Additionally, the intra-vendor reproducibility was greater than the inter-vendor ones.
Weighted Combination and Singular Spectrum Analysis Based Remote Photoplethysmography Pulse Extraction in Low-light Environments
Mar 04, 2025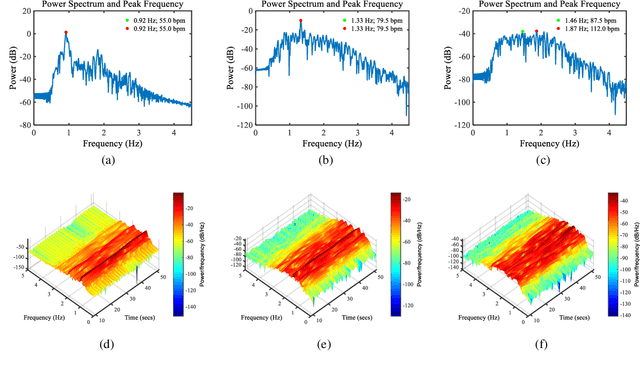
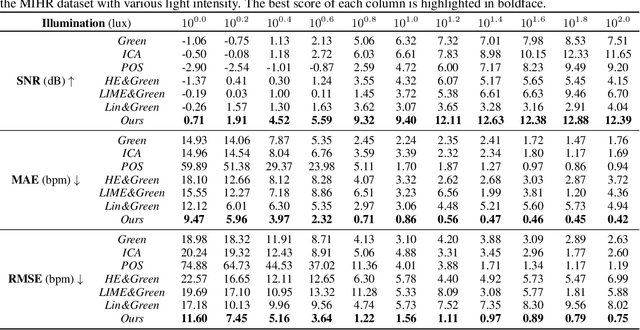
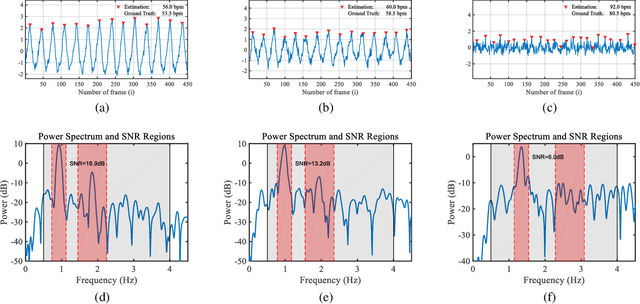
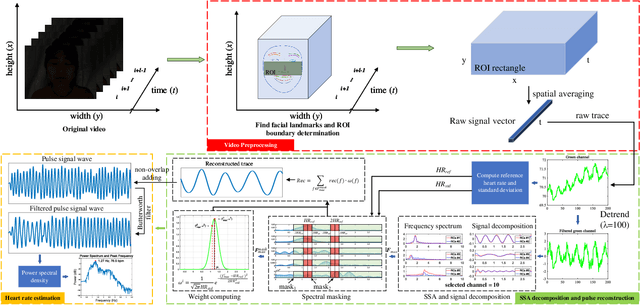
Camera-based vital signs monitoring in recent years has attracted more and more researchers and the results are promising. However, a few research works focus on heart rate extraction under extremely low illumination environments. In this paper, we propose a novel framework for remote heart rate estimation under low-light conditions. This method uses singular spectrum analysis (SSA) to decompose the filtered signal into several reconstructed components. A spectral masking algorithm is utilized to refine the preliminary candidate components on the basis of a reference heart rate. The contributive components are fused into the final pulse signal. To evaluate the performance of our framework in low-light conditions, the proposed approach is tested on a large-scale multi-illumination HR dataset (named MIHR). The test results verify that the proposed method has stronger robustness to low illumination than state-of-the-art methods, effectively improving the signal-to-noise ratio and heart rate estimation precision. We further perform experiments on the PUlse RatE detection (PURE) dataset which is recorded under normal light conditions to demonstrate the generalization of our method. The experiment results show that our method can stably detect pulse rate and achieve comparative results. The proposed method pioneers a new solution to the remote heart rate estimation in low-light conditions.
GameVLM: A Decision-making Framework for Robotic Task Planning Based on Visual Language Models and Zero-sum Games
May 22, 2024With their prominent scene understanding and reasoning capabilities, pre-trained visual-language models (VLMs) such as GPT-4V have attracted increasing attention in robotic task planning. Compared with traditional task planning strategies, VLMs are strong in multimodal information parsing and code generation and show remarkable efficiency. Although VLMs demonstrate great potential in robotic task planning, they suffer from challenges like hallucination, semantic complexity, and limited context. To handle such issues, this paper proposes a multi-agent framework, i.e., GameVLM, to enhance the decision-making process in robotic task planning. In this study, VLM-based decision and expert agents are presented to conduct the task planning. Specifically, decision agents are used to plan the task, and the expert agent is employed to evaluate these task plans. Zero-sum game theory is introduced to resolve inconsistencies among different agents and determine the optimal solution. Experimental results on real robots demonstrate the efficacy of the proposed framework, with an average success rate of 83.3%.
Simultaneous Deep Learning of Myocardium Segmentation and T2 Quantification for Acute Myocardial Infarction MRI
May 17, 2024



In cardiac Magnetic Resonance Imaging (MRI) analysis, simultaneous myocardial segmentation and T2 quantification are crucial for assessing myocardial pathologies. Existing methods often address these tasks separately, limiting their synergistic potential. To address this, we propose SQNet, a dual-task network integrating Transformer and Convolutional Neural Network (CNN) components. SQNet features a T2-refine fusion decoder for quantitative analysis, leveraging global features from the Transformer, and a segmentation decoder with multiple local region supervision for enhanced accuracy. A tight coupling module aligns and fuses CNN and Transformer branch features, enabling SQNet to focus on myocardium regions. Evaluation on healthy controls (HC) and acute myocardial infarction patients (AMI) demonstrates superior segmentation dice scores (89.3/89.2) compared to state-of-the-art methods (87.7/87.9). T2 quantification yields strong linear correlations (Pearson coefficients: 0.84/0.93) with label values for HC/AMI, indicating accurate mapping. Radiologist evaluations confirm SQNet's superior image quality scores (4.60/4.58 for segmentation, 4.32/4.42 for T2 quantification) over state-of-the-art methods (4.50/4.44 for segmentation, 3.59/4.37 for T2 quantification). SQNet thus offers accurate simultaneous segmentation and quantification, enhancing cardiac disease diagnosis, such as AMI.
CRS-FL: Conditional Random Sampling for Communication-Efficient and Privacy-Preserving Federated Learning
Jun 07, 2023Federated Learning (FL), a privacy-oriented distributed ML paradigm, is being gaining great interest in Internet of Things because of its capability to protect participants data privacy. Studies have been conducted to address challenges existing in standard FL, including communication efficiency and privacy-preserving. But they cannot achieve the goal of making a tradeoff between communication efficiency and model accuracy while guaranteeing privacy. This paper proposes a Conditional Random Sampling (CRS) method and implements it into the standard FL settings (CRS-FL) to tackle the above-mentioned challenges. CRS explores a stochastic coefficient based on Poisson sampling to achieve a higher probability of obtaining zero-gradient unbiasedly, and then decreases the communication overhead effectively without model accuracy degradation. Moreover, we dig out the relaxation Local Differential Privacy (LDP) guarantee conditions of CRS theoretically. Extensive experiment results indicate that (1) in communication efficiency, CRS-FL performs better than the existing methods in metric accuracy per transmission byte without model accuracy reduction in more than 7% sampling ratio (# sampling size / # model size); (2) in privacy-preserving, CRS-FL achieves no accuracy reduction compared with LDP baselines while holding the efficiency, even exceeding them in model accuracy under more sampling ratio conditions.
Multi-stage Progressive Reasoning for Dunhuang Murals Inpainting
May 10, 2023Dunhuang murals suffer from fading, breakage, surface brittleness and extensive peeling affected by prolonged environmental erosion. Image inpainting techniques are widely used in the field of digital mural inpainting. Generally speaking, for mural inpainting tasks with large area damage, it is challenging for any image inpainting method. In this paper, we design a multi-stage progressive reasoning network (MPR-Net) containing global to local receptive fields for murals inpainting. This network is capable of recursively inferring the damage boundary and progressively tightening the regional texture constraints. Moreover, to adaptively fuse plentiful information at various scales of murals, a multi-scale feature aggregation module (MFA) is designed to empower the capability to select the significant features. The execution of the model is similar to the process of a mural restorer (i.e., inpainting the structure of the damaged mural globally first and then adding the local texture details further). Our method has been evaluated through both qualitative and quantitative experiments, and the results demonstrate that it outperforms state-of-the-art image inpainting methods.
Image Enhancement for Remote Photoplethysmography in a Low-Light Environment
Mar 16, 2023


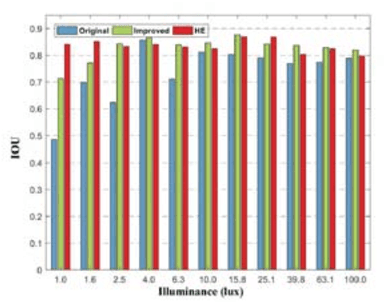
With the improvement of sensor technology and significant algorithmic advances, the accuracy of remote heart rate monitoring technology has been significantly improved. Despite of the significant algorithmic advances, the performance of rPPG algorithm can degrade in the long-term, high-intensity continuous work occurred in evenings or insufficient light environments. One of the main challenges is that the lost facial details and low contrast cause the failure of detection and tracking. Also, insufficient lighting in video capturing hurts the quality of physiological signal. In this paper, we collect a large-scale dataset that was designed for remote heart rate estimation recorded with various illumination variations to evaluate the performance of the rPPG algorithm (Green, ICA, and POS). We also propose a low-light enhancement solution (technical solution) for remote heart rate estimation under the low-light condition. Using collected dataset, we found 1) face detection algorithm cannot detect faces in video captured in low light conditions; 2) A decrease in the amplitude of the pulsatile signal will lead to the noise signal to be in the dominant position; and 3) the chrominance-based method suffers from the limitation in the assumption about skin-tone will not hold, and Green and ICA method receive less influence than POS in dark illuminance environment. The proposed solution for rPPG process is effective to detect and improve the signal-to-noise ratio and precision of the pulsatile signal.